
La reconnaissance des émotions de la parole
Introduction au concept de la parole
Composée d’un ensemble de mots prononcés à haute voix, la parole est un flux audio continu qui peut être représenté comme un signal ou même une séquence d’images.
Comme le montre la figure ci-dessus, un flux audio se compose d’états stables et dynamiques. Par conséquent, nous pouvons définir des phonèmes comme des classes similaires de sons. Représentés par des consonnes ou des voyelles, ces phonèmes constituent une combinaison de la prononciation d’un mot.
En général, la représentation phonétique d’un mot peut prendre plusieurs formes selon le style de parole, l’orateur et l’accent utilisé. Par exemple, la prononciation anglaise britannique de certains termes diffère de celle de leurs homologues américains.
Parfois, les phonèmes simples ne suffisent pas à caractériser l’articulation d’un mot. Cela peut être résolu en combinant deux sons de parole (phonèmes) appelés diphonèmes. Par exemple, une des représentations phonétiques possibles du mot anglais « history » est formée en utilisant à la fois les phonèmes et les diphonèmes : HH IH S T ER IY. En outre, lorsque le besoin se fait sentir, on peut même parler d’un triphonème qui est la combinaison de trois phonèmes.
D’autre part, une pause entre les morceaux d’audio est appelée énonciation (« utterance ») et est habituellement détectée dans la parole à travers des charges (« fillers », c’est-à-dire des sons non linguistiques tels que um, toux, souffle, uh).
Choix du modèle
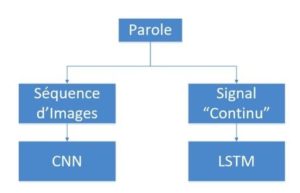
La reconnaissance des émotions de la parole vise à identifier l’état émotionnel de haut niveau d’un énoncé des caractéristiques de bas niveau. De ce fait, reconnaître les émotions de la parole est une tâche difficile car on peut exprimer les émotions de différentes façons. On peut donc traiter cela comme un problème de classification de séquences.
Au niveau des caractéristiques, plusieurs ont été étudiées pour implémenter des prototypes de reconnaissance des émotions de la parole. Par exemple, il existe des caractéristiques liées à l’énergie, les Mel-fréquences coefficients cepstraux (MFCC) ou même les coefficients de prédiction linéaire (LPC).
Ces caractéristiques sont utilisées avec des algorithmes d’apprentissage supervisé, tels que les Machines à Vecteurs de Support (SVM) pour essayer de classifier les émotions de la parole.
Ces approches nécessitent des caractéristiques délicates telles que des fonctions vocales, des caractéristiques énergétiques, de durée, de ton et d’autres choisies de manière empirique. C’est pourquoi, pour éviter de préparer manuellement ces caractéristiques, il est possible d’utiliser les réseaux de neurones profonds, et plus spécifiquement les CNNs, pour générer automatiquement ces caractéristiques de la parole (ou séquence d’images).
Les données consistant en un signal « continu », il faudra donc les traiter séquentiellement. Il est alors possible d’utiliser des réseaux de neurones récurrents (RNN) tels que les réseaux LSTMs (Long Short-Term Memory) qui ont montré de loin de meilleurs résultats dans le traitement des données séquentielles.
Conception du modèle
Le processus de reconnaissance des émotions à travers la parole s’effectue en 2 étapes :
a. Conversion au domaine fréquentiel
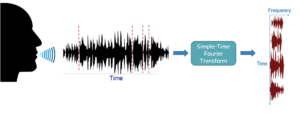
La première étape consiste à opérer une transformée de Fourier à court terme (Short-Time Fourier Transform – STFT) sur le flux audio afin de se placer dans le domaine des fréquences. On parle aussi du spectre du signal et des composantes spectrales qui ne sont pas directement visibles dans le domaine temporel. Ces composantes spectrales sont des éléments importants dans le processus d’apprentissage car elles fournissent des représentations des signaux sonores plus conformes à la perception humaine que celles du domaine temporel. (Pour plus d’informations sur l’algorithme : https://www.dsprelated.com/freebooks/sasp/Short_Time_Fourier_Transform.html )
En conséquence, nous devons convertir le signal par des morceaux d’audio au domaine des fréquences pour rendre ces composants perceptibles. Le flux d’un processus de conversion de la parole au domaine fréquentiel se fait en temps réel et inclut les étapes suivantes :
- Une forme d’onde acoustique est parlée dans le microphone.
- Séparé par des énoncés de silence, le signal sonore est divisé en petits morceaux pour un traitement plus précis.
