
Voilà plus d’un an qu’a été lancé ChatGPT, ébranlant la planète entière par ses applications révolutionnaires et ses résultats ahurissants. Depuis, l’outil n’a cessé de s’améliorer et de se démocratiser en s’intégrant peu à peu dans de nombreux secteurs et domaines d’activités. Pour mieux comprendre comment il fonctionne, focus sur les transformers.
Pour celles et ceux qui auraient loupé le train, ChatGPT, créé par l’entreprise OpenAI, est un outil d’intelligence artificielle qui joue le rôle d’assistant virtuel. Il permet de réaliser plusieurs tâches posées en langage textuel (dit langage naturel), de la simple conversation à la création de scénario de film, en passant par du résumé de texte ou encore de l’écriture de code. Les possibilités sont innombrables. Lancé le 30 novembre 2022, plusieurs autres versions plus améliorées ont depuis vu le jour.
Retour sur l’IA générative
ChatGPT fait partie de la famille des intelligences artificielles génératives, c’est-à-dire dont l’objectif est de générer (ou de créer) des éléments qui peuvent être de plusieurs types : texte, image, vidéo, audio… (voir la figure). Plus précisément, ChatGPT réalise les tâches qui lui sont données, en générant en sortie du texte cohérent à partir du texte reçu en entrée représentant la tâche à effectuer (on parle de prompt).
Il faut noter cependant que les versions de ChatGPT sont multimodales, c’est-à-dire qu’elles peuvent prendre du texte ou de l’image en entrée et produire du texte ou de l’image en sortie. Dans cet article, nous nous concentrerons sur la version text-to-text.
Pour pouvoir générer du texte, ChatGPT doit analyser et comprendre la demande textuelle qui lui est passée en entrée (le prompt). Puis, l’outil doit ensuite pouvoir construire un texte cohérent en le générant mot après mot (en sortie). D’une façon générale, ChatGPT est un modèle de langage large ou Language Model (LM) dans la langue de Shakespeare.
Qu’est-ce qu’un LLM ?
Les modèles de langage ou de langue (Language Models) sont des outils d’intelligence artificielle qui permettent aux machines de comprendre la complexité et la richesse du langage humain. Ils modélisent la construction de phrases ou permettent de représenter des concepts de la langue du point de vue sémantique ou même syntaxique.
D’un point de vue plus concret, ce sont des modèles qui permettent de modéliser la construction des phrases par une approche probabiliste, en considérant ces phrases comme une série de mots. L’idée étant de construire la probabilité du prochain mot en utilisant les mots précédents (figure ci-dessous) :
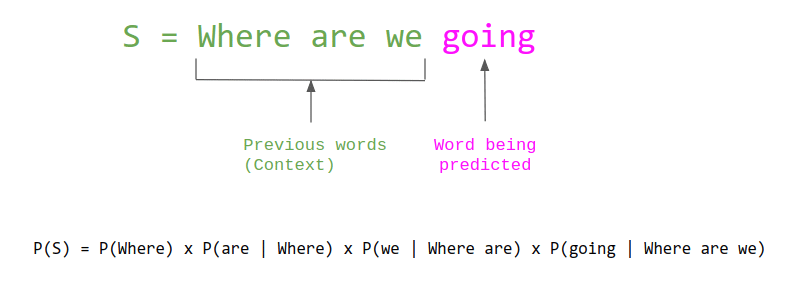
(Crédit : The Gradient)
Il existe plusieurs approches et techniques pour construire des modèles de langage. La plupart utilisent un certain nombre de paramètres (statistiques ou d’apprentissage automatique) : on parle de modèle paramétrique.
Lorsque ces modèles contiennent un très grand nombre de paramètres (de l’ordre du milliard), on parle de Large Language Models. Ces derniers permettent de comprendre de manière extrêmement profonde et subtile le langage humain, favorisant ainsi la réalisation de plusieurs tâches en générant un texte répondant à un besoin exprimé dans le texte en entrée (figure ci-dessous). Ces modèles sont entraînés sur de vastes quantités de données textuelles provenant essentiellement d’internet.

