
Depuis l’introduction des modèles de langage basés sur l’architecture « transformers », le domaine de l’IA générative a révolutionné la manière dont les entreprises interagissent avec les données. Cependant, les coûts élevés et les risques pour la confidentialité ont freiné l’adoption généralisée de ces modèles. Une réponse émerge à travers le concept du Retrieval Augmented Generation (RAG) qui permet d’améliorer les résultats des modèles tout en répondant aux défis de coûts et de sécurité. Découvrez comment le RAG redéfinit les possibilités de l’IA générative dans ce premier article de notre série dédiée au sujet.

Depuis 2017 et la parution de l’architecture dite « transformers », les modèles de langage sont devenus monnaie courante, poussant les grandes entreprises de la tech à se lancer dans une course folle à la recherche du modèle le plus performant. Les coûts d’entraînement de ces modèles, autant temporels que financiers, représentent une barrière infranchissable au développement de modèles internes pour la plupart des entreprises.
En parallèle, l’utilisation de modèles de langage possédés par des grands groupes sur des documents internes à l’entreprise représente une menace en termes de sécurité des données. Une solution tend à résoudre ces deux problèmes : le RAG.
Le RAG, c’est quoi ?
Le concept de RAG appartient au champ de l’IA générative qui est désormais ancré dans le paysage tech. Ce terme, parfois utilisé à tort et à travers, est composé du mot « IA », métonymie assez grossière pour parler de Deep Learning, et du mot « générative » pour décrire le but quant à l’utilisation de ces réseaux de neurones profonds. Faire de l’IA générative, c’est donc utiliser un modèle de réseaux de neurones pour générer un contenu.
Le contenu qu’il est possible de générer, c’est-à-dire la sortie du modèle, s’étend sur un spectre assez large allant du texte à la vidéo en passant par l’image. En revanche, l’entrée du modèle est généralement la même : elle porte le nom de query ou requête, et se présente comme un texte en langage naturel.
L’approche RAG s’inscrit exactement dans cette logique et suit la même trame directionnelle, avec, en entrée, une requête écrite en langage naturelle, et en sortie, un contenu généralement textuel.
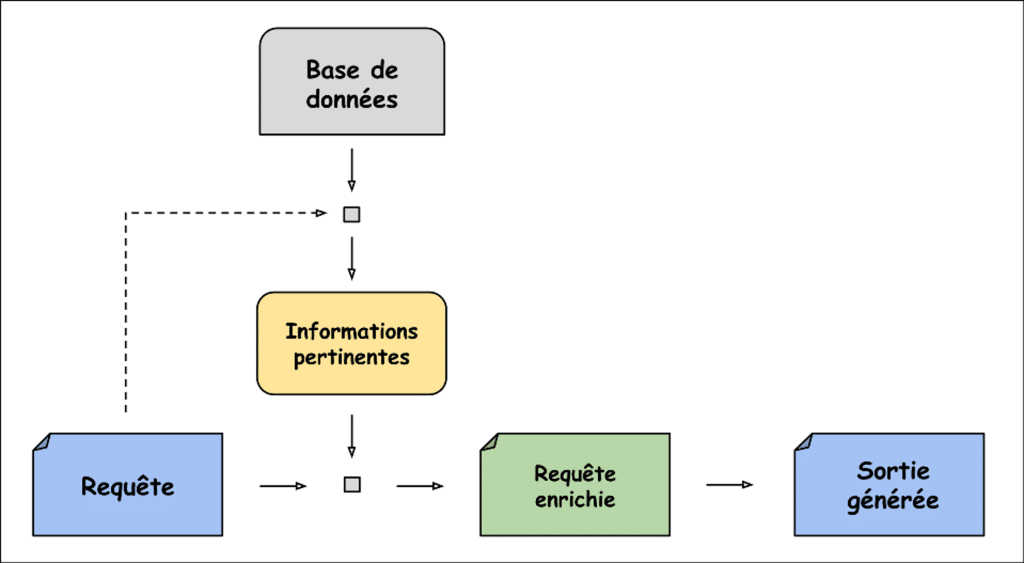
La dénomination « RAG » est un acronyme anglophone duquel découle trois mots : Retrieval, Augmented et Generation. L’idée maîtresse du RAG, élégamment contenue dans son nom, est tout simplement d’enrichir la requête initiale (Augmented) grâce à un système de récupération d’informations (Retrieval) pour améliorer la sortie générée (Generation).
