
L’intelligence artificielle (IA) prend de plus en plus de place dans le monde d’aujourd’hui. La raison est simple : elle permet de grandes avancées dans de nombreux domaines tels que la santé ou le transport ou encore l’aide à la décision. Dans l’octroi de crédit par les banques par exemple, à chaque demande votre profil est analysé, les risques sont simulés, et c’est l’IA qui donnera un avis favorable ou non. Pour autant, les IA soulèvent un certain nombre de questions liées à leur manque de transparence. Nous allons présenter dans cet article comment interpréter les modèles d’IA avec les méthodes LIME et SHAP.
On pourrait penser qu’il est préférable que ce soit l’IA qui décide et non un humain car celui-ci pourrait se baser sur des critères non objectifs comme des préjugés ou des clichés. Mais des questions se posent : « Comment être sûr que l’IA a pris une décision logique ? Comment être sûr qu’elle se base sur les éléments qui comptent vraiment ? »
? Restez informé des dernières avancées en IA. Abonnez-vous à notre newsletter pour recevoir des articles, des études de cas et des actualités directement dans votre boîte mail.
Les IA, à commencer par les modèles de “deep learning”, ont pour réputation d’être inexplicables à cause de leur fonctionnement en “black box”, notamment liées aux couches cachées. Ce problème devient de plus en plus important et d’actualité, particulièrement pour des questions de sécurité, de responsabilité ou encore d’assurance. La recherche est donc très prolifique sur le sujet et il existe aujourd’hui des méthodes pour avoir des explications sur la prise de décision d’un modèle d’IA indépendamment de l’architecture choisie.
Pourquoi interpréter les modèles ?
Lorsqu’un modèle IA prend une décision, il y a deux questions que l’on peut se poser :
- Quels éléments ont le plus compté pour la prise de cette décision ?
- Est-ce que ces éléments sont factuellement importants ?
Par exemple, pour dire qu’une image représente un chien, on se base sur les caractéristiques du chien et non pas sur les nuages dans le ciel.
Il y a eu, dans le passé, de nombreux exemples de modèles que l’on pensait performants mais qui, finalement, se basaient sur de mauvaises caractéristiques pour prendre une décision. Heureusement un humain a pu remarquer l’erreur et la corriger. Mais qu’en est-il des nombreux modèles qui intègrent ce genre de problème mais qu’aucun humain n’a encore détecté ?
C’est pourquoi il est de plus en plus nécessaire d’avoir des outils capables d’automatiser la détection de ces disfonctionnements, et ce dans un but de sécurité et de transparence.
Dans la suite de cet article, nous allons donc faire la lumière sur deux de ces méthodes d’interprétabilité et d’explicabilité des modèles : la méthode SHAP et la méthode LIME.
Comment fonctionne la méthode SHAP ?
La méthode SHAP (SHapley Additive exPlanations) est une méthode utilisant les “Shapley values” avec une approche se basant sur la théorie des jeux. Cette méthode ne fonctionne que sur certains types de modèle d’IA : Catboost, Xgboost, Lightgbm, Sklearn Ensemble, Linear model et SVM, etc. Il est important de noter que la méthode est applicable sur ces modèles peu importe les données utilisées et/ou leur architecture.
Les quatre axiomes de la méthode SHAP
La méthode SHAP se base sur quatre axiomes : efficacité, symétrie, additivité et joueur nul.
- Efficacité : l’addition de la shapley value de chaque feature doit être égale à la valeur de la combinaison comprenant toutes les features. De cette manière, tous les gains sont distribués à chaque feature.
- Symétrie : la contribution de deux features doit être la même si ces deux features contribuent de la même manière sur toutes les combinaisons possibles.
- Additivité : la contribution de chaque feature pour une prédiction peut être calculée séparément puis ajoutée à celles des autres. Cela permet d’optimiser le temps de calcul.
- Joueur nul : si une feature a une contribution nulle sur toutes les combinaisons, alors elle doit avoir une shapley value égale à 0.
Ces axiomes permettent de s’assurer que la méthode est basée sur une théorie solide et dont l’unique solution sont les “Shapley values”.
