
Face à l’explosion des volumes de données et à la diversité croissante de leurs usages, les entreprises doivent choisir des architectures adaptées pour optimiser leur gestion et leur exploitation. Mais difficile de s’y retrouver parmi les différentes approches : data warehouse, data lake, modern data warehouse, data fabric, data mesh… Cet article propose un tour d’horizon des principales architectures de données en se focalisant sur leur fonctionnement, leurs bénéfices et leurs cas d’usage.

Introduction
Une architecture de données définit une approche globale à adopter, précise les technologies à utiliser et décrit le flux de données nécessaire pour capturer les informations pertinentes. Or le choix d’une architecture de données peut s’avérer complexe, car il n’existe pas d’architecture universelle. Il n’y a pas de méthode simplifiée ou d’arbre de décision permettant de trouver l’architecture idéale. L’approche et les technologies choisies varieront considérablement en fonction du client, du cas d’usage et des objectifs spécifiques.
Bien qu’on puisse classer les architectures de données par type en fonction de leurs caractéristiques, chacune d’elles est unique et nécessite une approche personnalisée pour répondre aux besoins particuliers de l’entreprise. Construire une architecture adaptée est cruciale car elle garantit une gestion efficace des données, améliore la prise de décision, optimise les performances, et permet à l’entreprise d’exploiter pleinement son potentiel d’innovation et de compétitivité.
Dans la suite de cet article, nous nous attachons à vous présenter les principales architectures data développées au cours des 50 dernières années, en suivant une approche chronologique pour mieux comprendre leur évolution et leurs impacts sur la gestion des données.
Envie de découvrir l’histoire des architectures data plus en détail ?
👉 Découvrez notre article « Comment les architectures Data ont transformé le stockage et l’analyse des données en 50 ans ? »

Quels sont les différents types d’architecture de données ?
1- Data warehouse (DW) – Définition, fonctionnement et cas d’usage
Un data warehouse (ou DW) est une base de données relationnelle conçue spécialement pour de l’analytique et de la business intelligence, avec des performances optimisées en lecture et une prise en charge de l’analyse de données à grande échelle.
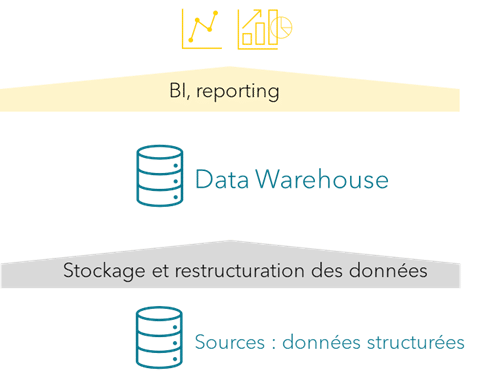
Un DW sert de référentiel central et il permet de créer une vue unifiée et cohérente des données d’une entreprise. Toutes les données sont stockées dans un format structuré. Les utilisateurs ont accès aux mêmes informations, éliminant ainsi toute divergence ou incohérence, et supprimant les silos de données. Cela améliore la prise de décision, la collaboration et l’efficacité dans l’ensemble de l’entreprise.
Si un data warehouse est utilisé par toute l’entreprise, il est nommé Enterprise Data Warehouse (ou EDW). Il est plus robuste et complexe qu’un data warehouse standard. L’EDW fournit une vue unique et unifiée de toutes les données de l’entreprise.
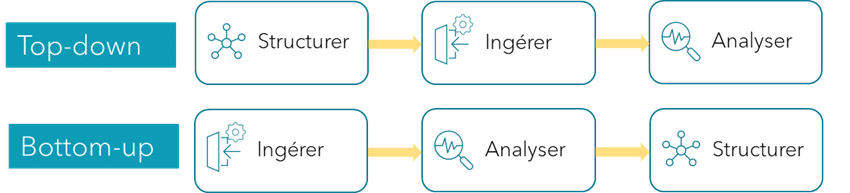
Dans le cadre d’un DW, il est nécessaire de réaliser un travail en amont afin d’obtenir les données qui permettront de créer des rapports. Ce travail préalable est une méthodologie de conception et de mise en œuvre appelée « top-down ».

Cette approche fonctionne bien pour les rapports de type historique, dans lesquels vous essayez de déterminer ce qui s’est passé (analyse descriptive) et pourquoi cela s’est passé (analyse diagnostique).
L’analyse descriptive et l’analyse diagnostique sont deux types d’analyses de données couramment utilisés dans le business. L’analyse descriptive est utilisée pour comprendre ce qui s’est passé et pour identifier des modèles qui peuvent aider à la prise de décision. L’analyse diagnostique est utilisée pour rechercher les causes d’événements passés. Ce type d’analyse permet d’identifier les causes profondes des problèmes ou de diagnostiquer les problèmes pouvant affecter les performances de l’entreprise.
La construction d’un data warehouse selon l’approche « top-down » est découpée selon les étapes suivantes :
- Comprendre la stratégie de l’entreprise et les objectifs à atteindre par les données
- Définir les besoins de l’entreprise
- Concevoir l’architecture data
- Modéliser le data warehouse
- Implémenter le data warehouse
- Implémenter l’ingestion de données
- Implémenter les applications de BI
- Tester et optimiser le data warehouse
- Maintenir et superviser le data warehouse
Avec un DW, les solutions BI sont plus performantes et évolutives. Il permet d’intégrer plusieurs systèmes sources, de nettoyer ou de fusionner les données et de les préparer pour leur exploitation dans un outil BI.

Parmi les bénéfices apportés par le DW, on peut noter :
- Une stabilité du SI par la séparation des systèmes opérationnels et des systèmes analytiques ;
- Des performances élevées avec une base de données optimisée en lecture ;
- Un système analytique évolutif avec l’intégration de multiples sources de données ;
- La fiabilité des données dans les rapports induite par la centralisation et la forte structuration des données.

