
Les versions traditionnelles de RAG présentées dans les autres articles de cette série consacrée au sujet du même nom, adoptaient plus ou moins une trame séquentielle similaire. Après avoir étoffé cette trame avec des méthodes toujours plus riches les unes que les autres, la courbe de progression des RAG semble avoir atteint son asymptote. C’était sans compter sur l’introduction d’une méthode novatrice par Microsoft : le GraphRAG.
Vous n’avez pas encore lu le premier article de la série consacrée au RAG ? ?Découvrez notre article dédié au concept et au fonctionnement des RAG

L’innovation est la recherche constante d’améliorations de l’existant. C’est dans cette optique que le 13 février 2024, Microsoft publie un article de blog intitulé GraphRAG : Unlocking LLM discovery on narrative private data.
Cet article de blog – accompagné d’un article scientifique – présente une toute nouvelle stratégie pour faire du RAG qui s’écarte assez drastiquement de la voie classique tracée par la version naïve et empruntée par la version avancée.
Qu’est-ce qu’un GraphRAG Microsoft ?

Pour parfaitement comprendre la méthode employée, faisons un rapide détour par un pan des mathématiques appliquées au cœur du GraphRAG : les graphes de connaissances.
Les graphes de connaissances
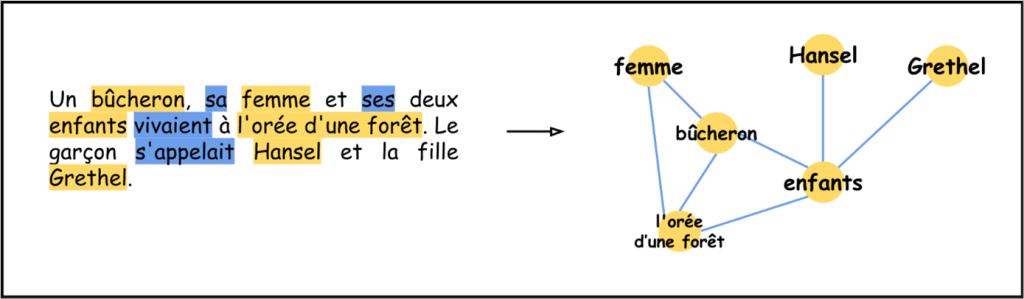
Les graphes de connaissances sont apparus dans les années 80, bien avant donc le premier LLM. En mathématiques, un graphe est simplement un ensemble de points – appelés nœuds – reliés entre eux par des traits – appelés arrêtes. Les arrêtes peuvent être orientées, c’est-à-dire que les traits deviennent des flèches qui ont une origine et une arrivée. Pour visualiser cela, il suffit de voir les nœuds comme des villes et les arrêtes comme les routes, dont certaines sont à sens unique. Il est donc possible de voyager d’un nœud à un autre s’il existe une arrête partant du nœud source allant vers le nœud cible.
Un graphe de connaissances est donc un graphe mathématique mais sur lequel on va donner du sens aux nœuds et aux arrêtes. Un nœud va représenter une entité du texte, c’est-à-dire un personnage, une date, un lieu, un évènement, etc. Deux nœuds sont reliés par une arrête si les deux entités sont en relation. Pour caricaturer : si l’une exerce une action sur l’autre.
Voilà où se situe l’idée originale de Microsoft : plutôt que de stocker du texte, l’indexation de ces derniers va se faire au moyen d’un graphe de connaissances rassemblant l’ensemble des entités trouvés.
