
Dans un premier article consacré à Apache Hive, nous avions présenté son architecture, ses concepts de bases et quelques fonctionnalités. Dans ce deuxième article, nous allons désormais présenter comment Hive s’appuie sur MapReduce pour faciliter l’analyse et la manipulation de gros volumes de données avec des concepts très proches du monde relationnel : tri, jointure, buckets et fonctions prédéfinies (UDF).

Quelques principes de base dans MapReduce
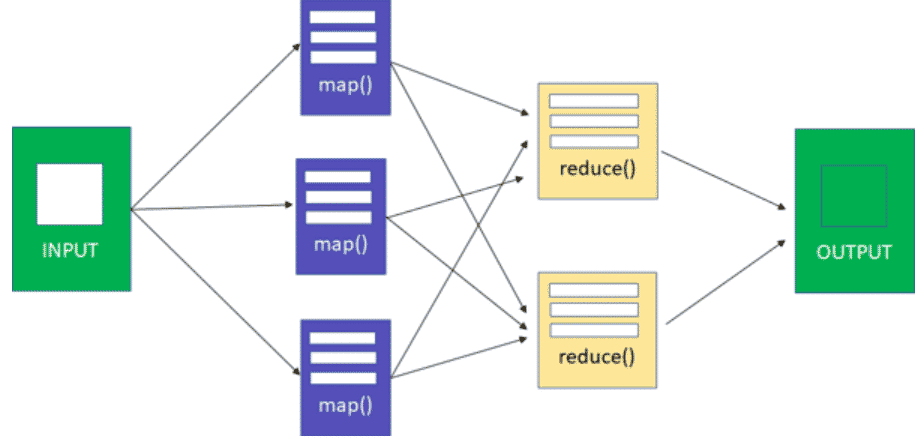
Pour comprendre certains concepts dans Hive, il est bon de rappeler en premier lieu à quoi correspondent les notions de mapper et de reducer, deux concepts clés dans MapReduce. Il fait suit à mon précédent article sur Hive.
- Mapper :dans cette phase, il s’agit d’effectuer des traitements parallèles sur l’ensemble de données d’entrée. Chaque ‘‘worker node’’ applique une fonction ‘’map’’ sur les données locales. La sortie est produite dans un stockage temporaire.
- Reducer :chaque noeud effectue le traitement de chaque groupe de données de sortie (produites dans la phase de map), par clé, en parallèle.
Concepts d’organisation des données dans Hive
Le partionnement
Hive peut organiser les tables en partitions pour regrouper le même type de données en fonction d’une colonne (ou d’une clé de partition). Chaque table peut avoir une ou plusieurs clés de partition pour identifier une partition particulière. En utilisant le partitionnement, Hive permet d’accélérer les requêtes sur des tranches de données.
L’inconvénient d’avoir trop de partitions est le grand nombre de fichiers et de répertoires Hadoop créés inutilement. Ces derniers peuvent surcharger le NameNode qui doit conserver toutes les métadonnées du système de fichiers en mémoire.
Les Buckets
Pour pallier le problème de sur-partitionnement, Hive a introduit le concept de Bucketing. Il s’agit d’une technique d’organisation des données en parties plus petites appelées ‘‘buckets’’. Dans ce concept, la table possède une structure spécifique basée sur une fonction de hachage qui s’applique sur une colonne donnée. Ceci impose aussi la façon avec laquelle les fichiers sous-jacents sont stockés. En effet, les données ayant la même bucket-colonne seront toujours dans le même bucket (cf. Figure 2).
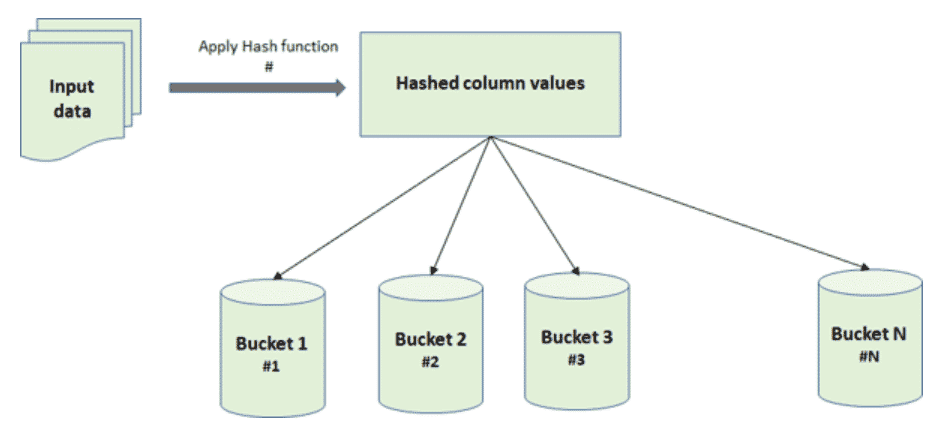
Physiquement, chaque bucket correspond à un fichier dans le répertoire de la table. Le bucketing peut être effectué sur des tables partitionnées ou non partitionnées. Il permet de créer une distribution homogène de fichiers en termes de taille.
Le bucketing peut servir comme technique d’optimisation de requêtes. En effet, il permet de faire des jointures efficaces lorsque la clé de jointure correspond à la colonne de clustering. Il permet aussi de rendre plus efficace l’échantillonnage de données puisqu’il s’agit de manipuler des ensembles de données plus petits.
Les buckets sont créés en utilisant le mot clé CLUSTERED BY. Par exemple, la syntaxe ci-dessous permet de créer une table product_bucketed avec 24 buckets en se basant sur la colonne id comme colonne de clustering (cf. Figure 3).

