
Au travers de cette série d’articles, nous avons découvert un grand écosystème de méthodes pour faire du RAG avec leur lot d’avantages et d’inconvénients. Le but de cet article est de présenter la méthodologie mise en place au sein de la cellule Innovation de Meritis pour travailler sur ce sujet du RAG. Entre travail de recherche et travail de développement, plongez avec nous dans la quête du RAG rapide et efficace.
Vous n’avez pas encore lu le premier article de la série consacrée au RAG ??Découvrez notre article précédent dédié au concept et au fonctionnement des RAG

Dans la cellule innovation, cela va bientôt faire deux mois que ces problématiques de RAG sont devenues notre quotidien, particulièrement celles concernant les GraphRAG. La méthode est séduisante sur le papier mais semble perfectible dans les faits. Nous avons donc essayé d’adapter la philosophie Microsoft GraphRAG à certaines contraintes en proposant une alternative : le Multi-GraphRAG.
L’alternative Multi-GraphRAG par Meritis
Pour y parvenir, nous avons dû travailler sur un certain nombre de paramètres tels que les modèles, la pertinence des réponses locales ou les temps d’inférence.
Pour les modèles, l’idée était de comparer la méthode GraphRAG sur différents LLM. Objectif : identifier lesquels sont efficaces et surtout à partir de quelle taille un modèle est suffisamment performant pour des tâches de GraphRAG.
Concernant la pertinence des réponses locales, comme l’expliquait notre précédent article, le GraphRAG Microsoft[VC1] est particulièrement efficace pour la synthèse de texte mais beaucoup moins pour la recherche d’informations précises. C’est pourquoi il faut modifier certaines étapes pour obtenir un RAG efficace au sens classique du terme RAG.
Enfin, l’enjeu au niveau des temps d’inférence, était de réussir à obtenir des résultats similaires voire supérieurs au GraphRAG avec un temps d’inférence – soit le temps d’attente utilisateur – bien moindre.

GraphRAG et Multi-GraphRAG : un travail de comparaison
Lorsqu’on veut utiliser plusieurs modèles de langage, il faut jouer selon leurs règles. Chaque LLM demande une syntaxe de prompts particulière. Par conséquent, un prompt qui marche bien avec Mistral ne fonctionne pas forcément avec Gemma ou Llama. Il faut alors s’adapter pour obtenir des sorties informatiquement exploitables au risque de perdre de l’information.
Dans un premier temps, l’idée était de garder une phase d’indexation très proche de celle de Microsoft, en réduisant au maximum le nombre de tokens d’entrée (taille des prompts et nombre d’appels LLM), et de réellement tabler sur le temps d’inférence notamment au niveau de la Global Search.
Les principales différences méthodologiques à noter sont :
- La fusion de l’étape d’extraction et de description, permettant ainsi de diviser par deux le nombre d’appels LLM sur la première partie de la phase d’indexation ;
- L’utilisation d’un seul niveau hiérarchique permettant quant à lui de réduire le nombre d’appels LLM ;
- Et la présence d’un préfiltre par embedding sur la Global Search pour réduire le temps d’inférence.
Comment nous avons testé les résultats obtenus par notre Multi-GraphRAG
Pour tester nos résultats, nous avons créé un data set recensant onze articles sur les Jeux Olympiques de Paris et associé à trente questions. Il était important de choisir un sujet sur lesquels les LLM n’étaient pas encore entraînés pour être sûr que les réponses soient bien enrichies par notre RAG.