L’importance des features
Le fonctionnement de cette méthode se base sur la contribution marginale de chaque feature.
Par exemple, prenons trois features : Rouge, Bleu et Vert. Toutes ces combinaisons sont évaluées et un score leur est attribué, comme indiqué dans la figure suivante.
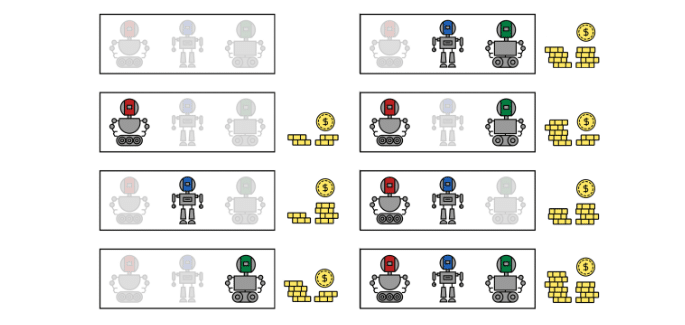
Ainsi, en évaluant toutes les combinaisons de features, on peut mesurer avec objectivité l’importance de chaque feature sur le résultat final. Cela permet de voir quelles sont les features qui contribuent le plus à la réussite du modèle. Un score est donc donné à chaque feature et est appelé “Shapley value”.
Une fois les “Shapley values” calculées, on peut trouver avec grande précision et objectivité quelles sont les caractéristiques les plus impactantes dans les choix du modèle, comme on peut le constater dans l’exemple ci-dessus.
Les features y sont représentées par des robots de couleur et l’évaluation d’une combinaison est basée sur l’argent qu’elle génère. Après avoir évalué toutes ces combinaisons, on peut calculer les “shapley values” et faire ressortir les robots qui contribuent le plus aux gains d’argent.
Comment fonctionne la méthode LIME ?
La méthode LIME “Local Interpretable Model-agnostic Explanation” est une méthode qui va donner une explication sur le comportement d’un modèle pour une prédiction donnée ou pour un sous-ensemble de prédiction avec la méthode SP-LIME.
Le principe de cette méthode est dit “Kernel based”, c’est-à-dire que pour donner une explication d’un modèle, la méthode LIME va créer un modèle explicatif qui se base sur le modèle original. Plutôt que d’analyser le modèle dans son ensemble, LIME se concentre sur une donnée spécifique pour comprendre pourquoi une prédiction particulière a été faite.
Pour ce faire, LIME crée un ensemble de données artificielles autour de cette donnée, en ajustant légèrement ses caractéristiques et en conservant les autres constantes (données perturbées ou augmentées). Cette approche permet d’étudier comment les prédictions du modèle varient en fonction de petites modifications dans les caractéristiques.
Les quatre principes de la méthode LIME
La méthode LIME est basée sur quatre principes :
- La facilité de compréhension avec, par exemple, le fait de souligner l’absence ou la présence de mots clés pour les textes, l’absence ou la présence de pixels pour les images ou la combinaison de colonnes pondérées pour les données tabulaires.
- La fiabilité en minimisant les différences de prédiction entre le modèle original et le modèle d’explication qui utilise des features approximées (légèrement différentes des features existantes).
- La flexibilité avec une utilisation possible de LIME sur tous les modèles de Machine Learning ou de Deep Learningn quel que soit le type de données utilisés en input.
- La généralisation avec la capacité pour une méthode d’expliquer la décision d’un modèle non pas sur une seule prédiction mais sur un ensemble de données. Pour atteindre ce principe, la méthode LIME a évolué en méthode SP-LIME (“Submodular Pick”).
Quelles différences entre les méthodes LIME et SHAP ?
Nous pouvons définir quatre axes de différences entre les méthodes SHAP et LIME :
- Là où la méthode SHAP ne peut pas être utilisée sur des modèles de Deep Learning mais uniquement sur des modèles de Machine Learning, la méthode LIME est complètement agnostique. Néanmoins, les deux méthodes sont utilisables sur tous types de données.