D’un autre côté, la mise en place d’un DW comporte quelques inconvénients :
- La conception et la mise en œuvre d’un DW peut être complexe : des profils experts sont nécessaires ;
- L’intégration des données à partir de différents systèmes peut être compliquée, nécessitant la mise en place d’un ETL (Extract, Transform, Load) avec des défis sur le traitement des formats de données, sur les structures différentes et sur les problèmes de qualité ;
- Un data warehouse propose des types d’analyses spécifiques, orientées BI. Pour répondre à d’autres besoins, des systèmes complémentaires doivent être intégrés dans l’architecture data.
Même si d’autres architectures ont émergé dans les dernières années pour répondre à tout type d’exploitation de données, le DW reste encore un élément fondamental de nombreuses architectures de données des entreprises.
Les principaux cas d’usage d’un DW sont :
- Analyse historique et tendance : stockage de données sur plusieurs années, identification des tendances, optimisation des stratégies.
- Business Intelligence (BI) et reporting : consolidation des données, génération de tableaux de bord, suivi des KPI ;
?️ Voici quelques technologies phares utilisées dans les DW classiques :
Teradata, IBM DB2 warehouse, MS SQL – SSAS.
Téléchargez la version complète de ce contenu, enrichie de ressources supplémentaires.
👉 Découvrez notre livre blanc « Quelle architecture data choisir pour votre entreprise ? »

2- Data lake – Définition, fonctionnement et cas d’usage
Le terme data lake est une métaphore qui décrit le concept de stockage de grandes quantités de données brutes dans leur format naturel. Une fois les données dans le data lake, elles doivent être nettoyées et agrégées pour les rendre utiles. Ces traitements sont appelés les transformations des données.
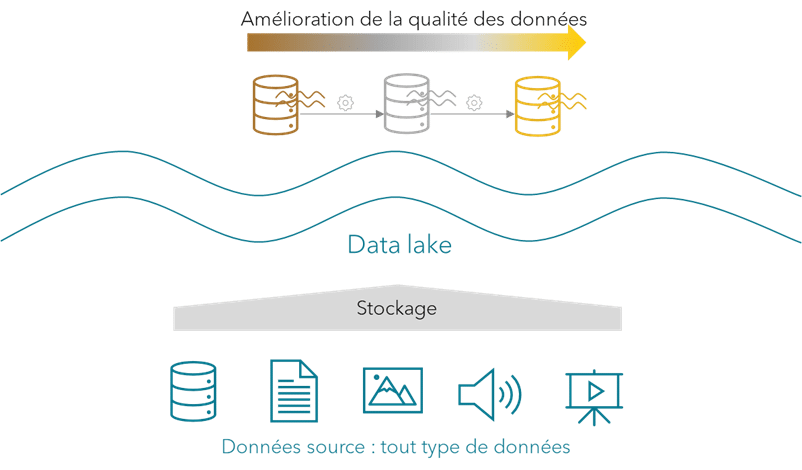
Un data lake permet d’accéder aux données rapidement. L’ingestion des données dans le data lake est simple puisqu’aucun traitement n’est nécessaire. Contrairement à un DW, les transformations sont exécutées à tout moment une fois les données dans le système de stockage. Ainsi, les data scientists ou les équipes data peuvent consulter les données dès que les transformations sont terminées.
Dans le cadre d’un data lake, l’approche utilisée est différente de celle du DW. On utilise une approche « bottom-up », c’est-à-dire qu’on collecte les données avant de les structurer selon un cas d’usage précis.
Au départ, les data lakes étaient principalement utilisés pour l’analyse prédictive (déterminer ce qui va se passer) et prescriptive (comment faire en sorte que cela se produise).
L’analyse prédictive utilise des données, des algorithmes statistiques et des techniques d’apprentissage automatique pour prédire des résultats futurs sur la base de données historiques. L’analyse prescriptive va plus loin que l’analyse prédictive. Elle utilise des algorithmes d’optimisation et de simulation pour donner des conseils sur les résultats possibles. L’analyse prescriptive ne se contente pas de prédire ce qui se passera à l’avenir, elle suggère également des actions à entreprendre pour influer sur ces résultats.
La modélisation d’un data lake est un processus complexe, souvent sous-estimé dans les entreprises. Vous pouvez suivre ces quelques bonnes pratiques présentées ci-dessous.
1- Diviser le data lake en plusieurs couches correspondant à des niveaux croissants de qualité des données.
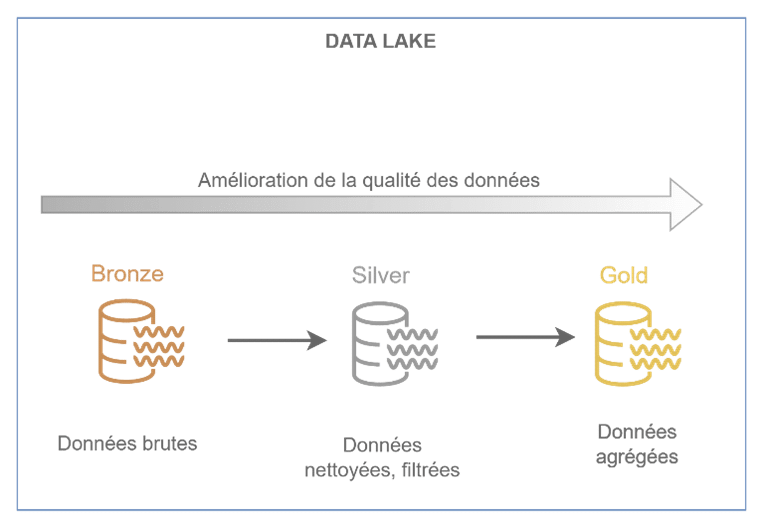
La couche bronze contient les données brutes dans leur état naturel et original (i.e. sans aucune transformation). Elles sont immuables et stockées en tant qu’historique. Cette couche peut également s’appeler staging ou raw layer.
