
Que celui qui n’a jamais dit : « c’est bon, j’suis sûr que ça passe, on testera en prod sinon », lève la main. La tentation est grande, mais hélas, trois fois hélas, ça ne finit généralement pas par un happy end.
Étape incontournable de tout développement informatique, la phase de tests informatiques a pour objectif de vérifier que le livrable répond bien aux besoins exprimés par l’utilisateur. On s’attachera particulièrement à s’assurer que l’outil mis à disposition est utilisable, et ce, facilement, de manière pérenne, sans erreur, et produit ce pour quoi il a été construit dans un délai de réponse acceptable.
Bien que son utilité soit essentielle, la phase de test se trouve, hélas, souvent prise en otage suite aux retards accumulés par le projet et sert de variable d’ajustement pour tenir les délais. En pratique, il s’agira donc non pas d’établir que le système fonctionne correctement dans tous les cas, mais plutôt de détecter que tel ou tel élément ne fonctionne pas comme prévu sous certaines conditions. Après avoir parcouru les grands types et phases de tests possibles, la seconde partie sera dédiée au partage de bonnes pratiques afin de mener cette chasse au bug le plus efficacement possible.
Un petit détour par la théorie
Il convient dans un premier temps de distinguer les niveaux de tests et les types de tests. Puiser dans le domaine du possible nous donne déjà des éléments pour bien structurer les tests et s’assurer de leur exhaustivité, en fonction du contexte du projet.
Quatre grands niveaux de tests peuvent être dégagés :
-
Les tests unitaires : ils visent à vérifier la fonctionnalité d’une section particulière du code, indépendamment les unes des autres. On identifiera donc potentiellement un défaut à un endroit précis.
-
Les tests d’intégration : une fois les tests unitaires effectués, il s’agit ici de tester le système au global, c’est-à-dire en intégrant tous ses composants. Deux variantes sont envisageables, en mode composant par composant ou en mode « big bang ».
-
Les tests système : le but de cette phase est de vérifier que le développement fonctionne correctement en théorie, mais également dans le contexte donné par l’utilisateur.
-
Les tests d’acceptation qui cherchent à faire valider le développement entre différentes équipes du projet (MOE => MOA) puis auprès des utilisateurs.
À l’intérieur de ces différents niveaux se trouvent les différents types de tests. On pourra citer pour les plus courants :
-
Smoke test and sanity check, les préliminaires. Ils consistent à chercher rapidement des bugs critiques dans les fonctionnalités majeures du développement. Pas besoin de poursuivre les tests si ces étapes ne sont pas concluantes… Non, vraiment, je préfère que tu revoies ton code avant qu’on aille plus loin !
-
Les tests de non-régression. Ceux-ci valent surtout pour les évolutions de logiciels déjà installés, le but étant de vérifier que ce qui est livré n’entraîne aucune instabilité ou ne fasse pas resurgir d’anciens bugs morts et enterrés. S’entend à la fois pour le logiciel lui-même ou une partie du système d’information si celui-ci interagit avec d’autres composants.
-
Les tests fonctionnels et non fonctionnels. Si les tests fonctionnels parlent d’eux-mêmes (est-ce que l’utilisateur peut faire ou ceci ou cela ?), les tests non fonctionnels sont des vérifications techniques liées à la performance, l’adaptabilité ou à la sécurité du système.
-
Le End-to-End testing : il consiste à simuler des tests à plus grande échelle, en intégrant un nombre important d’éléments, de systèmes différents pour valider l’alimentation successive de bout en bout. En finance, il est usuel de tester la chaîne « Front to Back », c’est-à-dire depuis les systèmes en lien avec les marchés/les clients jusqu’aux outils de valorisation ou de génération de confirmation automatique par exemple.
Et en pratique ça donne quoi ?
De la nécessité d’avoir une stratégie et un plan de tests dès la phase d’élaboration
Idéalement, on devrait construire les cas de tests fonctionnels au fur et à mesure des spécifications. Ceci permet par exemple de confirmer le comportement attendu par l’utilisateur en réfléchissant aux multiples cas possibles. Les cas de tests pourront servir en outre à illustrer les spécifications en fournissant des exemples, utiles à la fois pour le développeur, mais aussi pour l’utilisateur. Une portion non négligeable des bugs étant causée par des incompréhensions (Users/MOA ou MOA/MOE), on aurait tort de ne pas privilégier une bonne communication dès les premières phases.
A fortiori, l’utilisation de tests chiffrés permet de dégager les cas extrêmes ou limites. Si un calcul nécessite par exemple le prix d’exécution, que se passe-t-il si celui-ci est négatif ? Dois-je prévoir un garde-fou s’il est nul ? On se garde ainsi le risque de se poser ces questions dans les phases suivantes, où le coût de correction de bugs peut être plus élevé (surtout en gestion cycle en V, moins en Agile).
