
Le machine learning a le vent en poupe actuellement. Charbel nous propose de découvrir comment on peut créer un réseau de neurones profond destiné à reconnaître les émotions à partir des images et du son d’une personne.
Depuis des siècles, les facteurs fondamentaux de la croissance économique ont été des innovations technologiques. Les plus importants d’entre eux sont ce qu’on appelle des technologies à usage général telles que la mécanisation et l’automatisation.
La technologie plurivalente la plus sérieuse de notre époque semble être l’intelligence artificielle, en particulier l’apprentissage automatique, c’est-à-dire la capacité de la machine à continuer d’améliorer ses performances sans que les humains ne doivent expliquer exactement comment accomplir toutes les tâches. Grâce à l’évolution rapide de ce domaine ces dernières années, on est aujourd’hui capable de créer des systèmes qui apprennent à effectuer des tâches complexes par eux-mêmes.
L’IA semble être en en mesure d’avoir un impact profond, à l’échelle des technologies existantes et limitées, particulièrement dans le domaine financier. Néanmoins, la plupart des grandes opportunités n’ont pas encore été exploitées.
Dans une optique d’innovation, je vous présente une validation de concept (PoC) d’un prototype de reconnaissance des émotions en temps réel, à travers les expressions faciales et la parole qui a pour objectif principal de s’intéresser à l’analyse des comportements humains sur la base de capteurs. Cela peut être très utile dans les relations commerciales où, en analysant ces comportements, on est en mesure de mesurer les effets qu’un service a sur un client et donc essayer de l’améliorer.
Ces effets se traduisent par des ’émotions qui varient surtout selon l’âge et le genre de la personne concernée. La problématique peut donc être abordée en développant un agent intelligent capable de reconnaître les émotions traduites par les expressions faciales ainsi que la parole, l’âge et le genre des clients de façon anonyme et en temps réel.
Définition Globale des Émotions
Les émotions sont des expériences conscientes caractérisées par une intense activité mentale et un degré élevé de plaisir ou de déplaisir. De plus, elles sont des états de sentiment qui entraînent des changements physiques et psychologiques qui influencent notre comportement.

Elles peuvent être classées en 7 catégories de base :
- La joie
- La tristesse
- La surprise
- La peur
- Le dégoût
- La colère
- L’indifférence
En parlant à d’autres personnes, nous avons tendance à montrer différentes émotions pour les aider à mieux comprendre ce que nous exprimons ou ressentons. C’est ce qu’on appelle la reconnaissance des émotions.

Intuitivement, le cerveau humain est capable de reconnaître les émotions en analysant des caractéristiques spécifiques telles que le langage corporel, les expressions faciales ou la tonalité de la parole.
Avec l’avancement en intelligence artificielle et l’apprentissage automatique, il y a eu diverses implémentations de prototypes de reconnaissance des émotions grâce à l’utilisation de différents algorithmes intelligents tels que la machine à vecteurs de support (SVM) ou l’Analyse des composantes principales (ACP).
Mais les résultats les plus marquants en termes de précision et de validation ont été atteints jusqu’à présent grâce à l’utilisation des réseaux de neurones profonds.