Figure 3: Commande HiveQL pour la création d’une table product_bucketed divisée en 24 buckets.
Voici ce que nous pouvons retenir :
- Une table dans Hive peut être partionnée et organisée en buckets.
- Une partition correspond à un répertoire alors qu’un un bucket correspond à un fichier.
- Le sur-partionnement peut générer un volume important de métadonnées ce qui peut surcharger le namenode et affecter la performance des requêtes.
Le Skew (ou Skewed table)
Pour rendre l’interrogation des données plus efficace, Hive a introduit la notion de ‘‘skew’’ et de ‘‘skewed table’’. Un skew fait référence à une (ou plusieurs) colonne(s) d’une table. Cette colonne a la particularité d’avoir des valeurs très récurrentes, d’où l’intérêt de les regrouper dans un ‘‘skew’’.
En spécifiant, au moment de la création de la table, les valeurs sur lesquelles porte le skew, Hive va automatiquement gérer chacune d’entre elles dans un fichier séparé. Ainsi, des fichiers entiers peuvent être ignorés pendant les requêtes.

Les clauses de tri et de distribution
Le tri:
Le tri de données s’effectue dans Hive avec l’une des deux clauses : ORDER BY et SORT BY. La syntaxe des deux clauses est similaire (cf. Figure 5). Cependant, leur fonctionnement est différent :
ORDER BY
Elle assure un ordre complet, toutes les données sont envoyées à un seul reducer sur lequel l’opération de tri sera réalisée. Son inconvénient : non scalable sur de gros datasets. Pour cette raison, il est recommandé d’ajouter la clause LIMIT dans la requête. Ceci est indispensable pour limiter la taille de données en sortie afin de permettre le traitement par un seul reducer.
SORT BY
Elle assure un ordre partiel en effectuant un tri au niveau de chaque reducer.
Donc, la clause ORDER BY est utilisable dans des environnements de développement et de prototypage mais fortement déconseillée en production puisqu’elle est non scalable sur des grands volumes de données.