?? Envie d’en savoir davantage sur l’interprétation des modèles d’IA avec les méthodes LIME et SHAP ? Découvre cet article dédié. ➡ Interprétation des Modèles d’IA : LIME et SHAP
Les autres LLM
ChatGPT n’est pas le seul LLM. Il en existe en effet plusieurs autres. Parmi lesquels :
- Des LLM propriétaires détenus par des grosses entreprises tech : ChatGPT (GPT4, GPT3.5-turbo) de OpenAI, Gémini de Google ou encore Claude de Anthropic par exemple ;
- Des LLM open source utilisables par « tout le monde » mis à disposition par des laboratoires de recherche ou des entreprises : Mixtral de Mistral AI, LLaMA de Meta, Falcon de TII ou BLOOM de BigScience.
La plupart des LLMs actuels se basent sur le même modèle d’apprentissage automatique (deep learning) pour obtenir une compréhension aussi poussée du langage. Il s’agit des Transformers (oui je sais, original comme nom) ! Le but de cet article est donc de se faire une idée de comment fonctionnent les Transformers.

Bref historique des techniques de traitement et de génération de texte
Le traitement du texte en général et la génération de texte en particulier ne sont pas des sujets nouveaux dans l’intelligence artificielle. Historiquement, de nombreuses approches ont été proposées pour traiter le texte et construire des modèles de langages capables de générer du texte avant même l’arrivée des modèles Transformers.
D’une façon générale, le traitement du texte peut être assimilé dans les étapes suivantes que nous présenterons spécifiquement pour le cas des modèles Transformers (figure ci-dessous).

- Tokenization : processus qui vise à diviser le texte en petites unités (généralement des mots) pour mieux le traiter ;
- Embedding : processus qui vise à transformer les mots en vecteurs pour qu’on puisse réaliser des calculs dessus (oui, les ordinateurs ne comprennent que des nombres ?) ;
- Processing : une étape de processing qui définit vraiment la méthode et comment générer le texte.
Si ces notions seront détaillées pour le cas des modèles Transformers dans la suite de l’article, il est important de noter que la génération et le traitement de texte ont toujours été étroitement liés à la notion de word embeddings.
Word embeddings
Ce concept n’est pas en soi un modèle de langage, mais c’est une notion fondamentale pour comprendre le traitement du texte par les ordinateurs. L’idée consiste essentiellement à représenter du texte ou un mot sous forme de vecteur. Ainsi, chaque mot aura un vecteur qui lui est associé (figure ci-dessous).
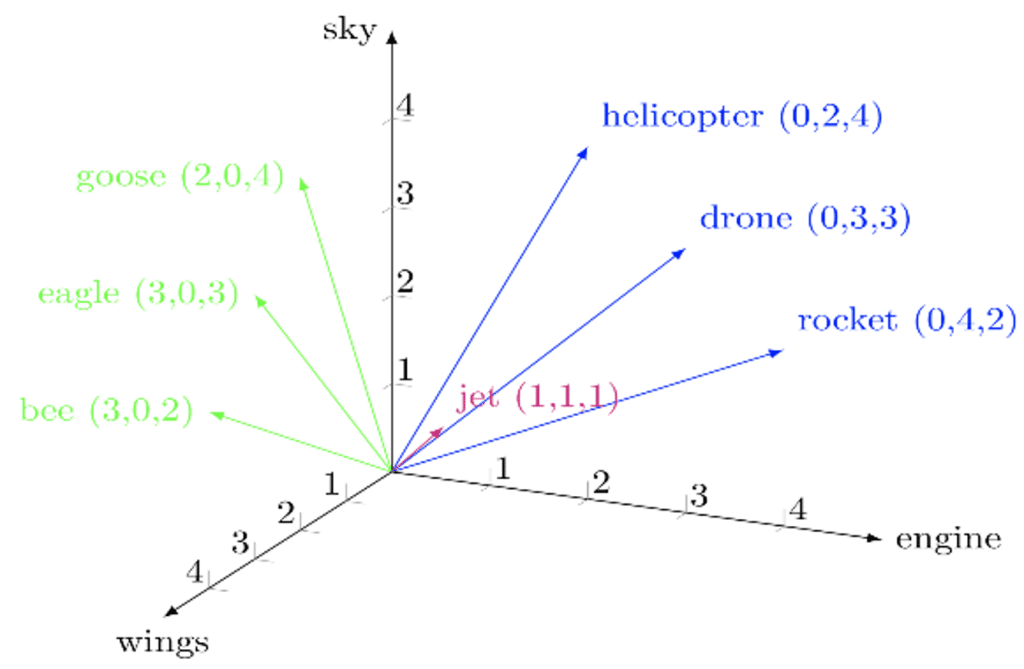
(Crédit : Hypotheses)
Ces vecteurs associés à chaque mot représentent le sens des mots. Ils permettent ainsi de créer un espace vectoriel de mot dans lequel les mots les plus proches sémantiquement sont proches dans l’espace et les mots les plus éloignés sémantiquement sont éloignés dans l’espace (voir figure ci-dessous).
