

Finalement, la Covid-19 aura-t-elle vraiment été le plus grand bouleversement de l’année 2020 ? De nouvelles intelligences artificielles (IA), dites génératives, ont commencé à proliférer dans notre société. Dans cet article, rédigé dans le cadre de la cellule innovation de Meritis (INnov), en collaboration avec Le Ha Vy Nguyen (MOE Node JS) et Julien Ageloux (Chef de projet innovation), nous explorerons comment estimer les coûts associés à l’API de la plus célèbre de ces IA génératives, ChatGPT
Généralement issues d’une souche commune – les transformers (une architecture de modèles profonds présentés en 2017) –, ces IA génératives reposent aussi sur un principe commun : produire automatiquement du contenu en réponse à une demande. Il existe aujourd’hui une multitude de variantes pour de multiples usages.
Les IA génératives : nouveau pharmakon ?
Pour ceux en quête d’inspiration artistique, les IA picturales comme Midjourney ou DALL-E sont capables de générer des images à partir d’une description fournie par un utilisateur. Pour ceux en quête de productivité, les IA textuelles ou Large Language Model (LLM) comme ChatGPT (OpenAI), LLama (Meta), BLOOM (BigScience) ou encore Bard (Google), sont capables de répondre à toutes les questions inimaginables… ou presque. Demain, qui sait quel autre besoin sera pourvu ?
?? Pour lire l’article qui « Présentation de ChatGPT par lui-même : tout comprendre de son fonctionnement et de ses limites« c’est par ici
Ces intelligences se multiplient (voir le graphe ci-dessous pour les seuls LLM), et avec elles, comme toute révolution, naissent de nouvelles controverses et questions :
- Quel avenir pour les emplois ?
- Qui détient la propriété intellectuelle du matériel généré ? 1, 2, 3, 4
- Quelle est la fiabilité de ces intelligences ? Et sont-elles vraiment intelligentes ?
Nombre de grands modèles de langages (créés chaque année) :
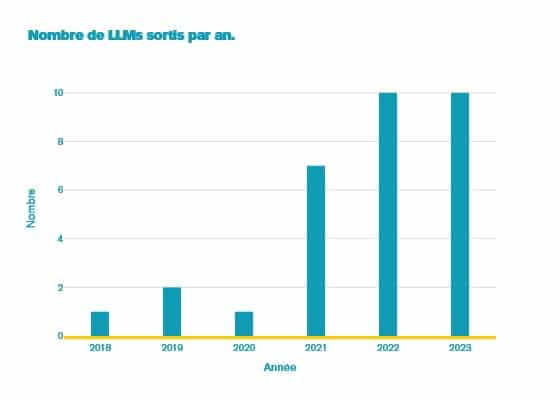
Peu affectés par ces problématiques, le grand public a déjà fait sien ces IA pour son confort personnel : génération de code, aide à la rédaction (voir notre article : « ChatGPT se présente par lui-même »), apprentissage… La mise à disposition de l’API OpenAI qui vise à pouvoir automatiser les interactions avec ChatGPT ouvre de nouveaux usages pour les entreprises. Dans cet article, nous proposons de regarder l’usage de cet API et les coûts associés.
Histoire et fonctionnement d’OpenAI API
Depuis mars 2023, OpenAI a ouvert une API donnant l’accès à ChatGPT et à ses LLM (GPT-3, GPT-4) de manière générale. Elle permet plusieurs services, notamment pour :
- Integer ChatGPT à d’autres applications ;
- Compléter du texte avec les modèles GPT ;
- Fine-tuner des modèles pour les rendre plus efficaces sur un besoin spécifique.
Les nouvelles perspectives générées par l’API OpenAI
Ces services ouvrent en effet de nouvelles perspectives. Par exemple : récupérer automatiquement des réponses de ChatGPT sur une tâche prédéfinie, répondre à des problématiques à partir d’un ensemble de documents ou encore intégrer des services internes en mode chat.
Pour faciliter l’intégration à d’autres API, le function calling est une feature récemment ajoutée qui donne la possibilité de décrire l’API (d’un point de vue fonctionnel) et les arguments qu’elle nécessite (cette fois-ci d’un point de vue technique).
ChatGPT est ensuite capable de choisir l’API et les arguments qui répondent au mieux à la demande, afin de préremplir l’appel technique nécessaire en vue d’obtenir la réponse attendue.