- La méthode LIME est au départ utilisée pour expliquer le choix d’un modèle sur une prédiction unique alors que la méthode SHAP va pouvoir donner une explication plus globale au niveau de l’importance des features (cette différence n’existe plus avec la méthode SP-LIME).
- L’approche de la méthode SHAP est basée sur la théorie des jeux pour expliquer la contribution marginale de chaque feature en leur attribuant un score. La méthode LIME est quant à elle basée sur une approche dite “Kernel-based” en créant un modèle pour expliquer le comportement de notre modèle sur une instance spécifique.
- La méthode LIME fait le choix de sacrifier de “l’accuracy” en utilisant des données dites perturbées, alors que la méthode SHAP ne fait aucun sacrifice. En revanche, elle est gourmande en ressources (temps de calcul) et son explication du modèle est plus compliquée à comprendre.
Exemple pratique d’utilisation des méthodes LIME et SHAP
Nous présentons dans cette section un exemple pratique de l’utilisation des deux méthodes LIME et SHAP pour interpréter un modèle généré sur le même ensemble de données.
Données et modèle
Nous allons appliquer les deux méthodes sur un même modèle LightGBM généré sur une base de données relative au passager du Titanic. Le but ici est de voir quelles sont les features les plus importantes menant à la survie des passagers.
Voici un aperçu des données :
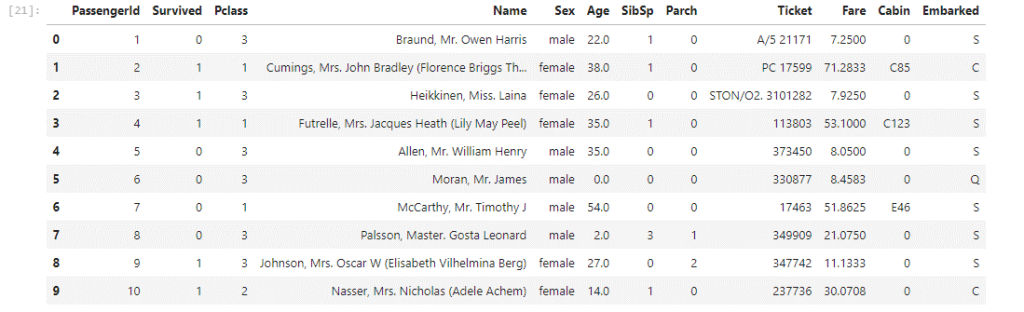
Et un aperçu du modèle :

Le modèle est utilisé pour faire de la classification binaire et classer les personnes en fonction de si elles ont survécu ou non (Survived = 0 ou 1).
Application de la méthode LIME
Nous allons maintenant voir les explications de la méthode LIME sur une prédiction :

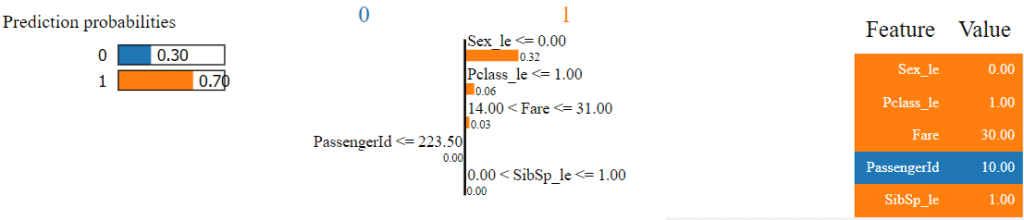
Sur cette image, on voit les prédictions du modèle pour l’input donné (échantillon d’indice i = 9), classe 0 (didn’t survive) avec 30% et classe 1 avec 70%. La figure du milieu nous donne l’importance de chaque feature pour arriver à cette décision avec notamment un intervalle associé à chacune d’entre elle. Dans cet exemple, c’est la feature “Sex_le” qui est la plus importante pour arriver à l’output du modèle, à savoir 1.