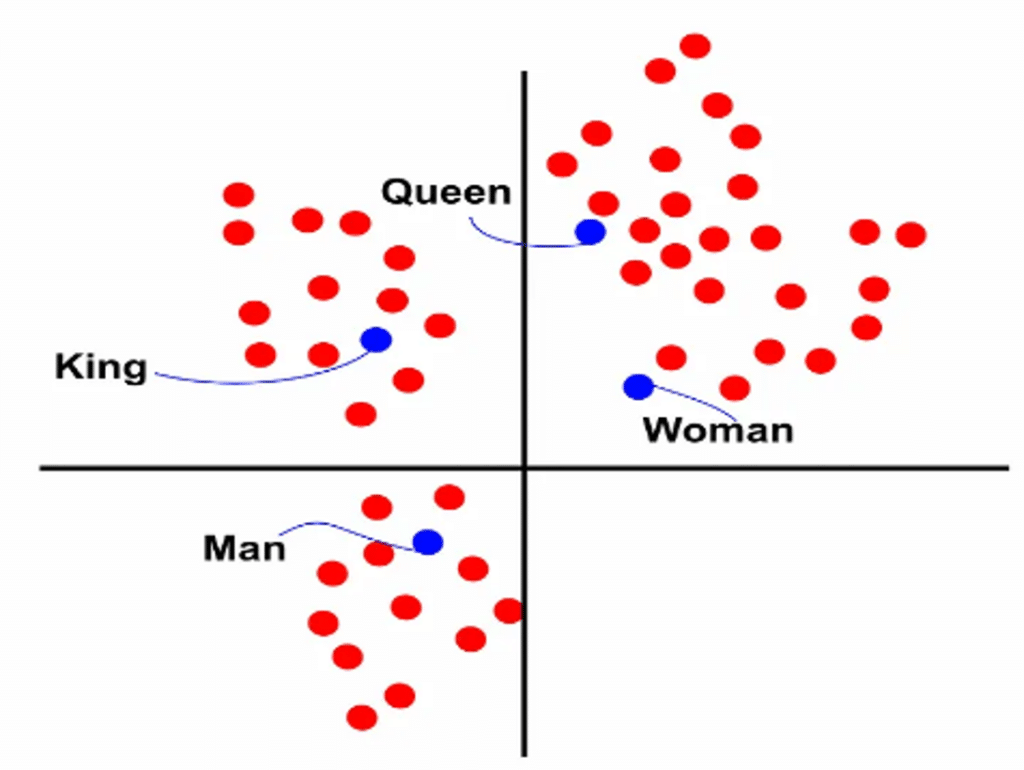
La représentation de chaque mot en vecteur est obtenue automatiquement en utilisant plusieurs techniques qui utilisent de grands corpus de texte pour comprendre la représentation de chaque mot.
Plusieurs techniques existent pour créer et apprendre ces vecteurs parmi lesquelles (cf. figure) :
- Word2Vect
- Skipgram
- C-bow
- Bert
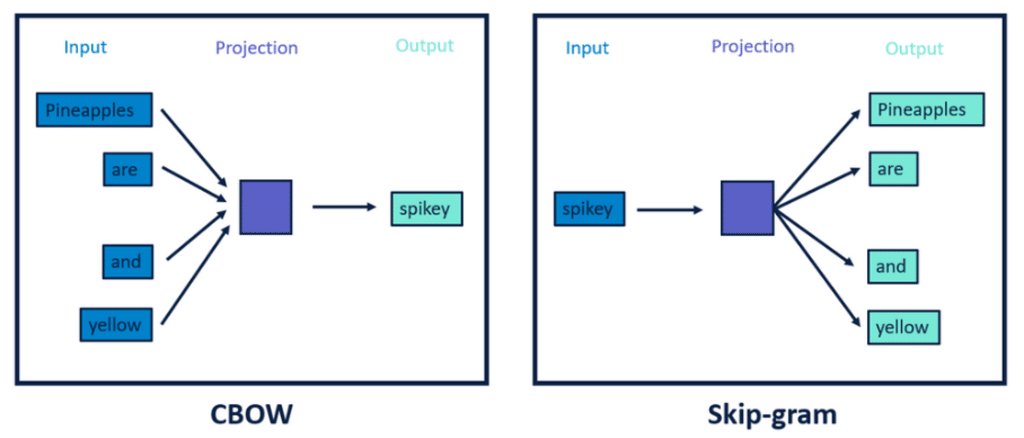
(Crédit : Alteryx)
La représentation des textes en vecteur ne suffit pas pour générer du texte, il faut maintenant des algorithmes / modèles capables de comprendre ces représentations. Un grand nombre d’approches statistiques ou de machine learning (simple) ont été développées pour générer du texte parmi lesquelles :
- N-Gram ;
- Les Hidden Markov Modèles (HMM) ;
- Les classifieurs pour la génération de texte.