Application au RAG
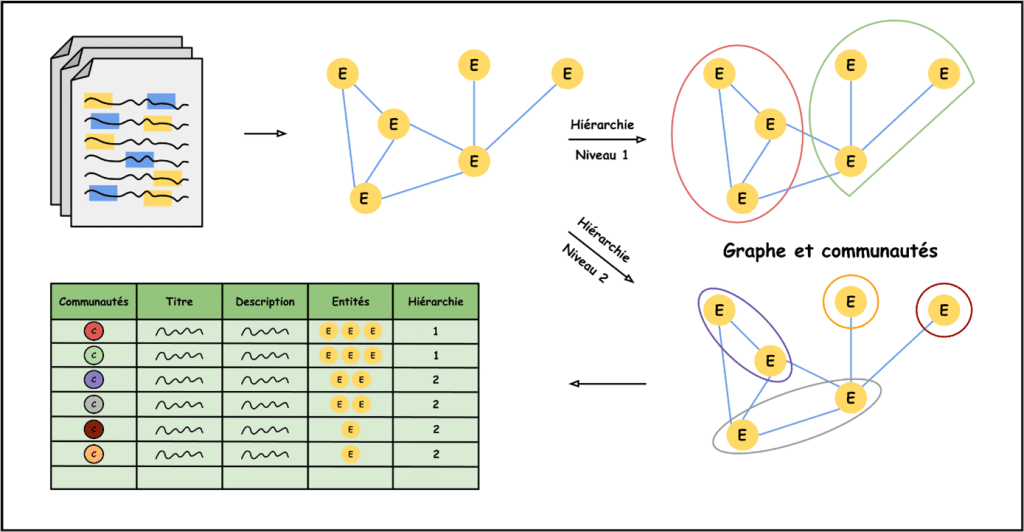
La première étape pour réaliser l’indexation de textes par graphe de connaissances consiste à extraire les entités et les relations entre les différents textes. À ce jeu-là, c’est encore les LLM qui nous sauvent. Il faut donc commencer par découper nos textes en chunks, puis donner ces chunks un par un à un LLM pour lui demander d’extraire les entités et les relations.
Une fois cette tâche effectuée, un travail de description des entités et des relations est réalisé, une nouvelle fois par LLM, en donnant à ce dernier la liste des entités et des relations présentes dans le chunk ainsi que dans le chunk associé. Ces descriptions nous serviront plus tard. Grâce à la liste recensant l’entièreté des entités et des relations présentes dans les textes, il est désormais possible de tracer le graphe de connaissances associé.
Pour pouvoir retrouver les entités pertinentes de manière efficace dans la phase de récupération, l’idée de Microsoft est de créer des grands groupes recensant des entités similaires. Ces grands groupes sont appelés communautés et sont des parties du graphe originel – l’ensemble des communautés forment une partition connexe du graphe pour les amoureux du détail.
Il ne reste alors plus qu’à choisir le nombre de communautés et les entités membres de chacune. L’idée, pour accomplir cette tâche, est d’attribuer des poids sur chaque arrête, correspondant aux nombres de relations trouvées entre les deux entités. De cette manière, on peut utiliser des algorithmes dit de « clustering » pour créer nos communautés. Généralement, un paramètre est associé à ce type d’algorithmes pour contrôler la propension à créer peu ou beaucoup de communautés.
Ce paramètre a beaucoup d’importance et permet de créer des communautés plus ou moins importantes, et donc plus ou moins spécifiques. Un ensemble de communautés associé à son paramètre de clustering est appelé une hiérarchie.
À ce stade, regardons ce que nous avons sous la main : un graphe de connaissances, des descriptions d’entités et de relations, et des groupes d’entités réparties selon diverses hiérarchies. La bonne idée – ou du moins celle proposée par Microsoft – c’est de demander à un LLM de décrire chaque communauté à partir des descriptions des entités et des relations qui la composent.
Que se passe-t-il après le graphe de connaissances ?
En effet, après avoir tracé le graphe de connaissances, partitionné ce graphe en communautés selon différents niveaux hiérarchiques et décrit chacune des communautés, nous avons simplement fini la première phase du RAG, c’est-à-dire celle d’indexation.
La phase de récupération
La phase de récupération est séparée selon le type de requête posée. La discrimination se fait selon deux classes : les requêtes locales et les requêtes globales. Ces deux types de requêtes sont associées à deux méthodes de récupération portant les mêmes noms de locales et globales. Les règles de décision pour déterminer quel type de méthode doit être appelé est une pratique qui prend le nom de « function calling ».