Architecture Globale
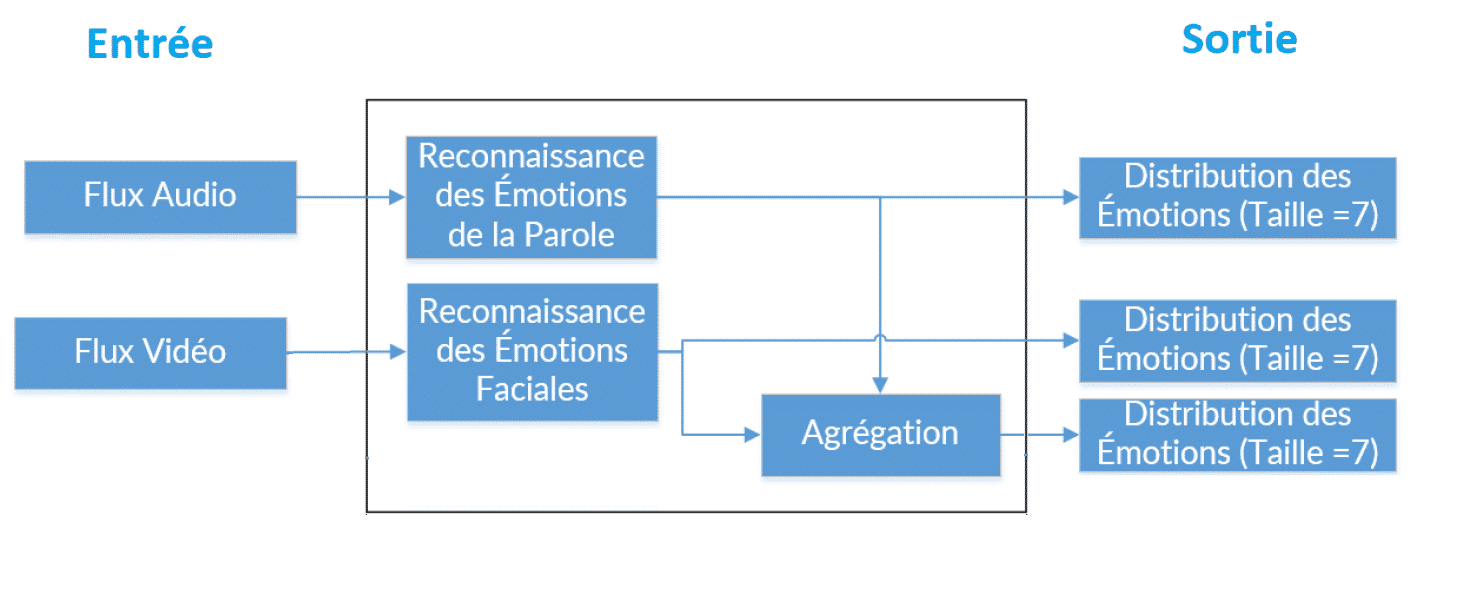
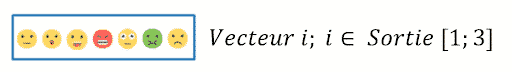
Le prototype présenté dans la figure ci-dessus cherche à reconnaître les émotions des personnes en temps réel, à travers un flux audio et vidéo. L’architecture globale repose sur 2 modèles :
- Un système de reconnaissance des émotions à travers les expressions faciales.
- Un système de reconnaissance des émotions à travers la parole.
Tout d’abord en entrée, un flux vidéo, à travers une caméra, alimente le modèle de reconnaissance des émotions faciales. De plus, un flux audio à travers un microphone est utilisé pour reconnaître les émotions de la parole.
En outre, on a 3 vecteurs en sortie de taille 7 représentant la distribution des émotions, dont le premier est renvoyé par le système de reconnaissance des émotions faciales et le deuxième par le modèle des émotions de la parole. En revanche, le dernier résultat est l’agrégation (moyenne) des 2 autres vecteurs qui pourrait servir selon le cas d’usage.
La Reconnaissance des Émotions à travers les Expressions Faciales

On s’intéresse à reconnaître les émotions à travers les expressions faciales en temps réel grâce à un flux vidéo en direct. Bien qu’un flux vidéo soit une séquence d’images avec un taux de fréquence prédéfini (par exemple, 40 images par seconde ou « Frames per Second (FPS) »), on prend la dernière image de chaque seconde et l’on détecte tous les visages de cette image.
Ensuite on fournit les visages recadrés à notre modèle CNN qui va renvoyer une étiquette d’émotion pour chaque visage en fonction des expressions qu’ils montrent.
C’est ainsi que notre architecture se compose de 2 parties :
- Dans un premier temps il faut préparer les données, plus précisément capturer l’image du flux vidéo et détecter les visages présents.
- Alimenter le réseau de neurones avec les données préparées.
Réseau de Neurones Convolutifs (CNN)
Un Réseau de neurones convolutifs (Convolutional Neural Networks ou CNN) est une classe des réseaux de neurones profonds conçue pour les applications de vision artificielle (Computer Vision) où les données traitées consistent principalement en des matrices à N-dimensions et dans notre cas des images.