Les informations sont à récupérer dans une base de données externe et la partie génération est assurée par un modèle de langage.
Les intérêts d’un système RAG
Les méthodes de génération de texte actuellement utilisées reposent presque toutes sur des modèles de langage appelés LLM pour Large Language Models. Ces modèles permettent de traiter efficacement le langage naturel, ce qui les rend utiles pour de nombreuses applications telles que la traduction, l’analyse de sentiments ou la conversation automatisée.
La vie d’un LLM se déroule selon trois phases :
- L’architecture ;
- L’entraînement ;
- Et l’utilisation.
La phase d’architecture requiert des compétences techniques pour faire des choix assez complexes et déterminants (nombre de couches, nombre de neurones par couche, fonction d’activation, algorithme de backpropagation…).
La phase d’entraînement prend énormément de temps, nécessite de nombreux moyens matériels (GPUs) et requiert également une quantité faramineuse de données.
La phase d’utilisation est celle qui est visible par tous lorsque le modèle est publié.
Mais lors de ces trois phases des problèmes intrinsèques émergent.
Coût de l’architecture et de l’entraînement
Les ingénieurs et les GPUs coûtent chers mais sont indispensables pour développer un LLM. Ce prix exorbitant – de l’ordre de plusieurs dizaines de millions de dollars pour GPT-3 – rend impossible le développement de LLM en interne pour des entreprises non-spécialistes du domaine. Or l’utilisation d’un LLM externe pour traiter les données d’une entreprise peut poser des problèmes de confidentialité.
Temps d’entraînement
Choisir une bonne architecture et entraîner ces modèles toujours plus volumineux prend du temps, ce qui rend impossible la mise à jour fréquente des LLM. Un LLM s’entraîne sur un data set figé dans le temps – GPT-3.5 a, par exemple, des connaissances s’arrêtant à octobre 2023 – et n’a accès à aucune donnée confidentielle d’une entreprise.
Données d’entraînement
La nécessité de disposer d’énormément de données pour entraîner les LLM implique qu’il est impossible de vérifier exhaustivement la qualité des données d’entraînement utilisées. Généralement, ces données sont des textes provenant de nombreuses pages web, qui peuvent donc contenir des informations erronées ou biaisées. Une mauvaise qualité du corpus d’entraînement se répercute inévitablement sur le comportement final du modèle – hallucination et biais entre autres.
👉 Envie d’aller beaucoup plus loin sur la thématique des biais dans les modèles de langage ?
Découvre cet article scientifique dédié : Les représentations contextuelles stéréotypées dans les modèles de langue français : mieux les identifier pour ne pas les reproduire
Hallucination
Lorsque le LLM entre dans sa phase d’utilisation, il sert généralement à générer du texte. Cependant, il faut bien avoir conscience qu’un modèle génératif de langage ne fait que compléter du texte avec ce qui lui semble le plus probable. Il lui arrive donc parfois de générer un texte contenant des informations erronées : on dit alors que le LLM hallucine.
Il est tout de même bon d’avoir à l’esprit que l’hallucination est, pour partie, due à la qualité de la requête soumise et qu’il est donc possible de limiter ce phénomène en formulant ses requêtes de manière méticuleuse.
👉 Envie de rapidement découvrir les règles d’or pour une rédaction parfaite de ses requêtes ?
Découvre ce post LinkedIn dédié : Maîtriser l’Art du Prompting

Ces problèmes rendent impossible le développement d’un LLM omniscient parfait dans ses réponses et aux connaissances actualisées en temps réel. C’est à travers ce prisme que s’est développé le RAG. En effet, un RAG vient récupérer de l’information pour la transmettre à un LLM déjà entraîné dans le but d’améliorer la qualité de la réponse générée. Le RAG permet donc d’améliorer les résultats d’un LLM en s’affranchissant de la partie « coût » liée à l’entraînement du modèle.