Les requêtes locales
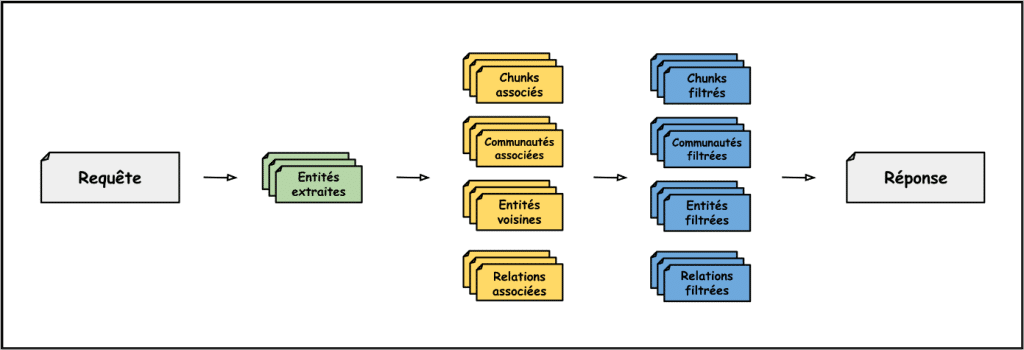
Les requêtes sont considérées locales lorsqu’elles appellent à récupérer une information précise ou une information concernant une ou un groupe restreint d’entités. Lorsque ce type de requête est envoyé par l’utilisateur, c’est la fonction de recherche locale qui est appelée. Cette recherche locale a pour précepte de partir des nœuds – donc des entités – pour ensuite récupérer de l’information. Lorsque la requête arrive, elle passe dans un LLM qui extrait les entités pertinentes et présentes dans le graphe.
Pour chacune des entités détectées dans la requête, on récupère ceci :
- Les chunks dans lesquels l’entité a été vue pendant la phase d’indexation ;
- Les descriptions des communautés – une par niveau hiérarchique – auxquelles l’entité appartient ;
- Les descriptions des entités reliées à l’entité extraite et la description de l’entité elle-même ;
- Les descriptions des relations partantes de l’entité extraite.
Toutes ces informations récupérées sont ensuite, au cours de la phase d’enrichissement, soumises à un système de filtres et de classements pour ajouter le plus d’informations pertinentes possibles tout en s’assurant de ne jamais dépasser la taille de la fenêtre du contexte.
Les requêtes globales
Les requêtes considérées comme globales sont celles qui demandent de raisonner sur plusieurs documents où l’on veut des informations générales. C’est le cas notamment lorsqu’on veut résumer un texte ou synthétiser les informations relatives à un thème contenues dans les documents. Lorsque ce type de requêtes arrive, c’est une fonction de recherche globale qui est appelée.
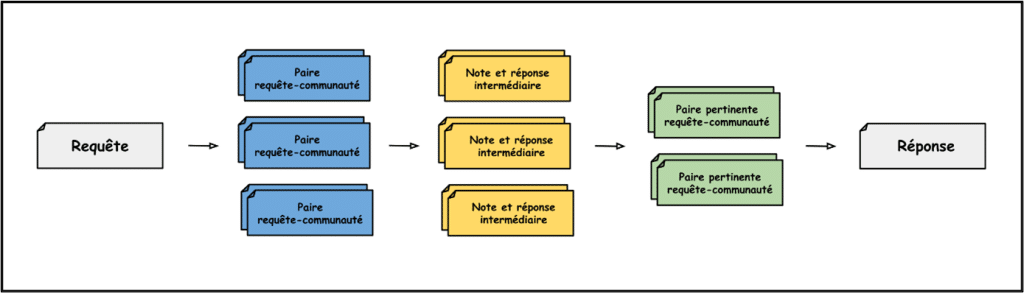
Cette fonction de recherche globale est en quelque sorte l’antithèse de sa sœur locale. En effet, l’idée principale est de partir des communautés pour redescendre jusqu’aux entités. Plus précisément, lorsque la requête arrive, on crée autant de paires requête-communauté que le nombre de communautés existantes pour le niveau hiérarchique prédéfini. Puis chacune de ces paires passe dans un LLM qui y associe une réponse intermédiaire et une note, sur 100, jugeant de la qualité de la réponse intermédiaire ainsi générée.
Les communautés appartenant à une paire requête-communauté ayant obtenu une note de 0 sont filtrées. Les autres sont classées selon leur note. Le contexte venant nourrir le LLM pour la génération de la réponse finale est donc la concaténation – en respectant les règles de prompt engineering bien sûr – de ces descriptions de communautés qu’on ajoute par notes décroissantes pour pouvoir s’arrêter lorsque la limite de la fenêtre de contexte est atteinte.