De plus et contrairement à d’autres algorithmes de Machine Learning où on doit manuellement spécifier les caractéristiques qui sont importantes pour le processus d’apprentissage, le CNN le fait automatiquement grâce à ses couches cachées.
En outre, des résultats expérimentaux montrent que les modèles CNN offrent une précision et validation plus élevées que d’autres algorithmes en traitement d’images.
Représentation d’une image

Une image peut être représentée sous forme d’une matrice de pixels tridimensionnelle où les attributs correspondent à la longueur, largeur et profondeur de l’image. Par exemple, pour le système de couleur RGB, la profondeur est 3.
De ce fait, on peut considérer qu’une image est la concaténation de 3 matrices telle que chaque matrice spécifie la quantité de Rouge, Vert et Bleu qui constitue l’image.
Traitement et Préparation des Images
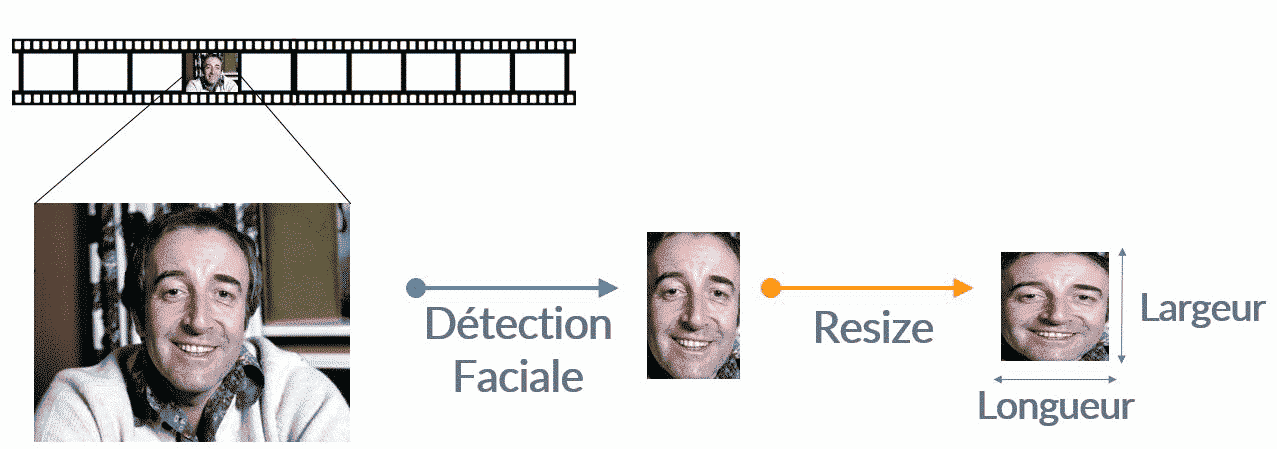
La couche d’entrée a des dimensions prédéterminées et fixes, de sorte que l’image doit être prétraitée avant qu’elle ne puisse être alimentée dans la couche. Pour l’étape de préparation des données, on capture la dernière image de chaque seconde du flux vidéo.
Puis, on utilise des techniques de détection faciale (non abordées dans cet article) qui contiennent des filtres appris et l’on se base sur des optimiseurs comme Adaboost pour trouver et découper rapidement les visages de cette image.
Et dans une dernière étape, on redimensionne les visages recadrés pour qu’elles deviennent des images carrées de taille (n x n x 3) pour un traitement plus simple.
Conception du Modèle
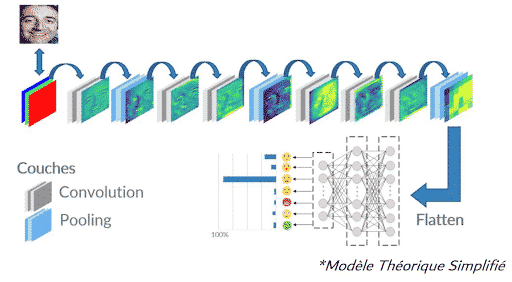
Après avoir préparé l’image, on propose le visage recadré à une première couche de convolution où il faut spécifier le nombre de filtres comme l’un des paramètres. L’ensemble des filtres sont uniques avec des poids aléatoires tel que chaque filtre glisse sur l’image d’entrée pour générer un « feature map » en sortie.