La couche silver contient les données nettoyées, filtrées, consolidées. L’objectif est d’uniformiser les fichiers stockés en termes d’encodage, de schéma, de format, de types de données et de contenu. Cette couche peut également s’appeler cleansed layer ou processed layer.
La couche gold contient des données prêtes à être consommées par les utilisateurs finaux ou les applications. Une logique métier est appliquée aux données nettoyées, avec d’autres transformations comme des agrégations ou des résumés. Les fichiers peuvent être organisés selon une disposition spécifique pour les utiliser dans des outils de reporting ou de BI. Cette couche peut également s’appeler presentation, curated ou application layer.
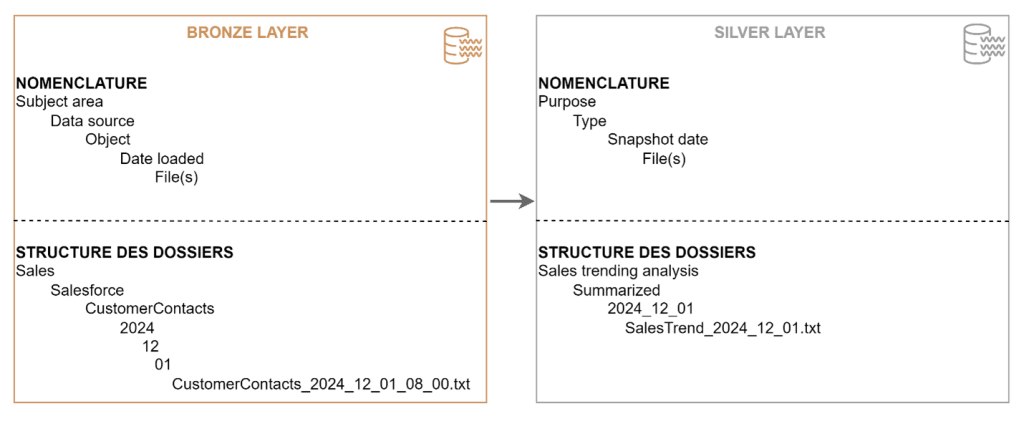
2. Créer une structure de dossiers pour chaque couche, selon différents critères, et mettre en place une nomenclature.
Les critères possibles sont : le jour et l’heure de l’ingestion, le domaine fonctionnel, la source de données, le département ou la business unit, et le niveau de sécurité.
Voici un exemple de modélisation du data lake pour les couches bronze et silver :
Les principaux avantages d’un data lake sont :
- Une mise à disposition des données plus rapide puisque les transformations peuvent être exécutées à tout moment.
- Un stockage économique : le coût de stockage est plus faible que pour le DW ;
- Un stockage illimité : les solutions cloud actuelles proposent de stocker une quantité illimitée et tout type de données ;
- La performance dans les transformations, avec des solutions techniques hautement performantes ;
Inconvénient du data lake :
Un des problèmes majeurs rencontrés avec les data lakes est la désorganisation du stockage des données. En effet, si elles ne sont pas organisées correctement, leur consultation et leur gestion devient difficile. Avec le temps, on se retrouve avec un « marécage de données » (ou « data swamp »), dans lequel les données sont de mauvaise qualité et inutilisables. Les entreprises peuvent se retrouver avec une masse de données inutiles sans savoir quelles informations sont fiables ou pertinentes. Dans ce cas, le data lake est difficile à maintenir et à utiliser.
Voici quelques cas d’usage d’un data lake :
- Machine learning et intelligence artificielle : utilisation des données pour l’entraînement de modèles prédictifs ou de modèles avancés.
- Stockage massif et centralisé : conservation des données structurées, semi-structurées et non structurées (logs, images, vidéos, IoT, etc) ;
- Exploration et analyse de données : accès aux données pour le data discovery ou des analyses exploratoires ;
?️ Les technologies phares pour un data lake sont :
Hadoop HDFS, AWS S3, Azure Data Lake Storage, Google Cloud Storage.
Vous souhaitez mettre en place un Datalake ? Rien de mieux qu’un cas concret pour bien préparer votre projet !
👉 Découvrez notre cas client « Mise en place d’un Data Lake full Cloud »

3- Modern Data Warehouse (MDW) – Définition, fonctionnement et cas d’usage
Le modern data warehouse est la combinaison d’un data lake et d’un DW, permettant de créer une solution d’analyse de données robuste avec de la flexibilité dans l’intégration des données.
Voici le cycle de vie des données dans une architecture MDW :
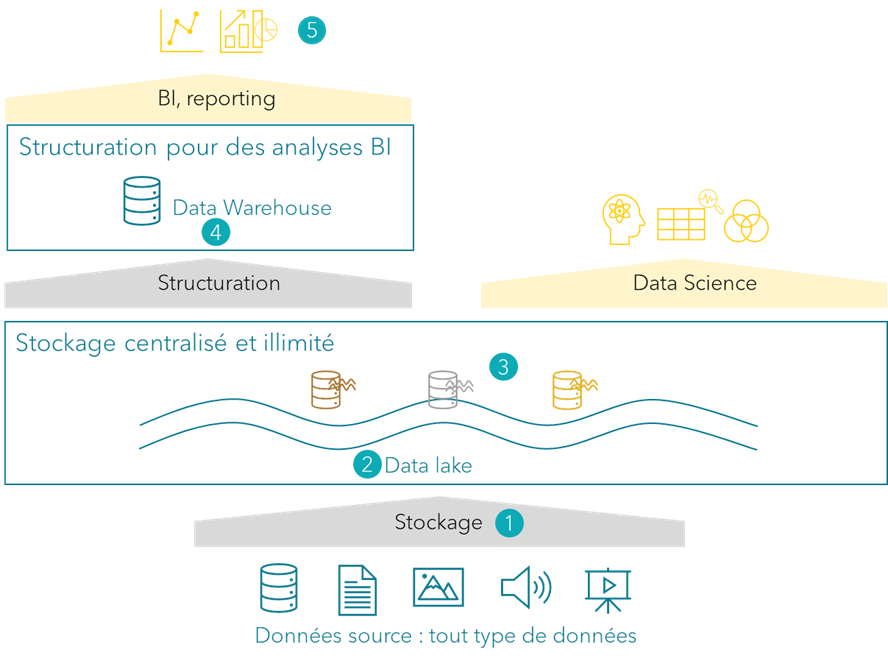
1.