👉 Envie de mieux comprendre la réglementation autour de l’IA ? Découvrez notre article sur l’encadrement de l’intelligence artificielle dans l’Union Européenne grâce à l’IA Act : une analyse des enjeux et des impacts de cette régulation pour les entreprises.
Peut-on aller encore plus loin avec le GraphRAG ?
Avant de se demander s’il est possible d’aller plus loin, il faut tout d’abord se demander s’il est utile d’aller plus loin. En effet, peut-être que le GraphRAG résout tous nos problèmes et devient la méthode ultime et finale pour faire du RAG. Vous vous en doutez, si cette section existe, ce n’est pas le cas.
Comme évoqué précédemment, le GraphRAG de Microsoft a été développé dans l’optique d’améliorer les tâches de synthétisation. L’article publié montre, qu’en ce sens, le travail est réussi. En revanche, aucun mot sur les tâches plus classiques de RAG telles que retrouver des informations précises. En réalité, cette méthodologie GraphRAG apporte avec elle son lot de problèmes.
Le temps d’indexation
Si dérouler les chunks un par un pour les vectoriser est une tâche extrêmement rapide, extraire les entités, les relations, les décrire et les grouper prend du temps, beaucoup de temps. Le coût temporel de création du graphe est conséquent et ne permet donc pas une mise-à-jour rapide de la base de données associée.
La sensibilité aux modèles
La méthode GraphRAG requiert des appels LLM nombreux et par voie de conséquence est très sensible au modèle utilisé. Autant GPT-4 – estimé à 1 000 milliards de paramètres – excelle en extraction d’entités et de relations, autant des modèles plus petits – moins de 10 milliards de paramètres tout de même – peuvent assez rapidement perdre pied.
Or la phase d’indexation est très importante. C’est elle qui détermine la structure de nos données. Le problème est réglé, utilisons GPT-4 ! Oui, mais pas forcément. Vous n’êtes pas sans savoir qu’utiliser GPT est payant et qu’à 15$ le million de tokens de sortie, créer un graphe peut vite coûter cher. Au sein de la cellule innovation, le test a été réalisé sur environ 15 pages de texte et la création du graphe a coûté 5$ avec GPT-4 Turbo. Je vous laisse imaginer la même opération avec 1 000 pages et GPT-4.
👉 Envie d’en savoir davantage sur le coût de l’API GPT ?
Plus d’infos dans notre article « Comment estimer le coût de l’API ChatGPT ?«
Le temps d’inférence
À l’instar du RAG avancé, le GraphRAG peut rapidement devenir un outil orienté utilisateur inefficace. Pourquoi ? Parce qu’obtenir une réponse à une requête prend beaucoup de temps. Pour Microsoft et son armée de GPUs, passer en revue toutes les communautés une par une pour évaluer leur pertinence se compte en secondes. Pour n’importe quelle installation informatique de taille raisonnable, on parle de plusieurs minutes. Plusieurs minutes pendant lesquelles l’utilisateur doit attendre sans voir la première lettre s’afficher à l’écran.
GraphRAG : finalement, on en est où ?
Avec cette méthodologie GraphRAG, Microsoft a marqué de précieux points dans la course au RAG et a su redynamiser les recherches sur le sujet. En effet, cette méthode est prometteuse mais encore loin d’être parfaite. Et c’est finalement ça qui en fait son charme du moins pour les chercheurs.
De nombreux outils dédiés à l’extraction d’entités et à la création de graphes ont vu le jour à la suite de l’article de recherche sur le GraphRAG paru le 24 avril 2024, sans pour autant qu’un seul s’impose comme une réelle solution viable d’un point de vue commercial. Chez Meritis, au sein de la cellule Innovation, on a sauté sur l’occasion offerte par Microsoft pour se lancer dans l’aventure.
Pour découvrir les expériences menées sur les GraphRAG et la méthode de RAG made in Meritis, il faudra être patient et attendre la prochaine et dernière partie de cette série d’articles sur les RAG.
👉 Découvrez le dernier article de la série, et découvrez notre propre approche du GraphRAG !
« Une quête d’innovation, le Multi-GraphRAG by Meritis »
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.



Vos commentaires
Bonjour,
Excellent article. Merci.
Bien cordialement
Jean-Louis Lezaun