
Les LLM occupent, depuis quelques années, une place centrale dans nos vies et dans la manière dont nous travaillons en entreprise. Les performances des modèles utilisés semblent même s’améliorer sans cesse. Mais cette amélioration n’a rien de magique : elle est liée à une augmentation continue de la taille des modèles. En conséquence, ceux-ci deviennent plus chers, plus lents, et nécessitent des infrastructures de plus en plus importantes pour pouvoir être exécutés. D’où l’intérêt de la quantification des LLM, technique qui permet de réduire considérablement la taille des modèles sans pour autant trop dégrader leurs performances.
Quels sont les grands principes de la quantification ? Pourquoi cette technique joue-t-elle un rôle clé dans la performance et le déploiement des modèles d’IA ? En quoi peut-elle influencer les choix stratégiques de votre organisation ? Autant de questions auxquelles nous tentons de répondre dans cet article.
Principes de base d’un LLM
Avant de parler de quantification, il semble important de rappeler quelques principes clés des LLM.
Un LLM est un modèle de grande taille (large model) capable de comprendre, de manipuler et de générer du langage humain (language model).
NB : vous trouverez sur ce blog plusieurs articles traitant du sujet du fonctionnement de ChatGPT ou des transformers (la technologie à la base des modèles de langage actuels).
Pour comprendre cet article, il suffit de savoir qu’un modèle de langage est un type de réseau de neurones.
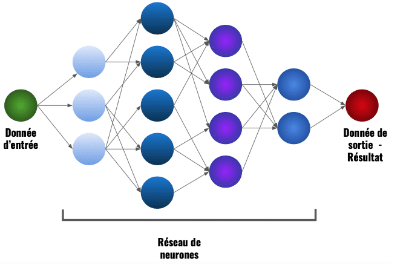
Schéma d’un réseau de neurones [1]
Dans ce schéma, vous pouvez voir qu’un réseau de neurones est un système qui prend une entrée, la fait passer par plusieurs couches de neurones (ici, 4 couches) et produit une sortie.
À chaque neurone est associé un paramètre appelé « poids ». Lorsque la donnée d’entrée passe par les différentes couches, elle subit des opérations avec ses poids (par exemple des multiplications), ce qui permet d’obtenir une sortie.
Un LLM est donc un très gros réseau de neurones, pouvant contenir des centaines de couches et des milliards de paramètres. Il prend en entrée un texte et produit en sortie une réponse.
Il est également essentiel de distinguer deux phases dans la vie d’un modèle de langage :
- La première est la phase d’entraînement, durant laquelle on montre au modèle des milliards de pages de texte et on met peu à peu à jour les valeurs de ses poids afin qu’il apprenne à formuler des réponses cohérentes
- La seconde est la phase d’utilisation (on parle aussi de phase d’inférence).
Pourquoi vouloir des modèles plus petits ?
Vous l’aurez compris, les performances remarquables des modèles de langage actuels sont rendues possibles par leur taille gigantesque.
Mais leur immensité pose plusieurs problèmes. Tout d’abord, la phase d’entraînement d’un modèle est d’autant plus longue et coûteuse qu’il est volumineux. En effet, plus un modèle est gros, plus il faut de GPU pour l’entraîner et de temps pour mettre à jour tous ses poids durant l’entraînement (un GPU est une puce informatique qui permet de paralléliser de nombreux calculs. Ces puces sont indispensables pour entraîner et utiliser de gros réseaux de neurones comme les modèles de langage).
Il en va de même pour la phase d’utilisation. Pour exécuter un modèle en local (c’est-à-dire sur sa propre machine), une infrastructure suffisante est nécessaire. Pour vous donner un exemple : le modèle DeepSeek-R1 contient 671 milliards de paramètres et pèse environ 720 GB. Pour pouvoir l’exécuter chez soi, il faut près de 300 000 euros de matériel (et un coût écologique tout aussi élevé).
On comprend donc aisément pourquoi il est si important de rendre les modèles de langage plus légers, que ce soit pour ceux qui les fabriquent ou pour ceux qui les utilisent. C’est là qu’intervient la quantification des LLM.
NB : pour discuter avec un modèle sur votre navigateur, vous avez juste besoin d’une connexion internet. Le modèle est alors exécuté à distance, ce qui signifie que vous déléguez les calculs au fournisseur.