De plus, les informations qu’utilisent un RAG proviennent d’une base de données externe qui peut donc être privée et facilement mise à jour. Le RAG permet également de prévenir le risque d’hallucination en communiquant de l’information supplémentaire au LLM et en permettant à l’utilisateur de fact-checker la réponse obtenue en affichant les documents utilisés pour générer la sortie.
Un RAG considéré comme naïf
En théorie, il suffit de deux éléments pour exploiter un RAG :
- Une base de données ;
- Et un algorithme de récupération d’informations.
En pratique, pour mettre en place un RAG il faut principalement considérer quatre éléments techniques.
1.
Phase d’indexation
Comment je stocke les informations de ma base de données pour pouvoir les retrouver efficacement ?
2.
Phase de récupération
Comment je récupère des informations pertinentes parmi toutes les informations que j’ai stockées ?
3.
Phase d’enrichissement
Sous quelle forme je transmets l’information retenue au LMM ?
4.
Phase de génération
Comment je passe de la requête enrichie à la réponse finale attendue ?
Fonctionnement du RAG naïf
La première approche, appelée RAG naïf, est finalement une approche assez naturelle. Elle consiste à découper les documents de la base de données en sous-documents et à donner en contexte au LLM, les sous-documents les plus pertinents pour générer une réponse la plus qualitative possible.
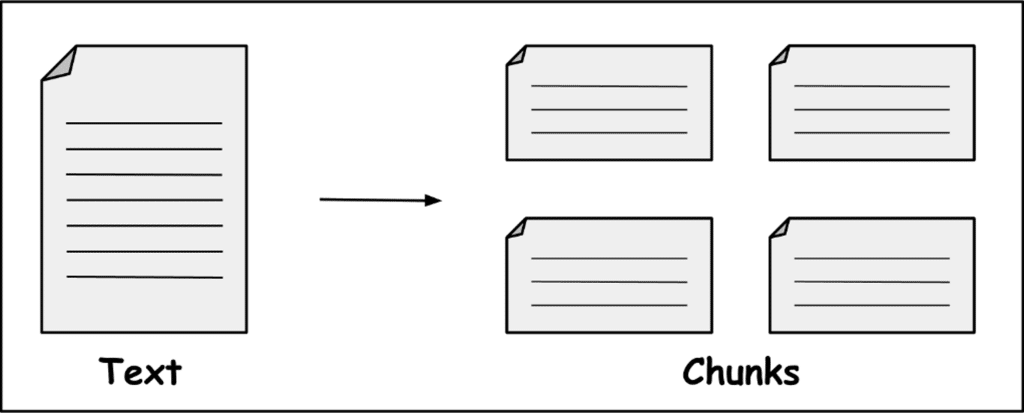
C’est quoi exactement des sous-documents ?
La plupart des bases de données sur lesquelles des systèmes de RAG sont mis en place sont des corpus de textes. Dans ce cadre-là, un sous-document est appelé chunk et correspond à une partie du texte d’origine.
Pour créer ces chunks de manière efficace, il est courant d’utiliser un paramètre de taille et un paramètre d’overlapp, tous deux exprimés en nombre de caractères. Par exemple, un texte de 1 300 caractères associé au paramétrage taille = 500 caractères et overlapp = 100 caractères, donnera 3 chunks :
- Le premier s’étendra du 1er caractère du texte jusqu’au 500e :
- Le deuxième du 400e au 900e caractère ;
- Et le dernier du 800e au 1300e caractère.
C’est quoi le « contexte » d’un LLM ?