En ce sens, les méthodes dites de « continuous testing » (Test Driven Development, Behaviour Driven Development), qui combinent à la fois coding et tests automatiques dans le processus de construction, accordent un sacré avantage : détection immédiate de bugs en testant simultanément les parties techniques et fonctionnelles. C’est du temps de gagné, et le temps, c’est de l’argent.
L’importance de la planification
Il est judicieux de coordonner les phases de tests sous un double aspect : le découpage et la budgétisation des divers tests d’une part, la planification des ressources de l’autre.
Les différentes phases de tests s’imbriquant les unes aux autres, on ne peut donc pas passer à une phase sans avoir validé la précédente, cela va sans dire. Pas de End-to-End testing avant les smoke tests, s’écria le Maréchal La Palice ! Mais plus précisément, il conviendra de prêter une attention toute particulière à l’enchaînement de ces tests ainsi qu’à leurs durées respectives. Exercice ô combien ardu, tant l’estimation de la charge, propre à chaque projet, est difficile. Un événement imprévu n’étant jamais à exclure, la détection d’un problème peut parfois en faire émerger bien d’autres, plus nombreux et plus graves à corriger. Le petit bug se transforme alors subitement en fourmilière, où bien d’autres petites bêtes attendent bien sagement, tapies dans l’ombre, prêtes à surgir dès la découverte de l’une d’entre elles. Afin d’éviter tout impact sur les phases suivantes et sur la date de mise en production, il est fortement conseillé de se donner une marge d’environ 10% sur la charge totale prévue, histoire d’être confortable si un élément inattendu venait à se mettre dans le chemin critique.
En complément de ces éléments, il est essentiel de s’assurer de la disponibilité des équipes extérieures au projet qui ont un rôle à jouer dans les phases de tests. Ce peut être l’équipe de testeurs dédiée, les développeurs de l’extracteur qui doivent fournir les données à un moment T, éventuellement les fournisseurs externes (ex : market data Reuters / Bloomberg), ou toute autre partie prenante au process nécessaire et aboutir à la validation finale. La phase de tests peut tout aussi bien être décalée ou échouer pour des raisons organisationnelles, et pas seulement du fait du développement.
Aucun test tu ne négligeras
Que celui qui n’a jamais dit : « c’est bon, j’suis sûr que ça passe, on testera en prod sinon », lève la main. La tentation est grande, mais hélas, trois fois hélas, ça ne finit généralement pas par un happy end. Les quelques moments gagnés ici ne pèseront pas bien lourd face au temps perdu à s’expliquer face aux utilisateurs, à corriger, à tester (avec une énorme minutie cette fois) et à livrer à nouveau.
Au-delà des tests fonctionnels obligatoires, on pourra également accorder un soin tout particulier à certains tests techniques, jugés, à tort, comme superflus ou accessoires, mais tout aussi importants.
Par exemple, la performance ou la « scability ». Super, on a livré et jusqu’ici pas d’erreur ! En revanche, le système rame dès que 3 utilisateurs y sont connectés en même temps, mais ça marche ! C’est aussi inutilisable qu’un système totalement buggé.
Il en va de même pour tous les tests liés à la sécurité, sujet de plus en plus important ces derniers temps. Au risque financier que cela peut entraîner, vient s’ajouter le risque d’image de voir, par exemple, son fichier client exposé sur la place publique (cf. Sony, Ashley Madison, etc.).
Autres types de tests un peu plus accessoires, mais qui témoigneront de la robustesse du développement, les tests dits parfois « de destruction » visent à simuler un comportement incohérent d’un utilisateur. Prenons l’exemple d’un « pricer » de produits financiers. Que se passe-t-il si je saisis du texte au niveau du champ quantité ? J’ai la capacité de renseigner éventuellement une autre date d’expiration d’une option que celle proposée, mais puis-je envoyer, en mode fou furieux, une demande de quote si la date choisie tombe un week-end ou un jour férié ? Aurai-je en retour l’écran bleu de la mort ou un prix tellement incohérent qui risque de déstabiliser l’ensemble du système bancaire et financier mondial ? L’histoire nous enseigne que c’est lors d’une phase de test de ce type que la centrale de Tchernobyl a explosé, il a bien sûr des limites à ce mode « déglingo ».
De l’optimisation, du recyclage et du suivi des cas de tests
L’idée est de tester le plus de cas possible avec un minimum de cas de tests. Or qui dit cas de tests dit jeu de données construites et injectées dans la base de données de l’outil. Cela peut s’avérer en définitive fastidieux et très consommateur de temps pour tout le monde si on les multiplie.