Ces approches de machine learning sont très limitées et ont souvent fait place aux approches de deep learning (apprentissage profond) permettant d’avoir de meilleurs résultats.
Réseaux de neurones récurrents (RNN)
Parmi les approches de deep learning pour la génération de texte, celle qui a longtemps primé et qui produisait de bons résultats est l’approche des RNN.
Elle est l’une des premières utilisées pour la génération de texte. L’idée était d’utiliser un seul réseau de neurones profond pour générer itérativement une séquence, mot après mot (voir figure 07 ci-après).
Cette approche permet donc de générer du texte de longueur arbitraire. Plusieurs variations du réseau ont été proposées (RNN, GRU, LSTM). Cependant, ces approches présentaient deux gros points faibles : un temps de calcul très lent pour le calcul itératif des séquences et une faible capacité à gérer de longues séquences.
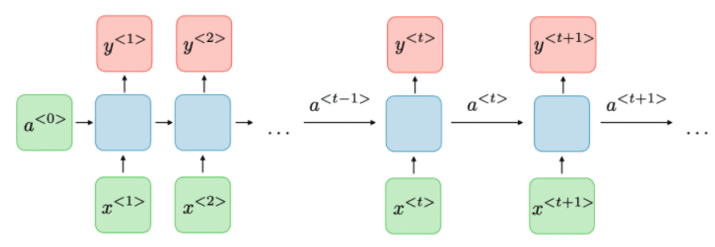
(Crédit : Stanford Edu)
Toutes ces limitations ont conduit à la construction d’une nouvelle famille de modèles qui ont permis de révolutionner le domaine de la génération de texte : les Transformers.
Il est à noter que, récemment, une nouvelle architecture a fait beaucoup parler d’elle et donnerait des résultats similaires aux Transformers : les modèles dits Mambas.

C’est quoi un Transformer ?
Les approches traditionnelles pour la génération de texte ont pris un coup de vieux avec la publication en 2017 par des chercheurs de Google du papier de recherche Attention is All you Need qui introduisait une nouvelle architecture de modèle pour le traitement du langage : les Transformers, qui sont devenus aujourd’hui la base des LLMs.
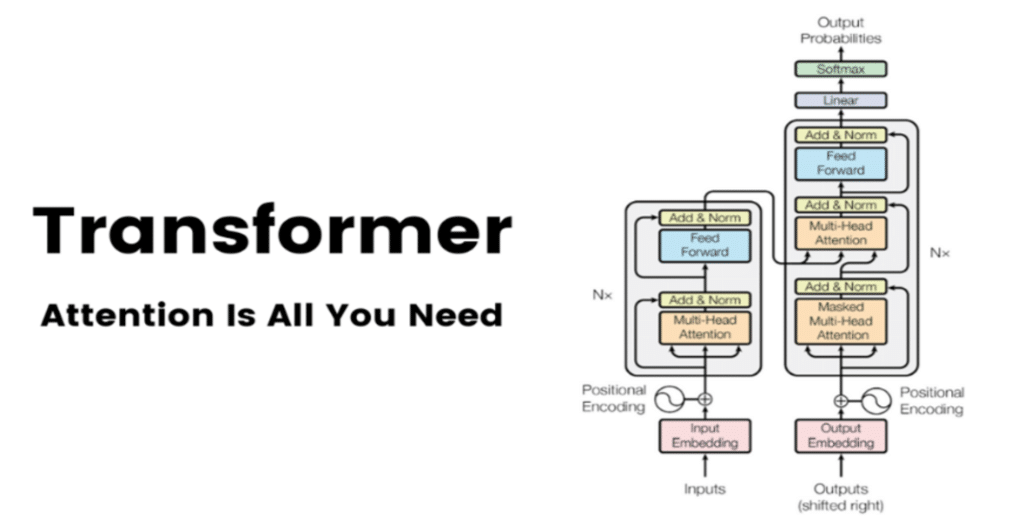
(Crédit: ‘‘Attention is all you need’’)
Les Transformers ont été initialement beaucoup utilisés pour la traduction de texte d’une langue à une autre, avant de se démocratiser à d’autres types de tâches, notamment la génération de texte avec les premiers modèles GPT d’OpenAI : Generative Pretrained Transformers (oui, c’est de là que vient le nom ChatGPT).