Gestion et optimisation de la distribution:
Il est possible dans Hive d’optimiser la distribution de données sur l’ensemble des reducers (quand leur nombre est >1). Ceci est fait en utilisant le mot clé ‘‘DISTRIBUTE BY’’. Dans notre exemple avec le code pays, les données avec le même pays d’origine vont être traitées par le même reducer (Cf. Figure 6).
Cependant, cette clause ne garantit aucune forme de clustering : les données seront renvoyées au même reducer mais peuvent être non adjacentes. Pour les grouper et forcer les données à être adjacentes, il faut ajouter une clause SORT BY.
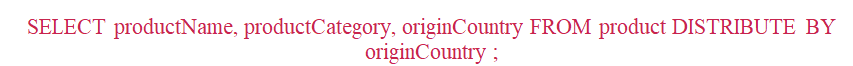
Les jointures dans Hive:
Plusieurs stratégies de jointure existent dans Hive : Shuffle join, Map join (appelé également broadcast join) et SMB join.
- Map Join:
Ce type de jointure est optimisé et efficace. Il est idéal si une des deux parties participantes est suffisamment petite pour être chargée en mémoire. En revanche, plusieurs conditions doivent être réunies pour pouvoir le réaliser.
- SMB Join:
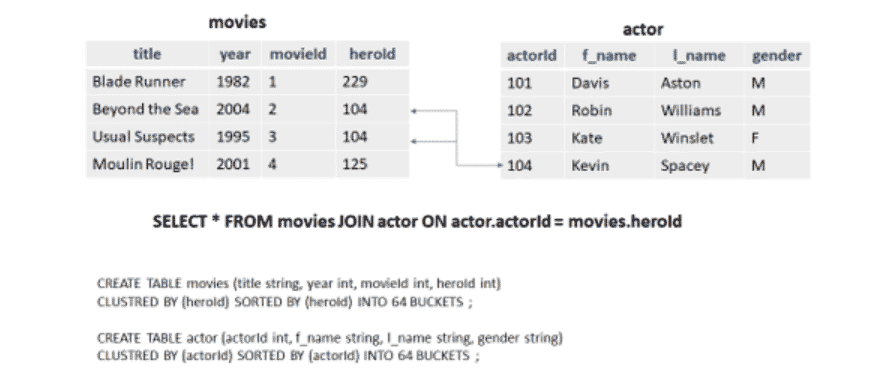
C’est la stratégie qui se base sur le hash bucketing pour pouvoir ramener toutes les données correspondantes à la clé de hachage (qui n’est autre que la clé de jointure dans ce cas) pour pouvoir les traiter au niveau d’un seul nœud.
- Shuffle join
C’est la stratégie utilisée s’il n’est pas possible d’effectuer un autre type de jointure plus efficace.
Nous allons détailler à travers des exemples ces trois types de jointure. Nous regroupons aussi dans la table ci-dessous (Cf. Table 1) les différences entre elles.
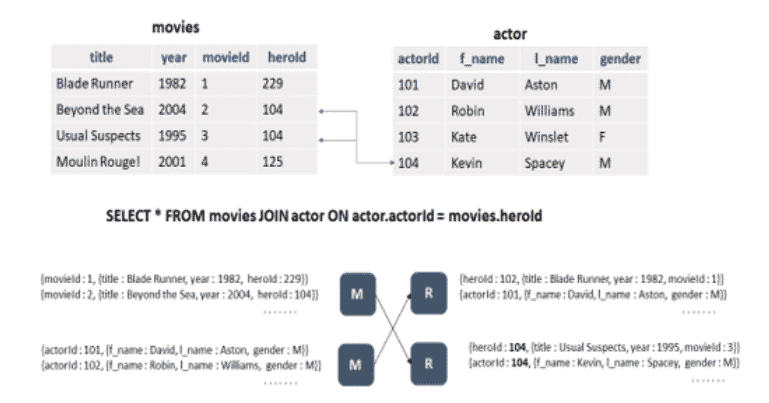
Shuffle join
C’est la technique de jointure par défaut dans Hive. Elle fonctionne quelle que soit la taille du dataset. Les clés identiques sont associées (shuffled) au même reducer et la jointure sera faite du côté du reducer.
Ce type de jointure est très coûteux d’un point de vue utilisation réseau. Tous les enregistrements des deux parties de la jointure doivent être traités par un mapper, associés et triés, même ceux qui ne font pas partie du résultat de la jointure.
Map join
Ce type de jointure est très efficace. Il est réalisable à condition que l’une des deux parties de la jointure soit suffisamment petite et puisse être chargée en mémoire.
Ainsi, ce plus petit ensemble peut être distribué sur tous les mappers ce qui permettra de faire la jointure dans la phase de Map. Ceci permet de réduire considérablement le nombre d’enregistrements à associer et à trier car seuls les enregistrements du résultat seront passés au reducer.

SMB join
Dans le cas où la taille des données des deux parties de la jointure est grande (donc impossible d’effectuer un Map join), une autre technique efficace de jointure consiste à trier les données en buckets. La principale contrainte pour réaliser ce type de jointure est de faire le clustering et le tri de données avec la même clé de jointure.
Le fait de grouper / répartir les données de cette façon a deux avantages :
⦁ Le tri par clé de jointure facilite l’opération de jointure. Tous les candidats possibles se trouvent sur le même espace disque.
⦁ L’utilisation du bucketing par clé de jointure assure que toutes les valeurs correspondantes seront localisées au niveau du même nœud. Dans ce cas, les Equi-joins peuvent être exécutés sans avoir besoin d’une phase d’association (shuffle).

Les fonctions prédéfinies (UDF – User Defined Functions):
Hive donne la possibilité d’étendre le framework et d’implémenter des fonctions prédéfinies en Java, Python ou Scala. En effet, les UDF peuvent être assimilées à des procédures stockées ce qui permet d’effectuer des calculs et des traitements qui n’existent pas nativement dans le framework.
Une fois définie, une UDF peut être invoquée dans un traitement (à partir d’un script Hive). Pour ce faire, il faut :
⦁ Enregistrer le jar qui embarque la classe de cette fonction
⦁ Définir un alias pour la fonction en utilisant la commande CREATE TEMPORARY FUNCTION
⦁ Invoquer la fonction

Conclusion
Hive facilite la prise en main d’un environnement Big Data complexe ou d’un datalake. Il permet l’interrogation des données stockées dans HDFS en faisant une abstraction par rapport à MapReduce. Grâce à HiveQL, l’analyse des gros volumes de données stockés dans HDFS devient aussi simple que le requêtage d’une base de données relationnelle.
Hive présente plusieurs avantages, notamment : sa maturité, la communauté active qui l’utilise ainsi que sa compatibilité avec les nouvelles versions de Hadoop. Autre avantage : proposer plusieurs fonctionnalités avancées pour le tri, la distribution, l’agrégation et la jointure de données.
Lire aussi

Lire la suite

Pas encore de commentaires