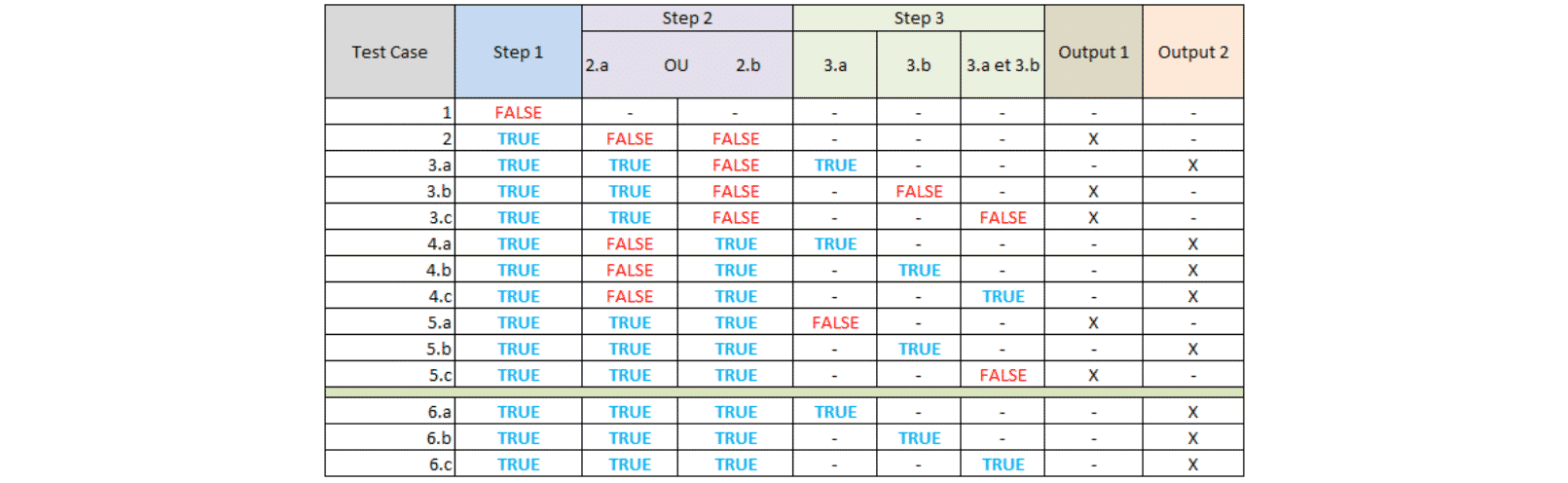
Pour illustrer l’optimisation possible des tests à effectuer, prenons l’exemple du développement suivant :
- Le process contient 3 étapes pour aboutir à trois résultats : END, Output 1 ou Output 2. Une étape (step) est caractérisée par une action (ex : click) ou une condition spécifique (ex : Prix demandé > x),
- Si Step 1 est TRUE => Step 2 ; Else END,
- Step 2 intègre une double condition non paramétrable (OU ne peut être modifié),
Si Step 2.a ou Step 2.b est TRUE => Step 3 ; Else Output 1, - Step 3 vérifie une seule condition à la fois (3.a, 3.b) ou les deux en même temps, Paramétrable,
Si Step 3 est TRUE => Output 2 ; Else Output 1.
Le tableau suivant propose une combinaison possible de la manière de construire son cahier de tests. On détaillera dans un premier temps les cas possibles pour ensuite construire son jeu de données en fonction. Pas de tests superflus ou en doublon ici, et on pourra se limiter à 6 voire 5 cas (le dernier cas est déjà un peu superflu et peut ne pas être joué).
Jouer les cas de tests n’est pas tout, il est également important d’en garder une trace. Au lieu d’écraser violemment le méchant bug avec le talon de sa chaussure dès que l’occasion se présente, on peut tout autant essayer de le décrire, de l’observer avec précision. Ceci présente deux avantages : on pourra rejouer ce cas de tests dans les mêmes conditions pour les évolutions futures, idéal pour les campagnes de non-régression. L’autre utilité est de pouvoir construire ou enrichir son backlog, réserve de fonctionnalités à développer ou correctifs à appliquer par la suite. Toujours embêtant lorsqu’on le découvre, un bug est aussi l’occasion de s’améliorer.


Vos commentaires
Bravo Christophe : je suis d’accord avec toi sur l’importance de cette phase trop souvent laissée à côté par manque de temps, organisation ou paresse. Par contre, en tant que développeur, une marge de 10% sur la charge prévue pour les tests me semble un peu juste (mais je demanderais plus a priori 😉
J’aurais aimé t’avoir comme testeur de mes devs…
…ah tiens…
Merci pour cette première analyse très complète