Ingérer les données
Un MDW peut traiter n’importe quel type de données ; elles peuvent être intégrées par lot à fréquence régulière ou en temps réel.
2.
Stocker les données
Après ingestion, les données sont stockées dans la couche bronze comme expliqué précédemment. Le MDW utilisant un data lake, le stockage est illimité et à faible coût.
3.
Transformer les données
L’essence d’un data lake est d’être un centre de stockage. Toutefois, pour donner un sens aux données et les exploiter, il faut les transformer. Ceci est possible grâce aux ressources « compute » du data lake.
Un des principaux avantages du MDW est qu’il y a une séparation claire entre le stockage et le traitement des données. Ainsi, on peut adapter à tout moment les capacités de traitement selon le besoin.
Par ces traitements, on va construire les couches silver et gold, telles que présentées précédemment.
4.
Structurer les données
Les données sont copiées et structurées dans un DW permettant d’avoir des analyses performantes même dans des grandes volumétries de données.
5.
Visualiser les données
Une fois que les données sont dans le DW dans un format facile à comprendre, les utilisateurs peuvent les consulter et les analyser avec des outils de reporting ou BI.
Voici quelques avantages du MDW :
- Des analyses performantes.
- La simplicité de déploiement et l’infrastructure entièrement managée, offerte par des solutions cloud comme Snowflake, Google BigQuery, AWS Redshift ou Azure Synapse Analytics, éliminant ainsi les contraintes de gestion ;
- L’intégration d’une grande variété de sources de données ;
- La scalabilité du socle technique en s’adaptant à l’augmentation du volume des données ;
- Des analyses en temps réel ;
Malgré ces avantages, l’architecture MDW présente quelques inconvénients :
- Une gouvernance des données plus compliquée : avoir 2 copies de données dans 2 systèmes de stockage différents, avec 2 types de sécurité différents augmente le risque d’accéder à des données non autorisées.
- Fiabilité : maintenir la cohérence entre le data lake et un DW peut être un problème, en particulier si de grandes quantités de données doivent être copiées. Si les tâches de copie échouent, il peut y avoir un problème de fiabilité entre le data lake et le DW.
- Rafraîchissement des données : les données d’un DW sont plus « anciennes » que celles du data lake. La fréquence de rafraîchissement des données doit être bien ajustée pour garantir des données les plus fraîches possible sans perturber leur consultation.
- Coût total de la plateforme : le calcul et le stockage nécessaires pour le DW entraînent des coûts supplémentaires, sans compter les coûts des ressources nécessaires pour maintenir ce système.
- Complexité de mise en œuvre et de maintenance : la multiplication des composants dans un système augmente sa complexité. Des process et une organisation adéquate devront être mis en place pour garantir une bonne gestion.
Remarque : la gouvernance des données a commencé à devenir un point central à partir des années 2000, bien qu’elle soit devenue incontournable à partir des années 2010 avec l’arrivée du big data et des réglementations.
Actuellement, la gouvernance des données est considérée comme une composante stratégique essentielle pour créer de la valeur à partir des données, garantir leur sécurité et leur confidentialité, et réduire les risques juridiques.
Pour plus d’information, vous pouvez consulter notre article : « C’est quoi la gouvernance des données en entreprise ? »
Voici quelques cas d’usage d’un modern data warehouse :
- Machine learning et intelligence artificielle : exploitation des données pour entraîner des modèles de machine learning ou d’IA.
- Business intelligence (BI) et reporting : analyses avancées, tableaux de bord interactifs, suivi de KPI.
- Analyse rapide avec des données à jour : traitement rapide des données pour des prises de décision instantanées.
?️ Les technologies phares pour un MDW sont :
AWS Redshift, Azure Synapse Analytics, Google BigQuery et Snowflake..
Les problèmes de gouvernance des données ne sont pas une fatalité !
👉 Découvrez notre livre blanc « Gouvernance des données : guide pratique en 8 étapes clés »

4- Data fabric – Définition, fonctionnement et cas d’usage
La data fabric étend les capacités d’un modern data warehouse. En réalité, ils sont complémentaires : la data fabric peut intégrer les données du MDW avec d’autres sources, sans nécessiter un stockage physique central, pour offrir une vue unifiée des données.