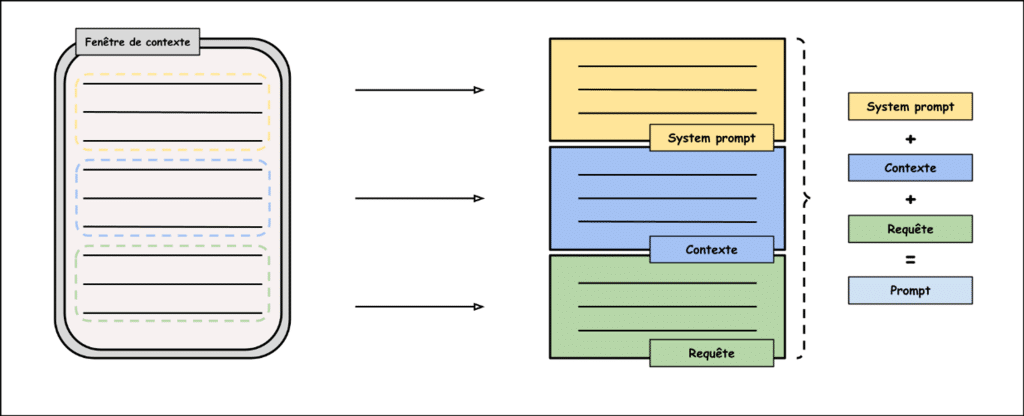
Lorsqu’on interagit avec un LLM, il faut bien distinguer 4 éléments distincts :
- La requête ;
- Le prompt ;
- Le contexte ;
- Et la fenêtre de contexte.
La requête, souvent à tort appelée prompt, n’est qu’une partie de celui-ci. Elle désigne la phrase que l’utilisateur écrit pour décrire la tâche donnée au LLM. Le contexte appartient lui aussi au prompt. C’est l’ensemble des informations supplémentaires données au LLM, en plus de la consigne, pour qu’il réalise au mieux le travail demandé.
Le prompt quant à lui, désigne l’instruction globale que va recevoir le LLM avant d’exécuter sa tâche. Un prompt se décompose en trois parties : le system prompt, le contexte et la requête. Le system prompt est une consigne absolue que le LLM doit respecter pour toutes les requêtes à traiter. Pour finir, la fenêtre de contexte se définit comme l’endroit dans lequel on rentre le prompt.
Pourquoi ne pas mettre tous les chunks dans le contexte ?
Lorsqu’une requête commence sa course à travers le LLM, elle est tout d’abord découpée en unités sémantiques – d’environ quatre caractères – appelées tokens. Chacun de ces tokens est ensuite transformé en un vecteur numérique pour permettre au modèle d’effectuer des calculs.
Pour conserver une vitesse de calcul raisonnable, ce nombre de vecteurs – et donc de tokens – est limité et dépend du modèle choisi. L’existence d’une telle barrière architecturale implique l’impossibilité de donner tous les chunks en contexte au LLM car la limite du nombre de tokens serait dépassée. Il faut donc choisir intelligemment les informations additionnelles à donner à notre LLM.
👉 Envie d’en savoir davantage sur l’architecture transformers qui régit les modèles de langage actuel ? Découvre cet article dédié : Les Transformers, le modèle derrière la puissance de ChatGPT
Comment choisir les chunks pertinents dans ce cas-là ?
La plupart des RAG se différencient justement sur ce point-là. Le RAG naïf, lui, utilise le concept d’embedding pour juger de la pertinence des différents chunks. Faire l’embedding d’un mot – ou d’un texte plus généralement – consiste à transformer cette unité textuelle en un vecteur numérique de telle sorte que, plus deux textes sont proches sémantiquement, plus la distance entre les deux vecteurs qui les représentent est petite.
Pour visualiser cette notion, il suffit d’imaginer un plan sur lequel chaque point placé correspond à un texte. Si deux points sont proches alors les deux textes correspondants illustrent des idées similaires. L’idée est donc toute trouvée : pour savoir si un chunk est pertinent, il suffit de calculer les distances entre les embeddings des chunks et l’embedding de la requête, et de garder les chunks associés aux distances les plus faibles.
Qu’est-ce que le vector base dans le cadre des RAG ?
Le RAG naïf repose sur une structure de base de données appelée vector base ou vector store ou encore base vectorielle pour les plus francophones. Si vous avez bien suivi jusque-là, il ne vous a pas échappé qu’un RAG naïf commence par découper les différents textes de la base de données en chunks, puis transforment tous ces chunks en vecteurs numériques pour les comparer au vecteur de la requête.