Quand on passe un prompt à ChatGPT ou à un modèle Transformer quelconque, on obtient en sortie un texte selon l’illustration suivante :

(Crédit : Jay Alammar)
Plusieurs étapes sont nécessaires pour passer du prompt (la demande textuelle ou la question posée au LLM) à la réponse générée par le modèle.
Tokenization
Pour être bien traité et analysé par le modèle, le texte passé en entrée va être séparé en plusieurs petits fragments représentant des mots ou encore des syllabes. Ces fragments sont appelés des tokens et on parle de Tokenization pour décrire ce processus.
Par exemple, la phrase suivante :
« Donne-moi un poème sur Meritis parlant du vent »
Va être transformée en une liste :
[ « Don », « ###ne », « _moi », « _un », « _poè », « ####me », … ]
Il existe plusieurs approches et algorithmes pour pouvoir découper efficacement les textes en tokens. L’idée étant d’avoir des tokens représentatifs de la langue et porteurs de sens.
Les modèles Transformers peuvent gérer un nombre maximum de tokens. C’est ce qu’on appelle la longueur de contexte (8000 pour GPT-4 par exemple, 4096 pour LLaMA, etc.). C’est aussi ce nombre de tokens qui est utilisé pour la facturation (1 euro pour 10000 tokens générés par exemple).
Embeddings
Une fois le texte en entrée découpé en une liste de tokens, chaque token de la liste est transformé en un vecteur de dimension égale à la taille du vocabulaire (le nombre de tokens reconnus dans les modèles, 32k pour LLaMA par exemple). Ce vecteur permet au modèle de réaliser des opérations matricielles sur les tokens (oui, les ordinateurs ne comprennent que les nombres, pas les mots). Et ces vecteurs sont ensuite convertis en d’autres vecteurs représentant le sens du token. On parle alors du processus d’Embedding.
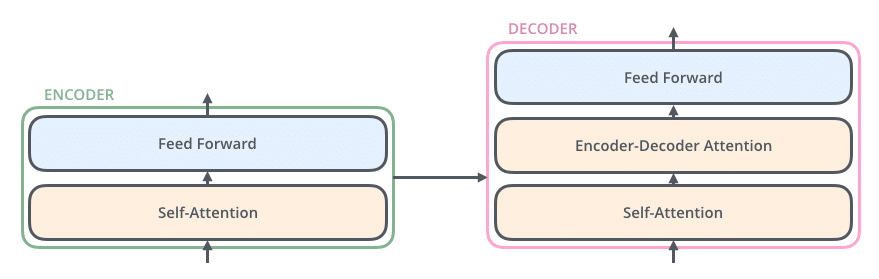
Encoder – Decoder
Chaque token étant transformé en embeddings, la liste des tokens sera passée au cœur du Transformer. Celui-ci est décomposé historiquement en deux parties :
- Une partie « Encodeur » (encoder en anglais) ;
- Et une partie « Décodeur » (decoder en anglais), comme indiqué sur la figure 10 ci-dessous :
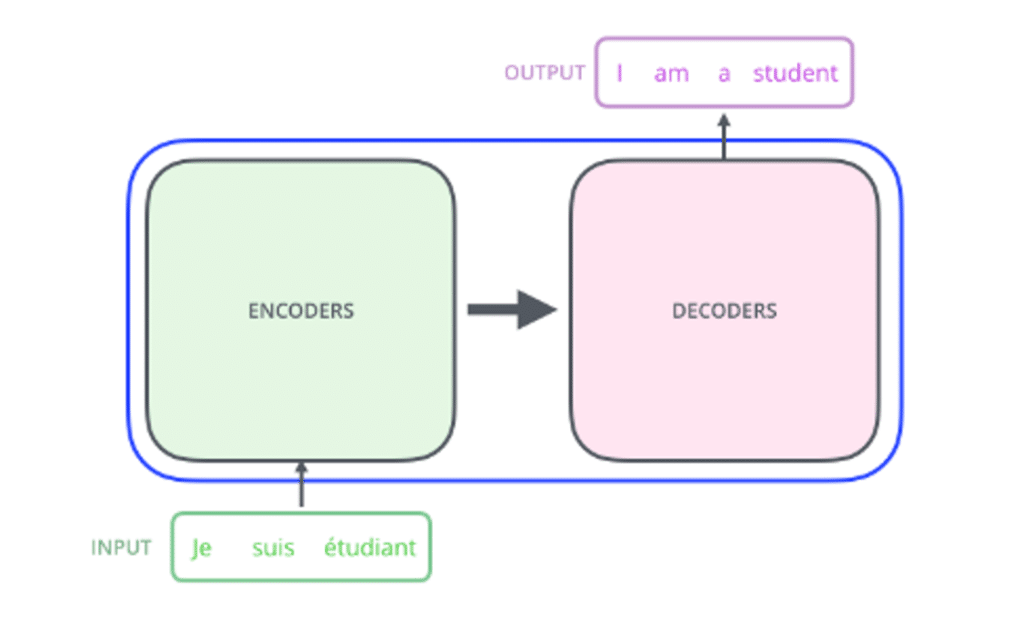