- La transformation de Fourier simple (STFT) est utilisée pour convertir le morceau d’audio (du domaine temporel) en domaine fréquentiel. Cette dernière va nous retourner une matrice des fréquences d’échantillonnage qui sera ensuite transformée en une séquence de N images carrées.
b. Implémentation
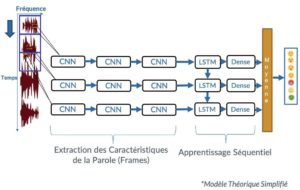
L’objectif de notre modèle est de pouvoir combiner un réseau profond de CNN qui nous permet d’extraire des caractéristiques pertinentes avec un autre réseau capable d’apprendre à reconnaître et à synthétiser séquentiellement le signal continu.
Par conséquent, notre réseau prend une séquence d’images (morceau d’audio) de longueur arbitraire M en entrée et prédit un vecteur fixe « y » de taille 7 en sortie (chaque attribut représente la distribution de l’une des 7 émotions universelles).
-
CNNs répartis dans le temps
Les réseaux de neurones convolutifs (CNN) nous permettent d’effectuer une transformation des caractéristiques visuelles d’un batch d’images qui est temporairement invariant et indépendant à chaque pas de temps. Par conséquent, cela rend l’inférence convolutive relativement parallèle sur toutes les étapes temporelles de l’entrée.
Plus spécifiquement, ayant une séquence de N images de taille (m x m) en entrée, on prend k images de la séquence, séparées par t pas de temps, et on alimente chacune d’elles à l’une des k séquences de CNN en entrée, de façon à pouvoir prédire une sortie pour chaque k images d’une séquence. Par exemple, pour 3 séquences de CNN en parallèle et pour t = 4 pas de temps, on alimente la 1re image à notre 1re séquence de CNN, ensuite la 5e image à la 2e séquence et la 9e à la 3e séquence, etc.
Comme l’illustre le modèle théorique, un bloc de CNN est composé de 3 couches cachées :
➢ Une couche de convolution
➢ Une couche d’activation ReLU
➢ Une couche de Max Pooling
(Pour information, ces 3 couches sont présentées dans la 1re partie de cet article : https://meritis.fr/ia/reconnaissance-des-emotions/)
En effet, et après plusieurs essais, les meilleurs résultats en termes de précision et d’optimisation ont été obtenus en concaténant n séquences en parallèle, dont chacune est composée de n blocs de CNN (format carré).
2.Réseau Long Short-Term Memory (LSTM)
2.1 Présentation du Réseau LSTM
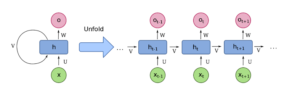
Il existe plusieurs cas d’usage dans lesquels on doit traiter séquentiellement nos données d’entrée afin d’améliorer la précision de prédiction de notre classifieur. De ce fait, l’intérêt des réseaux de neurones récurrents (RNN) est de pouvoir connecter les informations précédentes à la tâche actuelle, comme l’utilisation des images antérieures dans une séquence, dans le but d’éclairer la compréhension de la présente image.
En revanche, les réseaux de neurones récurrents simples sont incapables de stocker des contextes importants à long terme. Par conséquent, il est difficile d’apprendre les dépendances entre 2 données d’une séquence très éloignées dans le temps.
Afin d’adresser le problème de dépendance à long terme, un réseau de neurones récurrents, à plusieurs couches cachées, appelé « Long Short-Term Memory » (LSTM), a été proposé. Comme les RNNs simples, les LSTMs ont une structure en chaîne mais avec un module répétitif différent et plus profond.

Figure 1: Architecture d’un LSTM [1]
Notamment, on s’intéresse dans cette nouvelle architecture aux variables suivantes :
➢x_t: Le vecteur d’entrée au temps t
➢h_t: Le vecteur de sortie au temps t
➢c_t: Le vecteur d’état de la cellule (« cell state ») est introduit pour modéliser la mémoire à long terme au temps t
➢f_t: Le vecteur « Forget gate » représente les poids de se souvenir des anciennes informations au temps t
➢o_t: Le vecteur « Output gate » représente le candidat de sortie au temps t
➢i_t: Le vecteur « Input gate » représente les poids de l’acquisition de nouvelles informations au temps t
2.2 Intégration dans notre modèle
Dans un premier temps, on aplatit la sortie de la séquence des CNNs pour transformer la matrice en vecteur colonne.
Ensuite, ce nouveau vecteur est alimenté à une couche de LSTM composée de plus de 1 000 neurones pour apprendre les caractéristiques de CNN séquentiellement. Puis, on utilise une couche dense de 7 neurones suivie d’une couche Softmax afin de classifier les 7 émotions.
3. Sortie moyenne
La concaténation de 3 séquences de CNN avec les réseaux LSTM produit 3 sorties différentes. Par conséquent, on calcule la moyenne de ces 3 vecteurs pour obtenir une sortie finale représentant la distribution des émotions pendant une séquence d’images donnée.