Il est possible, en utilisant SP-LIME, d’obtenir ces graphiques sur plusieurs prédictions :

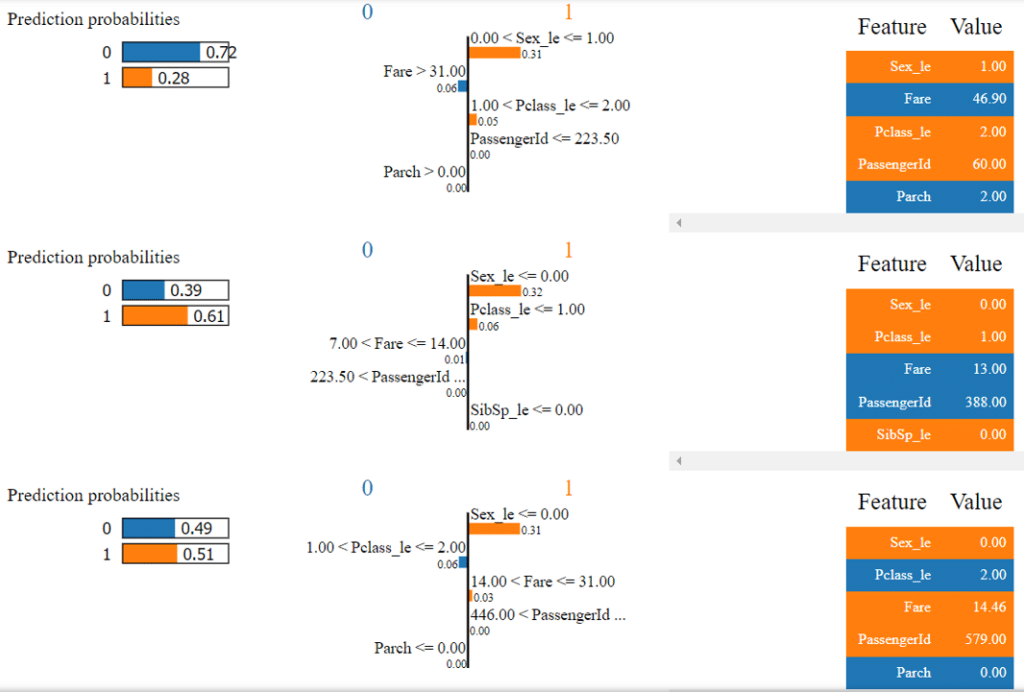
On retrouve ici les mêmes schémas que ceux que l’on avait avant mais pour plusieurs prédictions. On peut donc affirmer avec plus de confiance que la feature “Sex_le” est la feature avec la plus grande importance pour classer un passager dans la catégorie “Survive”.
Application de la méthode SHAP
La méthode SHAP va plutôt donner une idée générale sur l’explicabilité du modèle et non sur une prédiction en particulier :
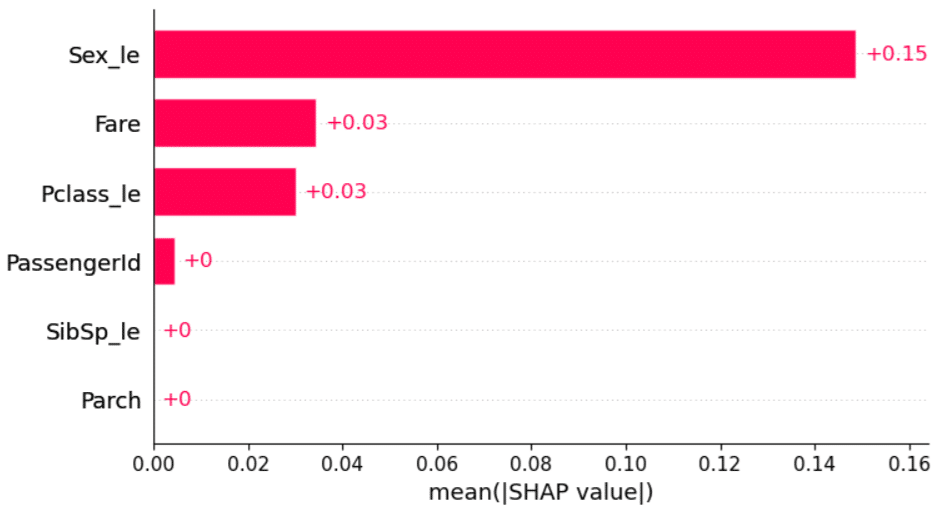
Ici, chaque feature est associée à une shapley value qui correspond à sa contribution marginale au sein du modèle. Plus la shapley value sera élevée, plus la feature a une contribution importante et est donc très utilisée par le modèle. On peut voir que la méthode SHAP nous renvoie le même résultat que la méthode LIME en désignant notamment la feature ”Sex_le” comme étant la plus importante.