Voici quelques différences entre un modern data warehouse (MDW) et une data fabric :
| MDW | Data fabric | |
|---|---|---|
| Définition | Plateforme centralisée de stockage et d’analyse des données. | Architecture distribuée et intelligente pour gérer des données hétérogènes et réparties. |
| Objectif | Centraliser et optimiser l’accès aux données analytiques pour des cas d’usage spécifique (BI, reporting, data science). | Fournir un accès unifié et intelligent aux données en automatisant leur découverte, leur intégration et leur gouvernance. |
| Architecture | Centralisée. | Distribuée et dynamique. |
| Accès aux données | Les données sont physiquement déplacées vers le data lake et le DW. | Les données restent in situ. Une consolidation des données grâce à la virtualisation des données. |
| Cas d’usage typiques | BI, tableaux de bord analytiques, machine learning. | Intégration et gouvernance des données dans des environnements complexes. Automatisation des flux de données pour l’analytique et les processus opérationnels en temps réel. |
| Flexibilité et mise à l’echelle | Bonne scalabilité pour des besoins analytiques centralisés. Moins flexible lorsqu’il s’agit de gérer des données hétérogènes. | Adapté aux environnements dynamiques. Très flexible et adapté aux sources multiples. |
Selon Gartner, « une data fabric, dans sa forme la plus simple, recueille les métadonnées des systèmes et des utilisateurs. Elle les analyse pour produire des alertes et des recommandations afin de mieux organiser, intégrer, apporter du sens et utiliser les données tout en améliorant l’expérience utilisateur et les résultats de l’entreprise. »
Voici l’architecture d’une data fabric :
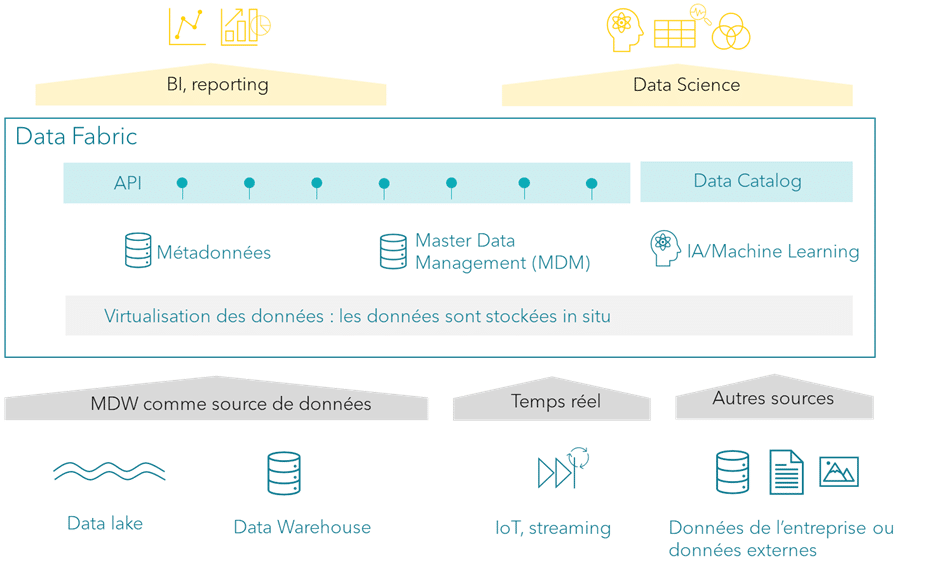
Une analogie simple peut être faite au niveau de l’entreprise :
- Avec plusieurs entrepôts spécialisés (sources de données) : pièces détachées, produits finis, matières premières qui fonctionnent de manière isolée, sans communication fluide.
- Gérer une commande nécessitant des articles de plusieurs entrepôts (cas d’usage client, par exemple des analyses complètes en temps réel, de la BI) implique de contacter chaque site, de coordonner les livraisons, et de gérer les éventuels retards ou erreurs.
- Pour faciliter cette gestion, l’entreprise met en place un système logistique intelligent (data fabric) reliant tous les entrepôts, offrant une vue unifiée des stocks et organisant automatiquement la collecte, l’expédition et le réapprovisionnement.
Voici quelques caractéristiques clés d’une data fabric :
- Une politique claire d’accès aux données, avec la définition et la mise en place d’un plan de gouvernance sur la conformité et la sécurité des données ;
- Un catalogue de métadonnées, avec le stockage centralisé des métadonnées (informations sur les données) et le data lineage (traçabilité d’une donnée depuis son origine, ses transformations, jusqu’à son point de stockage) ;
- Du master data management (MDM). Le MDM est le processus de collecte, de consolidation, de mise à jour et de validation de la cohérence des données de référence pour créer une unique source de vérité. Les données de référence concernent les entités clés d’une entreprise comme les clients, les produits, les fournisseurs, les employés ;
- De la virtualisation des données. Ceci consiste à créer une couche intermédiaire entre les sources de données et les consommateurs de données (utilisateurs ou applications) permettant d’accéder aux données facilement, comme si elles étaient stockées dans un point central ;
- Du traitement en temps réel. Ceci consiste à traiter des données et à produire des résultats immédiats, basés sur des informations actualisées ;
- Des API pour standardiser et sécuriser la consultation des données ;
- Orienté produit. Si les données sont destinées à être vendues, la data fabric peut être construite comme un produit à part entière.
La data fabric offre plusieurs avantages :
- Une gestion des données simplifiées car pas de duplication.
- Une intégration facile des systèmes et un accès unifié aux données ;
- La flexibilité et l’évolutivité de la plateforme data ;
- Une consultation des données en « self-service » ;
Comme toute architecture, la data fabric a également quelques inconvénients :
- Des changements culturels, tournés vers une culture axée sur les données, sont essentiels pour adopter une data fabric et tirer parti de tous les avantages proposés par cette architecture. Ces changements concernent des rôles et des responsabilités data, des processus clairs pour favoriser la collaboration entre les équipes et une utilisation généralisée des données.
- La complexité de mise en œuvre car elle nécessite une grande expertise aussi bien technique que sur la gouvernance de données ;
- Des défis dans l’intégration des données avec des formats et des structures de données multiples ;
- Le coût élevé des solutions complètes et des ressources avec les compétences nécessaires ;
Une data fabric offre une solution puissante pour gérer et unifier les données dans des environnements complexes, mais son adoption exige une gestion continue et un fort accompagnement au changement.