Principes de la quantification
Le volume d’un modèle (en Gb) est proportionnel à son nombre de paramètres et à l’espace mémoire alloué à chaque paramètre. Or, la réduction du nombre de paramètres d’un modèle s’accompagne presque systématiquement d’une baisse des performances. L’autre idée pour diminuer le volume d’un modèle vient alors tout naturellement : si on ne peut pas diminuer son nombre de paramètres, il faut réduire l’espace mémoire alloué à chaque paramètre. C’est le principe de la quantification.
Les différentes façons de stocker un nombre et l’espace mémoire requis
En informatique, un nombre est stocké sous forme de bits, composés de 0 et de 1. Plus on alloue de bits au stockage d’un nombre, plus on peut représenter de valeurs différentes et précises (avec beaucoup de chiffres après la virgule).
Un LLM étant un réseau de neurones, le stocker revient donc à stocker l’ensemble de ses poids, c’est-à-dire un ensemble de nombres qui déterminent son comportement. Il faut alors décider combien de bits on alloue à chacun de ces nombres. Par exemple, si on les stocke en 16 bits au lieu de 32 bits, ils peuvent prendre beaucoup moins de valeurs différentes. Ces valeurs sont plus « grossières », mais on divise le volume de ce modèle par 2.
Quantification des LLM
Vous l’aurez compris, la quantification d’un LLM consiste à réduire la précision de ses poids afin qu’ils occupent moins d’espace mémoire et que le modèle soit plus léger.
En pratique, on peut vouloir quantifier un LLM, soit pour réduire les coûts d’entraînement, soit pour accélérer et faciliter son inférence. Les méthodes utilisées dans les deux cas ne sont pas les mêmes.
Faciliter l’inférence
Dans cette sous-partie, nous allons nous concentrer sur les techniques visant à rendre un modèle plus léger lors de sa phase d’utilisation. À la clé : la capacité à réduire la taille mémoire du modèle, à accélérer son inférence, à diminuer sa consommation énergétique et à réduire les coûts d’utilisation.
a) Quantification post-entraînement (PTQ)
La première idée qui vient à l’esprit (et aussi la plus naturelle) est la suivante : on entraîne un modèle en précision maximale (en stockant ses poids sur 32 bits), puis on le quantifie après la phase d’entraînement, juste avant de le déployer. C’est le principe de la quantification post-entraînement.
Pour mieux comprendre, cela revient à entraîner le modèle avec des poids très précis (beaucoup de chiffres après la virgule) pour être sûr qu’il apprenne à être vraiment « intelligent », puis à « arrondir » tous ces poids au moment de l’utiliser.
Par exemple, si on entraîne un modèle en 32 bits puis qu’on le quantifie en 8 bits, on réduit sa taille par 4, sans constater une trop grosse baisse de performance. Pour revenir à l’exemple de DeepSeek-R1, il existe une version fortement quantifiée dont le poids est d’environ 130 Gb. Cette version peut tourner sur un hardware coûtant « seulement » environ 50 000 euros.
Cette méthode peut cependant interroger : si on se donne tant de mal à entraîner le modèle avec une grande précision, comment se fait-il que ses performances restent à peu près les mêmes lorsqu’on le quantifie ? Cette perte de précision sur des milliards de paramètres ne devrait-elle pas se traduire par une baisse des capacités du modèle ?
Les réponses à ces questions sont multiples et très complexes, mais on peut tout de même retenir deux éléments :
- Primo, c’est justement parce que le modèle contient autant de poids que la plupart de ses valeurs individuelles importent peu. Ce qui compte, c’est la structure globale du modèle. Elle n’est pas vraiment affectée par de petites variations des valeurs des poids car celles-ci se compensent au niveau macroscopique.
- Secondo, la nature même d’un LLM ne requiert pas une précision absolue. Nous l’avons dit plus tôt : un LLM prend en entrée un texte (votre prompt par exemple) et renvoie une réponse.
En réalité, sa réponse est générée mot par mot, de façon itérative : à chaque itération, il choisit le mot qu’il juge le plus probable. Les valeurs exactes de ces probabilités importent peu : ce sont leurs valeurs relatives qui déterminent le mot choisi à chaque itération.
De plus, il n’existe pas de bonne réponse unique : lorsque le LLM choisit le mot suivant, le mot qu’il considère comme le 5e le plus probable n’est pas forcément beaucoup moins pertinent que le premier. Ainsi, même si les valeurs des probabilités de sortie sont légèrement modifiées (par exemple parce qu’on a perdu de la précision lors de la quantification du modèle), la qualité de la réponse finale ne sera pas forcément fortement affectée.
b) Entraînement conscient de la quantification (QAT)
Nous venons de voir une première méthode qui consiste à entraîner le modèle en précision maximale, puis à le quantifier juste avant l’utilisation.