L’importance des prompts
Une notion très importante dans l’univers ChatGPT est celle des prompts. Ils prennent la forme d’une consigne rédigée qui oriente le modèle sur la nature de la tâche ainsi que le fond et la forme de la réponse attendue.
Un exemple de prompt peut être le suivant :
Résume le profil des principaux personnages de cette histoire, en conservant la langue originale.
Texte: « » »
{{INSERER UNE HISTOIRE ICI}}
« » »
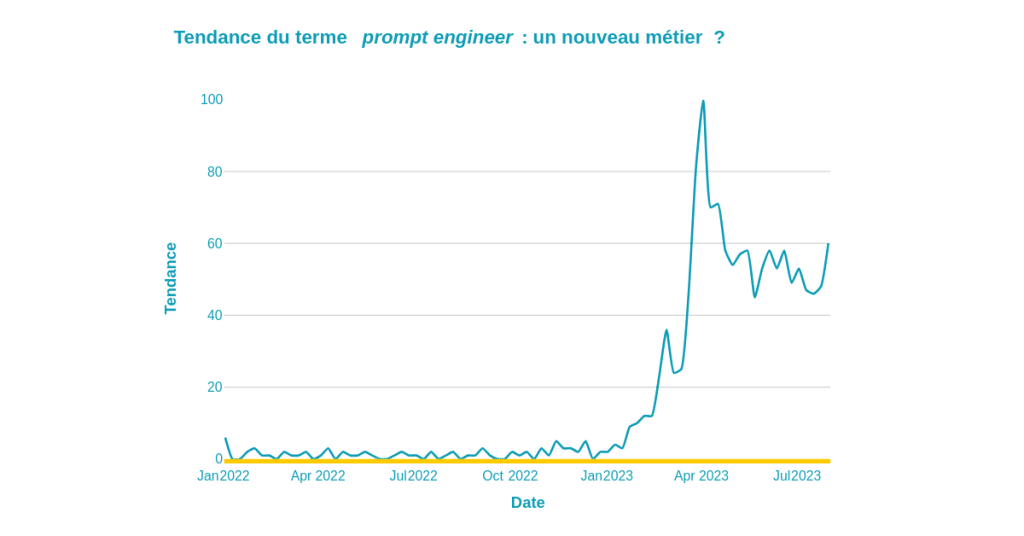
Ces prompts ont une importance capitale dans la qualité des réponses obtenues, à tel point que le métier de Prompt engineer s’est développé (voir l’évolution de la tendance ci-dessous). Ce métier consiste à créer des prompts pour tirer le maximum de précision des modèles génératifs.
Tendance d’un prompt sur ChatGPT
Les interactions techniques
Dans cet article, nous décrivons plus particulièrement le endpoint pour la tâche de chat completion. Ce endpoint consiste à générer une réponse à un dialogue envoyé par l’utilisateur.
Le dialogue décrit à la fois les répliques et les interlocuteurs (qui dit quoi) sous la forme d’un tableau json. Il comporte trois types d’interlocuteurs (des rôles) :
- system, un rôle optionnel visant à décrire le comportement de l’assistant et donner des instructions spécifiques à la tâche effectuée ;
- user, votre rôle, celui qui donne les requêtes et les données ;
- assistant, le rôle de ChatGPT qui fournit les réponses.
Un exemple de dialogue peut être le suivant :
[
{
« role »: « system »,
« message »: « Tu es un assistant qui résume des histoires en donnant le profil des personnages. Tu dois conserver la langue d’origine du document envoyé. »
},
{
« role »: « user »,
« message »: « {{INSERER UNE HISTOIRE}} »
}
]
Il peut être envoyé à l’API de complétion pour récupérer la réponse de ChatGPT à la demande.
D’autres paramètres peuvent être fournis à l’API pour mieux contrôler la génération comme la température (qui est reliée à l’aspect créatif du modèle), ainsi que le nombre de mots générés.
La facturation
L’API prend en considération trois aspects pour la facturation :
- Le modèle utilisé (GPT-3, GPT-4 ou les versions turbos) ;
- Le nombre de tokens envoyés au modèle via l’API, ou les prompts tokens ;
- Le nombre de tokens renvoyés par l’API, ou les completion tokens.