Couche(s) de Convolution
Le but principal d’une couche de convolution est d’extraire des caractéristiques (feature maps) de l’image en entrée. En fait, la convolution préserve la relation spatiale entre les pixels, en apprenant des caractéristiques d’image, en réduisant le nombre de paramètres libres et améliorant la généralisation.
En effet, la couche de convolution contient plusieurs filtres apprenants, qui sont des petites fenêtres ou matrice 2D, qu’on glisse sur notre matrice d’entrée pour calculer le produit scalaire entre cette dernière et les valeurs du filtre concerné. En sortie, une matrice contenant des caractéristiques spécifiques appelée « feature map » est générée pour chaque filtre.
Rectified Linear Unit (ReLU)
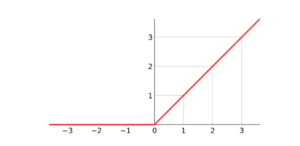
Il est important d’appliquer une couche non linéaire (ou couche d’activation) immédiatement après une couche de convolution. Le but de cette couche est d’introduire la non-linéarité dans un système qui vient tout juste de calculer des opérations linéaires.
Par conséquent, on choisit d’utiliser les couches ReLU parce que le réseau peut apprendre beaucoup plus rapidement qu’avec d’autres fonctions, telle que la tangente hyperbolique «tanh», (en raison de l’efficacité de calcul) sans faire une grande différence de la précision.
La couche ReLU applique la fonction f (x) = max (0, x) à toutes les valeurs du volume d’entrée. Plus précisément, cette couche met à 0 toutes les activations négatives.
Couche(s) de Pooling
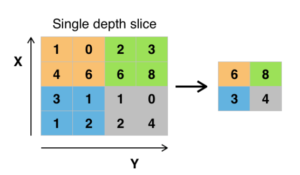
Pooling est une technique de réduction de dimension appliquée habituellement après une ou plusieurs couches de convolution qui conserve les informations les plus importantes. Il existe plusieurs types de pooling : Max, Moyenne, Somme, etc.
Par exemple, dans le cas du Max pooling, on définit une fenêtre glissante de taille mxm et on prend le plus grand élément du feature map dans cette fenêtre.
Couche(s) Dense(s)
La couche dense s’inspire de la façon dont les neurones transmettent des signaux par le cerveau, telle que tous les neurones d’une couche sont totalement connectés à toutes les activations dans la couche précédente.
En effet, les poids d’une couche dense sont appris par une passe avant (forward propagation) des données d’apprentissage et puis par une passe arrière (back propagation) de ses erreurs. Cette dernière commence par évaluer la différence entre la prédiction et la sortie désirée et puis ajuste des poids, nécessaire à chaque couche préalable.
Cependant, la complexité de l’architecture et la vitesse d’apprentissage dépendent de plusieurs paramètres comme le taux d’apprentissage (learning rate) et la densité du réseau.
Sortie Softmax
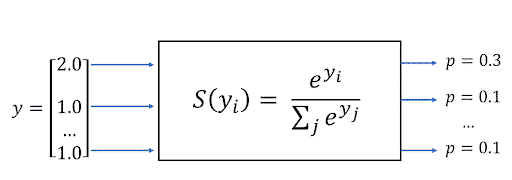
On utilise une couche de Softmax pour transformer des scores logistiques calculés dans la couche dense en une distribution probabiliste en sortie. Cette sortie n’est pas uniforme ou proportionnelle. En fait, la couche Softmax est exponentielle et peut élargir les différences. Par exemple, cette fonction peut rapprocher la probabilité d’un résultat de 1 et d’un autre de 0.
Par conséquent, le modèle est capable de montrer la distribution de probabilité des émotions faciales.
Conclusion
Dans cette première partie, j’ai présenté la mise en œuvre théorique d’un système intelligent de reconnaissance des émotions par détection faciale, à l’aide des techniques d’apprentissage profond. En conséquence, dans un prochain article, je parlerai d’un système plus complexe impliquant la reconnaissance des émotions de la parole et vous présenterai des cas d’usage réels pouvant contribuer à l’amélioration des relations commerciales.


Vos commentaires
« Je trouve ce projet très intéressant et j’aimerais le réaliser en tant que projet de fin d’année. »