(Crédit : Jay Alammar)
La partie « Encodeur » a pour but de transformer la liste des embeddings de tokens en une représentation plus condensée contenant l’information utile pour la réalisation de la tâche : on parle d’encoding. C’est cette partie qui va notamment comprendre en profondeur le texte.
La partie « Décodeur » est celle qui s’occupe de générer itérativement le texte en sortie, token par token, en utilisant les tokens générés précédemment et la représentation encodée du texte d’entrée fournie par l’encodeur.
Le décodeur comme l’encodeur sont essentiellement constitués à l’intérieur d’un réseau de neurones classique (Fully Connected) et d’une couche de ‘‘Self-Attention’’ qui constitue la véritable innovation des modèles Transformers et qui leur permet de mieux comprendre le texte (voir figure 11 ci-dessous).
(Crédit : Jay Alammar)
Les différents types d’architectures
Il existe plusieurs types d’architectures de modèles Transformers :
- Encoder – Decoder (ou Seq2Seq) : c’est le type d’architecture dans lequel on a une série d’encodeurs suivie d’une série de décodeurs. Ce type de modèle est très adapté à la fois pour la représentation de texte et pour la génération.
- Encoder only : c’est un type d’architecture dans lequel on a que des encodeurs stackés les uns sur les autres sans décodeur. Ce type d’architecture est très utilisé pour la représentation de texte, ainsi que dans des modèles comme Bert.
- Decoder Only : c’est un type d’architecture dans lequel on a uniquement des décodeurs stackés les uns sur les autres sans encodeur. Cette architecture est très adaptée pour les modèles génératifs comme GPT ou LLaMA.
Que ce soit dans les blocs encodeurs ou décodeurs, on retrouve essentiellement une couche de réseau de neurone classique (Feed Forward) et une couche de ‘‘self Attention’’. Cette dernière couche est au cœur de la puissance des Transformers.
Self-Attention : qu’est-ce qu’un mécanisme d’attention ?
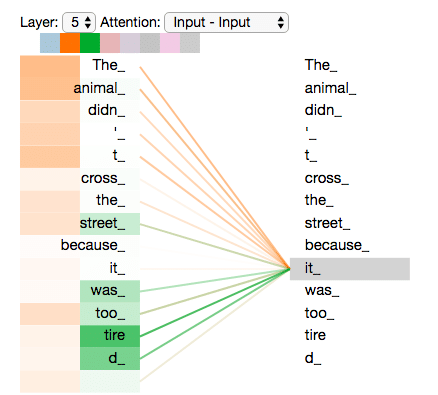
L’élément central des modèles Transformers repose sur le mécanisme de ‘‘Self-Attention’’. C’est ce mécanisme qui leur permet d’avoir une bonne compréhension du langage.