L’autre forme de graphe, la plus connue, avec la méthode SHAP est la suivante :

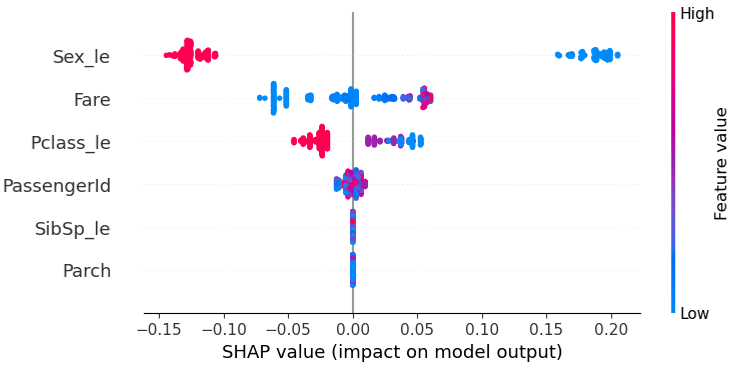
Ce graphique est souvent préféré car il apporte plus d’informations et de manière claire. Il donne pour chaque feature un ensemble de shapley values (représenté par un nuage de point) qui représentent chacune une instance donnée.
Sur ce graphique, la couleur représente la valeur de la feature pour l’instance donnée. La shapley value est alors soit positive (et impacte les prédictions de manière positive), soit négative (et impacte les prédictions de manière négative).
On peut donc constater que la caractéristique « Sex_le » est significative, mais il semble également qu’un des deux sexes ait une influence négative sur le modèle. Cela signifie que, lorsque cette caractéristique est présente dans une prédiction, il y a de fortes chances que le modèle commette une erreur.
Les librairies dérivées
Les librairies principales pour ces deux méthodes sont les librairies SHAP et LIME, mais il existe d’autres librairies que l’on peut utiliser. Ces dernières ont l’avantage de fournir des figures supplémentaires pouvant aider à mieux comprendre certains détails ou à projeter l’analyse selon d’autres angles de vue.
Shapash
Shapash est une librairie qui implémente la méthode SHAP et génère une Webapp qui facilite la compréhension des interactions des features du modèle.

Webshap
webShap est la première librairie Javascript qui utilise la méthode SHAP pour le web. WebShap permet d’utiliser directement SHAP dans le navigateur web.

Nous n’avons malheureusement pas trouvé, à la date de rédaction de cet article (mars 2024), d’autres librairies implémentant la méthode LIME.
Conclusion
Il est évident que les modèles IA d’aujourd’hui nécessitent plus de transparence et plus d’explicabilité, et que des techniques telles que SHAP et LIME vont se démocratiser. Cette nécessité est de plus en plus soutenue par de grandes entreprises ou même par des textes de lois (par exemple, l’IA Act).
Les méthodes SHAP et LIME ont des qualités et des défauts qui leur sont propres. Une bonne approche pour leur utilisation pourrait être de privilégier SHAP quand c’est possible en termes de modèle et de volumétrie de données, et LIME dans le cas contraire.
Par ailleurs, les Large Language Models (LLM), qui sont volumineux et constitués de multiples couches comme GPT, auraient grandement besoin de techniques d’explicabilité pour mieux comprendre leurs comportements et leurs décisions.
Des approches émergentes comme le « retrieval-augmented in-context learning » commencent à émerger pour répondre à ce défi. Ces méthodes visent à incorporer des mécanismes de récupération d’informations dans le processus d’apprentissage, ce qui permettrait aux modèles d’apprendre à partir de contextes plus riches et de mieux expliquer leurs décisions.




Vos commentaires
Merci Clément pour le partage !