Cette méthode est pratique et très utilisée, mais elle n’est plus suffisante si l’on veut une quantification plus importante. En effet, les performances du modèle restent à peu près les mêmes si on quantifie sur 8 bits, mais elles chutent si on veut descendre davantage en précision (par exemple en quantifiant sur 4 bits).
Pour quantifier le modèle au maximum, on ne peut plus l’entraîner comme si de rien n’était, puis le quantifier au dernier moment. Il faut adapter la phase d’entraînement : c’est le principe de l’entraînement conscient de la quantification (Quantization-aware training sonne peut-être mieux en anglais…).
Le but de cette technique est d’exposer le modèle à des valeurs fortement quantifiées plus tôt que pendant la phase d’inférence.
Pour comprendre cette technique, il est nécessaire de connaître, dans les grandes lignes, comment un LLM est entraîné. Le principe est simple : on lui fournit un texte, on lui fait générer une réponse, puis on met à jour ses poids, plus ou moins, en fonction de l’écart entre sa réponse et la réponse attendue. La phase où il prédit une réponse est la forward pass, la phase de mise à jour des poids est la backward pass. Ces deux phases sont répétées sur des milliards de textes.
Lors d’un entraînement conscient de la quantification, la forward pass est effectuée avec des poids quantifiés et la backward pass est effectuée avec une précision maximale.
Concrètement, les poids du modèle sont stockés avec une précision maximale (par exemple, en 32 bits). À chaque fois qu’on lui fait faire une prédiction, on fait une copie de ses poids, on les quantifie avec la précision souhaitée et on réalise la prédiction à partir de ces valeurs quantifiées. Ensuite, la mise à jour des poids (backward pass) s’effectue sur la version originale du modèle avec une précision maximale. La copie du modèle quantifiée utilisée pour la forward pass est recalculée à chaque itération.
Une fois l’entraînement terminé, on quantifie le modèle avant de le déployer.
L’avantage de cette méthode est que le modèle apprend très tôt à effectuer des prédictions avec des poids fortement quantifiés.
En pratique, l’entraînement conscient de la quantification ne représente souvent qu’une petite partie de l’entraînement global (10 % par exemple). Le reste de l’entraînement est effectué avec une précision maximale.
Réduire les coûts d’entraînement
DeepSeek-V3 aurait été entraîné pour environ 6 millions de dollars, contre plusieurs dizaines de millions pour les plus gros modèles américains. Comment expliquer ces écarts de coûts pour des modèles aux performances similaires ?
Il est important de comprendre que les deux méthodes que nous avons présentées jusqu’ici permettent de réduire les coûts d’inférence mais pas ceux d’entraînement. Si l’on applique une quantification post-entraînement, la phase d’entraînement reste inchangée.
Pour ce qui est de l’entraînement conscient de la quantification (QAT), la plupart de l’entraînement se fait en précision maximale, à laquelle on ajoute une phase d’entraînement supplémentaire, ce qui peut rendre l’entraînement total encore plus coûteux.
Dans cette deuxième sous-partie, nous allons donc nous attaquer à un deuxième objectif : comment utiliser la quantification pour réduire les coûts d’entraînement des modèles ?
De même qu’on quantifie le modèle final pour limiter les coûts d’inférence, il est possible d’entraîner directement un modèle quantifié pour limiter les coûts d’entraînement : on parle d’entraînement entièrement quantifié (FQT).
Quelles différences entre l’entraînement conscient de la quantification et l’entraînement entièrement quantifié ?
J’aimerais insister sur une distinction qui peut prêter à confusion, à savoir celle entre le QAT (entraînement conscient de la quantification) et le FQT :
- D’abord, ces deux méthodes n’ont pas le même objectif : réduire les coûts d’inférence ou les coûts d’entraînement.
- Ensuite, leur principe diffère. Souvenez-vous : dans le QAT, seule la forward pass est réalisée avec des poids quantifiés, et ce pour seulement 10 % de l’entraînement. Dans le FQT, la backward pass (mise à jour des poids) est aussi effectuée avec une précision réduite, et ce, tout au long de l’entraînement.