Son principe ressemble un peu à ce qui se passe dans notre cerveau quand on lit une phrase. On analyse « simultanément » tous les mots de la phrase et les relations qui les lient, sans se focaliser sur un seul mot uniquement. Au lieu de considérer les tokens (équivalents de mots) un par un, le modèle va considérer tous les tokens de la phrase simultanément et pour chaque token, il va accorder des niveaux d’importance (on parle de poids) aux autres tokens de la phrase.
Par exemple, dans la phrase suivante :
« Meritis est une entreprise rayonnante dont les valeurs sont… » :
Pour le mot « dont », le modèle attribuera, par exemple, l’importance (Meritis –> 30%, est -> 5%, une -> 2%, entreprise-> 33%, rayonnantes -> 10% etc.).
Ces niveaux d’importance ou les poids peuvent représenter des concepts concrets (synonymie, causalité, sujet verbe, etc.) ou des concepts abstraits implicites utiles pour la compréhension du langage. On parle de « tête d’attention ».
Le mécanisme d’attention permet également au modèle de se concentrer directement sur l’information utile, favorisant par conséquent le traitement de longues séquences sans pertes d’information (cf. figure 12 ci-dessous).
(Crédit : Jay Alammar)
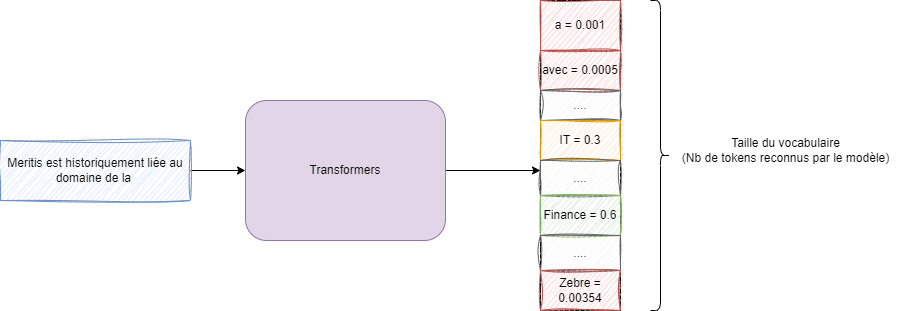
Sortie finale
Une fois les blocs d’encodeur et de décodeur traversés, l’information va passer dans une dernière couche qui est celle qui permet d’obtenir le texte en sortie. Cette couche dite de classification va donner la probabilité sur le prochain token en se basant sur la sortie des encodeurs / décodeurs.
Au lieu de donner directement le token (en sortie), le modèle donne la probabilité pour chaque token du vocabulaire (voir figure 13 ci-dessous).
(Crédit : Jay Alammar)
On peut prendre le token le plus probable ou alors faire varier les configurations en jouant avec des paramètres (température, sélection aléatoire parmi K, etc.) comme nous pourrons le voir en détail dans un prochain article.
Conclusion
Dans cet article, nous avons réalisé une vue macroscopique de la manière dont fonctionnent les Transformers, modèle qui se cache derrière ChatGPT et les LLMs, du prompt (texte en entrée) au texte en sortie.
ChatGPT n’est pas le seul LLM performant. En effet, plusieurs LLM existent sur le marché et de plus en plus de modèles open source voient le jour et se rapprochent des modèles payants comme GPT-4 d’OpenAI.
Ces modèles open source offrent l’avantage d’avoir le contrôle total sur ses données. Ils peuvent être personnalisés (finetuning) pour des besoins spécifiques, et même être exécutés sur son PC portable en utilisant certains outils spécifiques. Parmi ces modèles, on peut citer :
- Phi-2B (2 milliards de paramètres)
- Mistral 7B (7 milliards de paramètres)
- Mixtral 8x7B
- LLaMA 2 (7B, 13B, 70B)
- Zephyr 7B
Les Transformers sont des modèles fascinants qui ont permis de repousser les frontières de la compréhension du langage par les ordinateurs, notamment grâce au mécanisme de ‘‘self-Attention’’. Néanmoins, ces modèles présentent encore de nombreuses limitations qui doivent être adressées (hallucination, limite de contexte, lenteur et scalabilité, biais, évaluation, etc.). Attention donc à les utiliser correctement !
?? Découvrez ici « les 8 principales limites de ChatGPT«

? Recevez les dernières actualités et articles de blog directement dans votre boîte mail !


Pas encore de commentaires