Évaluation
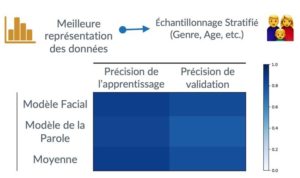
Notre base d’apprentissage (images et morceaux audio) est composée de plusieurs variables telles que le genre d’une personne, l’âge, la langue parlée, l’accent de la parole, etc.
Pour mieux représenter ces différents facteurs de nos données et baisser le biais du modèle, on se base sur l’échantillonnage stratifié.
Les résultats expérimentaux, présentés ci-dessus, démontrent que le modèle de reconnaissance des émotions à partir des expressions faciales est plus précis que celui de la parole et, également, plus rapide pour traiter une donnée en entrée. Pourquoi ? Parce que :
1. Le modèle de reconnaissance des émotions de la parole est plus profond et complexe que celui des émotions faciales.
2. Le modèle facial est appris avec beaucoup plus de données que celui de la parole.
Cas d’usage
On propose 3 cas d’usage dans le but de pouvoir améliorer les relations commerciales en agence :
a. Emotional Financial Marketing
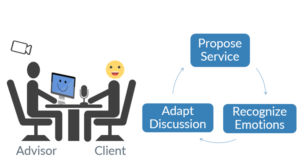
Dans un premier cas, l’utilisation d’un prototype intelligent lors d’une réunion en face-à-face entre un conseiller et son client peut aider le premier à adapter son discours en fonction des émotions du client.
Pour clarifier, nous avons un microphone placé devant le client et une caméra derrière le conseiller. Cela nous permettra de reconnaître les émotions que le client montre à travers ses expressions faciales et la parole.
b. Know Your Customer KYC
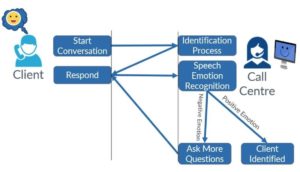
Les grands centres d’appels reçoivent des milliers d’appels par jour. Afin d’éviter les appels frauduleux, les agents des centres d’appels devraient pouvoir identifier le client avec lequel ils discutent.
C’est là que le concept de « Know Your Customer (KYC) » entre en jeu. En plaçant un système de reconnaissance des émotions de la parole du côté de l’agent, ce dernier serait capable de détecter les émotions que le client montre.
En conséquence, si les émotions reconnues sont positives (par exemple, calme / neutre, heureux, etc.), le client est identifié. Sinon (en cas d’émotions négatives, comme la peur, la surprise, etc.), l’agent peut poser d’autres questions pour analyser la réponse du client et s’assurer que c’est la vraie personne avec laquelle il parle.
En outre, un système de reconnaissance des émotions de la parole offre une meilleure précision que les détecteurs de mensonges traditionnels car il nous permet d’identifier l’état d’esprit de l’appelant.
c. Emotionally Responsive Advertising
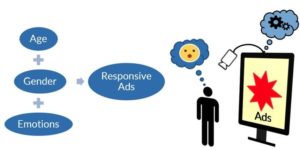
En combinant un système de reconnaissance des émotions faciales avec un classificateur d’âge et de genre, on peut présenter des panneaux d’affichage publicitaires émotionnellement réactifs.
Ce panneau d’affichage intelligent est équipé d’une caméra qui peut être utilisée pour reconnaître les émotions faciales, l’âge et le sexe de la personne (ou des personnes) se mettant devant le panneau. Par conséquent, selon le résultat retourné, une annonce spécifique qui cible ce groupe d’âge, de genre et des émotions est affichée en temps réel.
Conclusion
L’intelligence artificielle a déjà séduit un nombre important d’entreprises dans des domaines aussi divers que variés. Ce qui entraîne de nouvelles problématiques et de nouveaux défis pour les ingénieurs de demain. C’est pourquoi, il faut innover dans les méthodes d’apprentissage automatique mais principalement dans l’apprentissage profond, en plein essor et qui n’a pas fini de délivrer toutes ses possibilités. En conséquence, des formations commencent à émerger un peu partout dans le monde. Cependant, il existe encore des freins à son expansion liés à sa matière première : les données.
En effet, il existe dans certains pays, par exemple en France, tout un arsenal de lois et de réglementations encadrant l’exploitation des données.
Références
[1] Klaus Greff; Rupesh Kumar Srivastava; Jan Koutník; Bas R. Steunebrink; Jürgen Schmidhuber (2015). « LSTM: A Search Space Odyssey ». IEEE Transactions on Neural Networks and Learning Systems. 28 (10): 2222–2232. arXiv:1503.04069. doi:10.1109/TNNLS.2016.2582924. PMID 27411231.


Pas encore de commentaires