Voici quelques cas d’usage d’une data fabric :
- Accès aux données en self-service : mise à disposition des données pour les équipes métier sans intervention de l’équipe Data ou IT.
- Intégration et unification des données : connexion fluide entre sources de données hétérogènes (cloud, on-premise, bases SQL/NoSQL etc.) ;
- Données unifiées et actualisées : fourniture d’une vue unifiée et actualisée des données pour une prise de décision rapide dans un environnement complexe ;
?️ Les technologies phares pour une data fabric sont :
IBM Data Fabric, Informatica IDMC, Talend Data Fabric, Microsoft Fabric, Google Dataplex.
5- Data lakehouse – Définition, fonctionnement et cas d’usage
Le data lakehouse est apparu avec la volonté d’avoir une plateforme unique et unifiée, en combinant les atouts d’un data lake et d’un data warehouse. Cette architecture a été conçue par Databricks en 2020 qui reste toujours le leader sur ce type de plateforme.
Avec la combinaison des deux approches, on obtient :
- Un stockage centralisé des données, scalable et économique ;
- Et une structure et une gouvernance des données pour l’analyse.
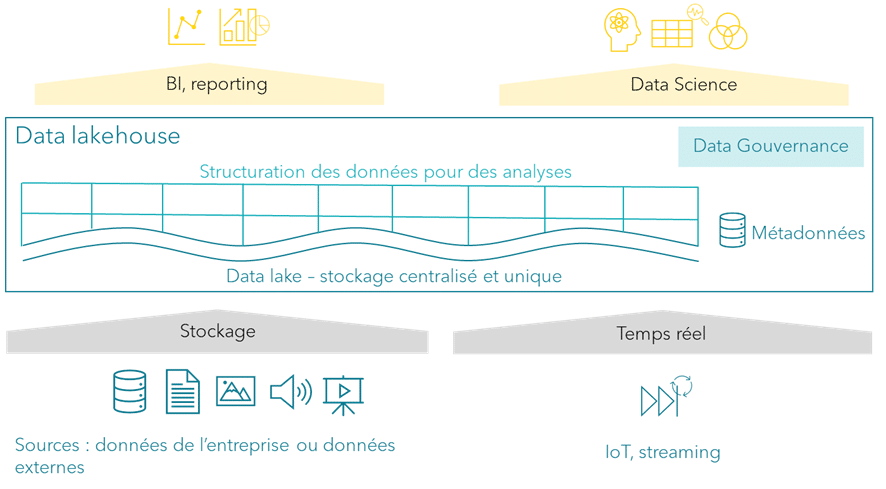
Dans cette architecture, on a :
- Un stockage unifié basé sur un format standardisé ;
- Un format de données optimisé permettant des opérations transactionnelles comme dans un data warehouse ;
- Un moteur de calcul performant pour exécuter des requêtes analytiques directement sur les données stockées ;
- Une gouvernance améliorée avec un framework de gouvernance pour gérer les droits d’accès et assurer la qualité ;
- Une flexibilité dans les données traitées, avec la prise en charge de tous les types de données.
Le data lakehouse repose sur l’architecture en médaillons qui organise les données en trois couches pour améliorer leur qualité, comme présenté dans la partie data lake :
- Bronze pour les données brutes ;
- Silver pour les données nettoyées et enrichies ;
- Gold pour les données prêtes à l’analyse et à la consommation métier.
Cette architecture apporte des améliorations par rapport à un MDW :
- Gouvernance simplifiée : le lakehouse propose une gouvernance centralisée, avec des politiques de sécurité et de gestion des données uniformes.
- Simplification de l’architecture pour une maintenance plus facile : contrairement à un MDW qui nécessite deux systèmes distincts, le data lakehouse combine les deux dans une seule plateforme. Ceci réduit la complexité et facilite la maintenance ;
- Réduction du coût : le data lakehouse utilise un stockage économique, similaire à un data lake, sans devoir dupliquer les données dans un DW. Ceci réduit les coûts de stockage et de gestion liés au DW ;
- Données plus fraîches et accessibles : dans un MDW, les données du DW sont moins récentes à cause des processus d’intégration. Dans le lakehouse, les analyses étant réalisées directement sur le data lake, les données sont fraîches ;
Le data lakehouse permet donc d’avoir une plateforme unifiée pour traiter des cas d’usage modernes, comme les analyses en temps réel ou l’apprentissage automatique, dans un contexte big data.
Cependant, quelques inconvénients subsistent :
- La mise en place d’un data lakehouse reste complexe, nécessitant des compétences techniques élevées.
- Son apparition est récente et, bien qu’elle montre un fort potentiel, elle n’est pas totalement mature pour toutes les entreprises ou tous les cas d’usage.
Voici quelques cas d’usage d’un data lakehouse :
- Accès aux données en self-service : mise à disposition des données actualisées pour les équipes métier afin de créer leurs propres analyses.
- Analyse en temps réel et historique : accès aux données pour des analyses en temps réel et sur des données historiques ;
- Data science et intelligence artificielle : analyses exploratoires et entraînement des modèles de machine learning et IA avec des données provenant de sources variées ;
?️ La technologie phare pour un data lakehouse est :
Databricks.
Cependant, certains MDW ont évolué ces dernières années pour tendre vers un data lakehouse comme Snowflake. Chez les cloud providers publics (AWS, Azure, GCP), on peut trouver un ensemble de services permettant de construire une architecture de ce type.
Vous avez un projet d’intelligence artificielle ?
👉 Découvrez notre guide d’une IA décomplexée pour votre entreprise !

6- Data Mesh – Définition, fonctionnement et cas d’usage
Traditionnellement, les entreprises utilisent des architectures centralisées comme les data warehouses ou les data lakes. Ces modèles centralisent toutes les données dans un seul endroit. Bien que pratique, cela crée souvent des problèmes :
- Goulots d’étranglement dans les équipes centralisées ;
- Mauvaise qualité ou lenteur d’accès aux données ;
- Difficulté à évoluer avec la croissance des données.