Nous définirons par la suite ce que sont les tokens et pourquoi ils sont utilisés. Pour l’instant, on peut faire l’approximation qu’un token est l’équivalent d’un mot. Le tableau ci-dessous donne les prix pour 1000 tokens (selon leur nature) facturés par OpenAI, à date d’écriture de l’article (août 2023). L’ensemble des prix peuvent être retrouvés ici et doivent servir de référence pour vos calculs :
| Modèle | Coût pour 1000 prompt token (USD) | Coût pour 1000 completion tokens (USD) |
| gpt-4-0613 | 0.03 | 0.06 |
| gpt-3.5-turbo-0613 | 0.0015 | 0.002 |
Comment compter les tokens
Une des problématiques majeures est de pouvoir anticiper précisément les coûts de l’API si, par exemple, on souhaite passer à l’échelle en utilisant massivement le modèle sur nos données. Avant de passer à la phase d’estimation des tokens, nous proposons une description de leur intérêt et leur méthode de calcul.
Les premières méthodes
Les machines ne sont pas capables de comprendre le texte naturellement. Elles savent très bien le lire, l’écrire ou le stocker, mais sont incapables de le comprendre.
La tokenization est une étape primordiale de traitement qui vise à décomposer le texte en de petites unités logiques, appelées tokens. À la base, les tokens étaient principalement des mots : les plus petites séquences de caractères porteuses d’un sens dans le langage.
Chaque mot était ensuite associé à une représentation mathématique (appelé word embedding) qui permettait des opérations logiques sur le langage. Ces word embeddings étaient appris sur un corpus d’entraînement (un très vaste ensemble de textes) comme aujourd’hui le sont les modèles d’OpenAI.
Cependant, ce modèle a vite montré des limites :
- Les mots nouveaux / inconnus à l’avance ne pouvaient pas être représentés faute de word embedding ;
- La taille du vocabulaire était très grande (plusieurs millions de mots) et rendait difficile l’apprentissage des embeddings ;
- Les mots rares ou les mots à déclinaison n’étaient pas très bien représentés car pas assez vus dans le corpus d’entraînement.
Les méthodes récentes
On a alors commencé à s’intéresser à ce qui se passe à l’intérieur des mots. Certains préfixes sont porteurs d’un sens en soi comme re en français (symbole d’une répétition), ou dé (symbole d’annulation du radical). Cependant, il n’est pas facile de trouver la bonne décomposition d’un mot en préfixe, radical, suffixe. Les premières méthodes faisaient par ailleurs omission de ces subtilités en considérant tous les sous-mots possibles.
Les méthodes actuelles font usage du même algorithme : le Byte Pair Encoding. Initialement conçu en 1994 pour compresser le texte, il s’avère très utile pour identifier les enchaînements de caractères les plus fréquents à partir d’un budget (le nombre maximum de tokens désiré).
Par exemple, si un préfixe est très fréquent dans le texte comme re ou pré, l’algorithme aura tendance à créer un token pour le préfixe. Pareil pour les suffixes et les radicaux. Comme ces éléments sont partagés par de nombreux mots, l’algorithme va facilement les identifier et sera ensuite capable de décomposer le texte via ces tokens. L’avantage est que cette méthode se généralise assez bien à des mots inconnus. La raison : il est possible de les décomposer via les tokens identifiés par l’algorithme.
À noter qu’il existe certaines limites. En se basant sur la fréquence et non sur le sens, tous les mots ne sont pas décomposés de façon logique. Cette interface web permet de voir la décomposition faite par l’algorithme sur du texte anglais, et de juger par soi-même de la qualité.
Estimation des tokens
Pour estimer le nombre de tokens, il existe deux manières :
- Approximative : on a la règle de 1 token = 0,75 mot ;
- Précise : utiliser le tokenizer pour calculer le nombre de mots.
OpenAI a partagé le package python tiktoken qui permet d’accéder aux tokenizers de ses différents modèles. On peut donc les utiliser pour estimer précisément le nombre de prompt tokens. Pour le nombre de completion tokens, on peut forcer un nombre maximum (et avoir une estimation dans le pire des cas).
Quelques méthodes en python utilisent ce package en vue d’estimer le coût de l’envoi d’un dialogue sur l’API.
Avant de passer à un modèle GPT d’OpenAI, le dialogue est transformé en un format s’appellant Chat Markup Language (ChatML). Les prompt tokens sont alors créés à partir du contenu du dialogue, pour la plupart, et des tags de ChatML. Ce format permet à la fois d’incorporer des méta-informations au chat (comme le rôle des utilisateurs), mais aussi d’éviter des attaques par injection (visant à contourner des filtres pour faire générer des contenus haineux comme expliqué dans cet article sur LinkedIn : Newly discovered « prompt injection » tactic threatens large language models).