Nous avons vu ensemble que la prédiction d’un LLM ne requiert pas une précision absolue, ce qui justifiait la conservation des performances même après la quantification du modèle. En revanche, obtenir un modèle performant alors que ses poids sont mis à jour de façon « grossière » (quantifiée) pendant l’entraînement n’a rien d’évident.
Voyons ensemble certains éléments qui expliquent comment des entreprises y parviennent de façon remarquable.
En premier lieu, parler d’entraînement entièrement quantifié est un abus. Il serait plus juste de parler d’entraînement en précision mixte. En effet, les poids d’un LLM n’ont pas tous la même sensibilité au bruit. On quantifie donc uniquement ceux qui sont peu impactés (la très grande majorité des poids). Les autres poids plus sensibles sont laissés en précision maximale. Le hardware utilisé pour entraîner les modèles (GPU) est optimisé pour permettre cet entraînement en précision mixte.
De plus, les choix faits concernant le format de stockage des poids sont très importants. Il faut bien comprendre que quand on alloue 4 bits au stockage d’un nombre, celui-ci ne peut prendre que 16 valeurs différentes. Mais selon le format choisi, ces 16 valeurs peuvent comporter plus ou moins de chiffres après la virgule, être plus ou moins proches, etc. Par exemple, lors de la backward pass, on a besoin de couvrir une plage de valeurs étendue pour adapter correctement la modification des poids du modèle en fonction de la qualité de sa prédiction. Il faut donc choisir des formats astucieux et bien adaptés à ce qu’on veut faire.
Performances des modèles quantifiés
Vous l’aurez compris, l’atout des modèles quantifiés réside dans leur taille. Ces modèles sont plus faciles à charger, plus rapides, consomment moins de ressources et peuvent tourner sur du matériel moins coûteux. Mais, par définition, la quantification s’accompagne d’une baisse de précision. Celle-ci peut être quasiment imperceptible ou bien rendre le modèle inutilisable si la quantification est poussée à l’extrême.
Afin de choisir le modèle à déployer chez soi, une bonne compréhension du compromis entre la taille et la performance s’impose.
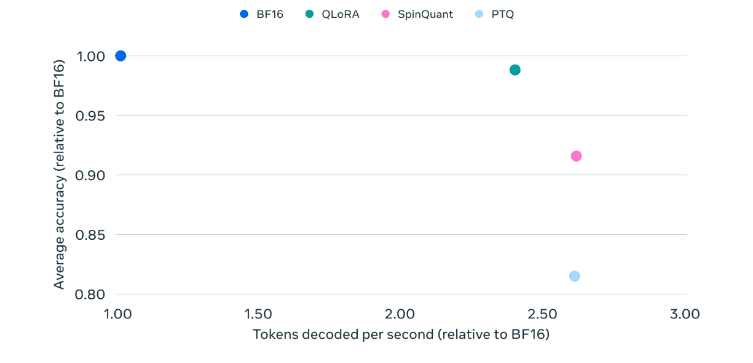
Variations des performances de Llama-3.2 1B en fonction de sa quantification [2]
Sur ce graphique, on peut voir l’évolution de la qualité des réponses (en ordonnée) et de la vitesse (en abscisse) du modèle Llama-3.2 1B (un petit modèle open source d’un milliard de paramètres proposé par Meta) pour différents types de quantification.
On voit, par exemple, que la PTQ (quantification post-entraînement) permet d’obtenir un modèle 2,5 fois plus rapide, mais dont la qualité des réponses se dégrade de 20 %. Les deux autres méthodes de quantification sont plus complexes, mais permettent d’obtenir les mêmes gains de vitesse sans affecter sensiblement la qualité des réponses.
Au final, tout l’enjeu consiste à bien comprendre et maîtriser le compromis entre la taille du modèle, la vitesse d’exécution et le niveau de quantification, afin d’obtenir le meilleur équilibre entre performance et efficacité.
Conclusion
Dans cet article, j’ai essayé de vous présenter quelques idées clés à l’origine du principe de quantification des LLM.
En pratique, certaines entreprises publient directement les versions quantifiées de leurs modèles. D’autres publient des versions à la plus haute précision, qui sont ensuite quantifiées par la communauté open source.
Dans tous les cas, la quantification s’impose aujourd’hui comme une technique incontournable, au cœur des efforts visant à rendre les LLM plus efficaces et accessibles.
Sources
[1] : inside-machinelearning.com
[2] : medium.com
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.




Pas encore de commentaires