Le data mesh, conçu par Zhamak Dehghani (CEO et fondatrice de Nextdata) en 2019, propose une alternative décentralisée pour résoudre ces problèmes.
Le data mesh repose sur quatre principes clés :
1.
Décentralisation par domaine
Les données sont gérées par les équipes ou départements qui les produisent et les utilisent. Ces équipes sont appelées des « domaines« . Exemple : l’équipe Marketing gère ses données clients, tandis que l’équipe Finance gère ses données de facturation.
2.
Données comme produit (data product)
Chaque domaine considère ses données comme un produit qu’il partage avec le reste de l’entreprise. Par exemple : les données doivent être documentées, fiables et faciles à consommer.
3.
Plateforme data self-service
Pour que chaque domaine puisse gérer ses données facilement, l’entreprise fournit des outils et des infrastructures standardisés (comme des pipelines de données, des outils d’analyse ou des catalogues). Ces outils permettent aux équipes de se concentrer sur leurs données.
4.
Gouvernance fédérée
Même si la gestion est décentralisée, il y a des règles globales pour garantir la sécurité, la conformité et l’interopérabilité. Par exemple, des standards pour les formats de données ou la gestion des accès.
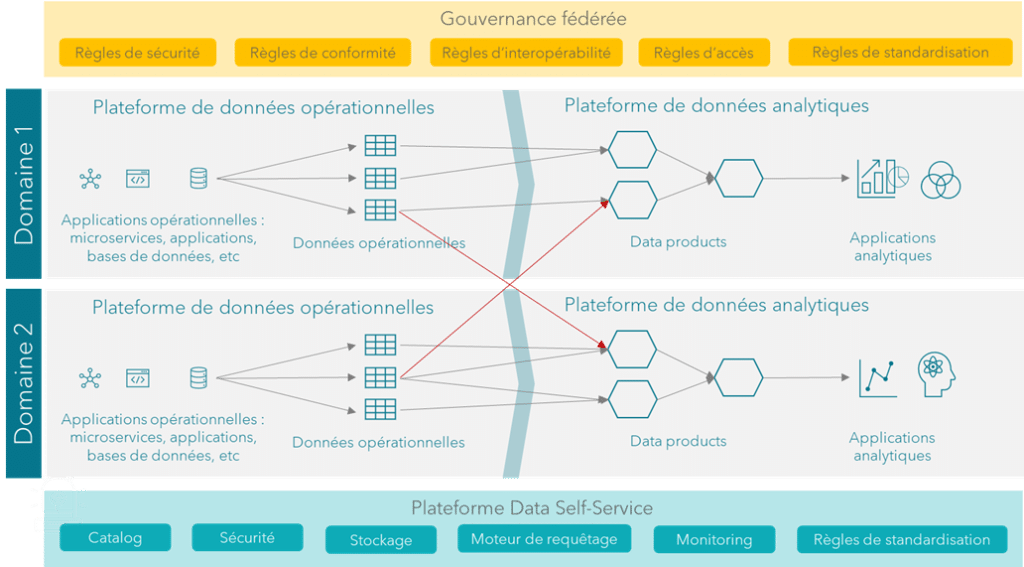
Une analogie simple peut être une ville où :
- Chaque quartier (domaine) gère ses routes locales et ses infrastructures (ses données) ;
- La mairie fournit des règles globales (gouvernance) et des services comme l’eau ou l’électricité (plateforme self-service) ;
- Les routes entre les quartiers sont bien connectées pour faciliter la circulation (interopérabilité des données).
Dans un data mesh, la connaissance métier est essentielle pour garantir la pertinence, la qualité et la gouvernance des données. Chaque domaine étant responsable de ses produits de données, une bonne compréhension métier permet de structurer, standardiser et partager efficacement les informations. Elle favorise également l’interopérabilité entre domaines et permet aux équipes métier d’être plus autonomes dans l’exploitation des données.
Les principaux avantages de ce type d’architecture sont :
- La qualité : les données sont mieux maintenues car elles sont vues comme un produit.
- L’efficacité : les équipes qui connaissent les données les gèrent directement, évitant les goulots d’étranglement ;
- L’évolutivité : chaque domaine peut évoluer indépendamment ;
Les défis à remonter sont :
- La mise en place d’une plateforme self-service robuste peut demander beaucoup de travail.
- La nécessité d’un changement culturel important dans l’entreprise ;
- Les équipes doivent apprendre à gérer leurs propres données et à maîtriser les impacts d’un ajout, d’une suppression ou d’une modification des données dans les autres domaines ;
Le data mesh est une transformation majeure dans la manière de penser et de structurer les données en entreprise. En abandonnant l’approche centralisée des data warehouses et des data lakes traditionnels, il s’adapte aux défis des entreprises où l’accès aux données est de plus en plus complexe et fragmenté.
Grâce à sa décentralisation par domaine, le data mesh responsabilise les équipes qui créent et utilisent les données, en leur offrant la flexibilité de les gérer comme un produit de qualité. Cela encourage une collaboration plus efficace, tout en assurant une meilleure réactivité face aux besoins des utilisateurs finaux. Par ailleurs, l’introduction d’une plateforme self-service et d’une gouvernance fédérée garantit que les standards de sécurité, de conformité et d’interopérabilité restent solides à l’échelle de l’entreprise.
Cependant, réussir une transition vers le data mesh ne se limite pas à une simple mise en œuvre technologique. Il s’agit d’un changement culturel qui nécessite des investissements dans les outils, les compétences et les processus. Les entreprises doivent accepter que cette transition représente un effort progressif, avec des bénéfices qui se manifesteront au fil du temps, une fois que l’écosystème sera mature.