Voici un exemple de conversion :
dialog:
{
{
« role »: « system »,
« message »: « Tu es un assistant qui répond à des questions. »
},
{
« role »: « user »,
« message »: « Qu’est ce que le ChatML? »
}
}
chatML:
« » »
<|im_start|>system
Tu es un assistant qui répond à des questions.<|im_end|>
<|im_start|>user
Qu’est ce que le ChatML?<|im_end|>
« » »
Par conséquent, pour calculer le nombre de prompts tokens, il faut convertir le dialogue en ChatML puis utiliser le tokenizer du modèle. Il faut donc utiliser tiktoken comme suit (en suivant la documentation d’OpenAI) :
tokenizer = tiktoken.encoding_for_model(« gpt-3.5-turbo-0613 »)
def num_prompt_tokens(messages: list[str]) -> int:
num_tokens = 0
for message in messages:
num_tokens += (
4 # every message follows <im_start>{role/name}\n{content}<im_end>\n
)
for key, value in message.items():
num_tokens += len(tokenizer.encode(value))
if key == « name »: # if there’s a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistant
return num_tokens
Ensuite, on estime le nombre de completion tokens en fournissant le nombre maximum de tokens attendus (ce nombre dépend donc directement du nombre d’appels fait à l’API) :
def num_completion_tokens(num_calls: int, max_tokens: int) -> int:
return num_calls * max_tokens
En combinant, on peut calculer le coût global comme suit à partir de l’objet dialogue décrit avant :
def compute_price_for_tokens(num_tokens: int, price: float):
return num_tokens / 1000 * price
def get_price_for_dialog(
dialog: list[dict[str, str]],
max_completion_tokens: int,
price_prompt_tokens: float,
price_completion_tokens: float,
) -> float:
price_for_prompt_tokens = compute_price_for_tokens(
num_prompt_tokens(dialog),
price_prompt_tokens,
)
price_for_completion_tokens = compute_price_for_tokens(
num_completion_tokens(1, max_completion_tokens),
price_prompt_tokens,
)
return {
« prompt_tokens_price »: price_for_prompt_tokens,
« completion_tokens_price »: price_for_completion_tokens,
« total »: price_for_prompt_tokens + price_for_completion_tokens
}
Exemple d’estimation des coûts de l’API ChatGPT
Pour un corpus contenant 12 000 échantillons, on a pu estimer les coûts suivants pour traiter l’intégralité des données (l’estimation est faite en août 2023) :
| Model | Price of prompt tokens (USD) | Price of completion tokens (USD) | Total (USD) |
| gpt-4-32k-0613 | 340.32 | 362.16 | 702.48 |
| gpt-4-0613 | 170.16 | 181.08 | 351.24 |
| gpt-3.5-turbo-16k-0613 | 17.02 | 12.07 | 29.09 |
| gpt-3.5-turbo-0613 | 8.51 | 6.04 | 14.55 |
Les derniers modèles (GPT-4) et ceux qui utilisent un contexte plus gros (16k / 32k) sont plus chers que les autres (pouvant aller jusqu’à un facteur 20). Cela s’explique par le fait que GPT-4 est vendu comme plus performant sur des tâches de réflexion que son petit frère GPT-3. À noter que selon vos besoins, le modèle 3.5 peut suffire.
Conclusion
Dans cet article, nous avons principalement abordé les aspects techniques et financiers de l’usage de l’API d’OpenAI. C’est une entrée en matière sur les possibilités de l’API et sur son utilisation. Nous fournissons aussi un snippet python qui permet facilement d’anticiper le coûts de vos appels.
L’API d’OpenAI est un premier pas vers la démocratisation et l’intégration des LLM dans les entreprises. En effet, les modèles LLM restent complexes à utiliser sur des besoins spécifiques et à fine-tuner (en particulier en raison de l’infrastructure requise et des compétences nécessaires).
Même si les modèles ont des défauts (voir notre article sur les huit principales limites de ChatGPT), ces derniers se perfectionnent très rapidement (voir l’évolution de Midjourney). C’est pourquoi, avoir pris le temps de réfléchir à l’intégration de ces outils pour des usages internes / externes pourrait faire une différence dans l’avenir.




Pas encore de commentaires