Ce vecteur dérivant de la requête change selon la requête posée. En revanche, les vecteurs associés aux chunks eux, restent toujours les mêmes. Il suffit donc de faire une seule fois ce travail de numérisation pour tous les chunks, puis de stocker ces vecteurs pour s’en servir à chaque fois qu’une nouvelle requête arrive. Ces vecteurs, résultats de l’embedding des différents chunks, sont stockés dans ces fameuses bases vectorielles.
Une base vectorielle, c’est donc tout simplement un endroit dans lequel on stocke des vecteurs numériques associés à des chunks. En théorie, un tableau à deux colonnes – chunks et vecteurs – est déjà une base vectorielle. En pratique, les implémentations de bases vectorielles proposent un système optimisé pour retrouver les vecteurs proches de la requête et associent à chaque chunk des metadata – par exemple, le titre du document d’où provient ce chunk – en plus de son vecteur.
Comment fonctionne le RAG naïf ? (résumé)
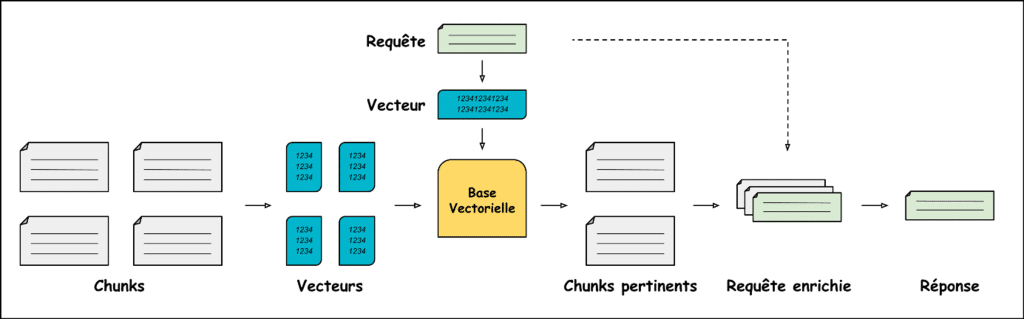
Reprenons les quatre étapes introduites plus tôt :
- La phase d’indexation du RAG naïf consiste à découper les textes en chunks pour les transformer en vecteurs et finalement les stocker dans une base vectorielle.
- Ensuite, vient la phase de récupération. Elle consiste à transformer la requête en vecteur pour récupérer dans la base vectorielle les vecteurs les plus proches. Ces vecteurs sont associés à des chunks qui, grâce aux propriétés de l’embedding, sont les plus proches de la requête d’un point de vue sémantique.
- La phase d’enrichissement est une simple concaténation entre les chunks récupérés et la requête initiale …
- … pour arriver finalement à la phase de génération où l’assemblage chunks-requête est donné à un LLM pour obtenir une réponse.
Vous envisagez d’utiliser ChatGPT pour créer votre propre RAG ?
👉 Découvrez notre article qui traite du fonctionnement et des limites de ChatGPT

Le mot de la fin ?
Si quelqu’un vous demande ce qu’est un RAG, vous pourrez maintenant lui expliquer qu’un RAG est tout simplement un ensemble de méthodes qui, mises bout à bout, permettent de générer un contenu à partir d’une requête et d’informations disponibles dans une base de données et que, comme toute méthodologie, cette dernière a des avantages mais aussi des inconvénients.
Malgré tous les problèmes évoqués, le RAG est aujourd’hui un sujet courant d’IA générative. Comment un outil avec autant de problèmes peut s’imposer comme une technologie émergente ? C’est simplement que la version présentée ici n’est que la version naïve du RAG, c’est-à-dire la première qui a suscité de l’intérêt chez les initiés du domaine. Pour découvrir les nombreuses autres versions du RAG et explorer les innovations qui les accompagnent, consultez dès maintenant la partie 2 de notre série sur le RAG avancé !
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.



Vos commentaires
Très bon article