En résumé, une architecture data mesh offre une agilité et une scalabilité essentielles dans un contexte où les données jouent un rôle central dans l’innovation. Bien qu’elle ne convienne pas à toutes les entreprises ou à tous les cas d’usage, elle constitue une approche efficace pour celles qui souhaitent maximiser la valeur de leurs données tout en répondant aux enjeux de décentralisation et de collaboration.
Voici quelques cas d’usage d’un data mesh :
- Optimisation organisationnelle : traitement des données dans chaque domaine réduisant les goulots d’étranglement.
- Amélioration de la scalabilité des données : gestion des données à grande échelle particulièrement adaptée aux grandes entreprises avec des équipes et des données distribuées ;
- Interopérabilité entre domaines métier : échange de données de qualité entre les différentes équipes métier ;
Analyse descriptive, Batch processing, Datalake, Deep learning, IoT…Envoie d’un glossaire complet sur le Big DATA ?
👉 Découvrez notre glossaire « Big Data : le lexique à connaître »

Comparatif des différentes architectures Data
| Critères | DW | Data lake | MDW | Data fabric | Data lakehouse | Data mesh |
|---|---|---|---|---|---|---|
| Typologie d’architecture | Centralisée, structurée. | Centralisée, stockage brut. | Combinaison de data lake + data warehouse. | Connectée, intégration multisource. | Centralisée (stockage + capacité analytique). | Décentralisée, orientée domaine. |
| Cas d’usage principal | Analyses BI sur données structurées. | Stockage de données massives non structurées. | Analyses avancées et stockage hybride. | Unification des données pour analyses complexes. | Analyses avancées sur données multiformats. | Collaboration inter-équipes pour analyses. |
| Complexité (mise en œuvre et maintenance) | Moyenne (infrastructure mature et bien documentée). | Faible pour le stockage, mais élevée pour l’analyse. | Élevée (gestion de deux systèmes simultanés). | Élevée (orchestration et intégration complexes). | Moyenne (plateforme unifiée simplifiée). | Élevée (changement organisationnel important). |
| Fiabilité | Très élevée (mature et robuste). | Moyenne (problèmes de « data swamp » possibles). | Bonne (fiabilité dépendant de la synchronisation). | Très élevée (outils modernes et automatisation). | Très élevée (sécurité et cohérence intégrées). | Variable (dépend de la mise en œuvre par domaine). |
| Coût | Élevé (infrastructure optimisée mais coûteuse). | Faible (stockage économique). | Élevé (dédoublonnage de coûts entre DW et data lake). | Élevé (investissements en intégration nécessaires). | Moyenne (réduction des systèmes). | Variable (scalabilité selon les domaines). |
| Gouvernance | Centralisée et mature. | Complexe, nécessite des outils additionnels. | Complexe (deux systèmes avec des règles distinctes). | Centralisée et automatisée. | Centralisée et simplifiée. | Décentralisée, dépendante des équipes. |
| Organisation | Équipe Data centralisée, avec des compétences BI et ETL. | Équipe Data technique, focalisée sur l’ingestion et la gestion du stockage. Compétences big data. | Équipe Data élargie, combinant des compétences big data et BI. | Équipe Data spécialisée, avec des compétences avancées en orchestration, API, automatisation. | Équipe Data mixte, équilibrée entre expertise big data et analytique. | Équipes Data décentralisées, orientées par domaine métier. Nécessite un data product owner et des compétences techniques dans chaque domaine. |
Vous avez besoin d’accompagnement pour mettre en place votre architecture data ?
👉 Découvrez un exemple d’accompagnement dans le secteur des services financiers et des paiements.

Conclusion
Ces dernières années, plusieurs changements majeurs ont transformé le paysage des architectures data. L’explosion des volumes de données et la diversité croissante de leurs formats ont imposé des solutions capables de gérer des données non structurées et des flux en temps réel. La montée en puissance du cloud a également bouleversé les approches traditionnelles, rendant les infrastructures plus flexibles et accessibles. Par ailleurs, l’émergence de concepts comme le data mesh et la data fabric reflète une volonté de dépasser les silos et de rapprocher les données des équipes métiers.
À l’avenir, les architectures data évolueront vers encore plus d’automatisation, avec l’intégration de l’intelligence artificielle pour optimiser la gestion des données et accélérer leur valorisation. Une attention croissante sera portée à la gouvernance et à l’éthique des données, alors que les entreprises s’efforceront de répondre à des exigences réglementaires de plus en plus strictes.
Les tendances actuelles du marché montrent que la gestion des données progresse vers :
- Un MoveToCloud massif : les entreprises migrent de plus en plus vers des architectures cloud-native, adoptant des solutions modulaires et évolutives pour répondre à des besoins dynamiques ;
- Une fusion des modèles architecturaux : des approches comme le data lakehouse gagnent en popularité grâce à leur capacité à concilier les avantages des architectures traditionnelles (data warehouse) et modernes (data lake) ;
- Une gouvernance et une sécurité renforcées : les exigences réglementaires et les préoccupations croissantes en matière de confidentialité poussent les organisations à adopter des politiques solides de gouvernance et de protection des données ;
- L’adoption de l’IA générative : l’arrivée de l’IA générative bouleverse les pratiques data, permettant de créer de nouveaux usages comme l’automatisation de processus complexes ou la personnalisation des expériences utilisateur. Cette technologie exige cependant des architectures data prêtes à gérer des volumes massifs de données et de qualité.
- Une décentralisation organisée : le data mesh, bien que complexe à mettre en œuvre, répond à la nécessité de responsabiliser les équipes tout en évitant les goulots d’étranglement centralisés et en promouvant une scalabilité organisationnelle.
Êtes-vous certain de valoriser et exploiter au maximum
vos données d’entreprise ?
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.


Pas encore de commentaires