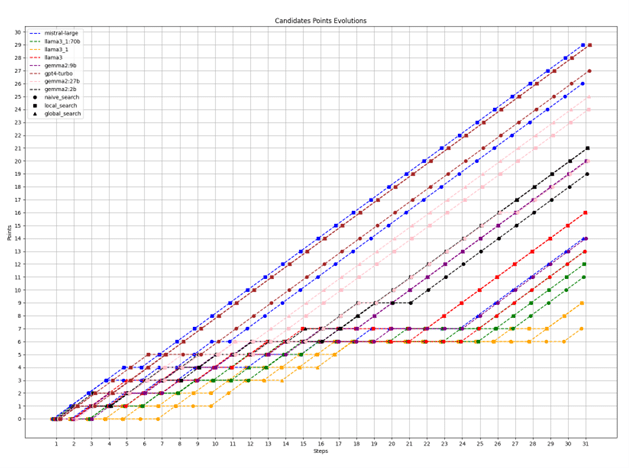
Nous avons testé les modèles suivants : Llama3 : 8b, Llama3.1 : 8b, Llama3.1 : 70 b, Gemma2 : 2b, Gemma2 : 9b, Gemma2 : 27b, Mistral-large et GPT-4 Turbo. Ces modèles ont été mis en compétition selon les règles suivantes :
- Chaque modèle a sa déclinaison RAG Naive, GraphRAG Local et GraphRAG Global ;
- La compétition dure trente tours où chaque tour représente des duels entre LLM ;
- Sur chaque duel 11 questions sur les 15 sont tirées aléatoirement ;
- Un LLM – en l’occurrence GPT-4 Turbo dans cette étude – juge pour chaque question quel modèle a donné la réponse la plus pertinente ;
- À chaque tour, un modèle affronte le modèle le plus proche de lui en nombre de points et qu’il n’a encore jamais rencontré ;
- Une défaite n’offre aucun point tandis qu’une victoire est associée à une récompense équivalente à un point.
Les résultats ont montré trois points particulièrement intéressants :
- Taille des modèles : généralement, plus un modèle a de paramètres, plus ses réponses sont pertinentes.
- Efficacité des méthodes : généralement, les GraphRAG Local Search sont autant voire plus efficaces que les Naive Search à modèle équivalent. La Global Search peine à répondre à des questions précises.
- Les modèles Gemma : les modèles développés par Google semblent performer dans les tâches requises pour faire tourner une méthodologie type GraphRAG.
Vers une nouvelle version du RAG
Après avoir analysé ces résultats et testé le code de Microsoft sur le même data set, la conclusion sans équivoque et plutôt réjouissante est que les résultats obtenus sont sensiblement les mêmes que ceux donnés par Microsoft pour un nombre de tokens bien moins importants.
La conclusion moins sympathique, c’est que les résultats ne sont pas toujours au rendez-vous et que la différence entre un RAG Naive et une Local Search de GraphRAG n’est pas toujours transcendante.
Attention au manque de contexte
Un des problèmes identifiés est celui du manque de contexte dans certaines réponses locales. En effet, imaginons que l’entité « Léon Marchand » soit détectée dans plusieurs textes de notre data base sur les JO : elle ne formera finalement qu’un seul point dans le graphe et donc n’appartiendra qu’à une seule communauté, ce qui peut s’avérer une mise en contexte trop restrictive.
Un autre problème est la présence d’entité intrinsèque à un texte, c’est-à-dire que si on a un texte sur Michael Phelps et un texte sur Léon Marchand, les deux peuvent être désignés par l’appellation « nageur » qui formera une seule entité du graphe alors qu’elle désigne, en réalité, deux entités distinctes.
Finalement, un dernier problème est la détection d’entité dans la Local Search qui semble parfois ne pas être la bonne solution. En effet, imaginons la situation suivante :
- Requête : « quel nageur français est originaire de la ville rose ? »
- Entités du graphe qu’on aimerait retrouvées : « Léon Marchand » et « Toulouse »
- Description des entités : « nageur français quadruple médaillé d’or aux Jeux de Paris » et « ville d’origine de Léon Marchand, surnommée la ville rose »
- Entités détectées dans la requête : « nageur français » et « ville rose »
Ce petit exemple montre que, parfois, ce n’est pas l’entité qu’on veut extraire dans la requête mais bien la description de l’entité.
![[Livre Blanc] Intelligence artificielle : guide d’une IA décomplexée pour votre entreprise](https://meritis.fr/wp-content/uploads/2022/08/diapositive4.jpg)
Le saviez-vous ? 85 % des projets d’intelligence artificielle échouent, et ce alors que plus de 7 entreprises sur 10 sont engagées dans des projets IA ?
👉 Découvrez les clés du passage à l’échelle de votre projet d’Intelligence Artificielle
Téléchargez notre guide pour répondre à vos questions :
- Par où commencer ?
- Quels prérequis mettre en place pour passer en production ?
- Quel algorithme utiliser ?
- Comment implémenter son modèle ?
Mise en place d’une version Multi-GraphRAG
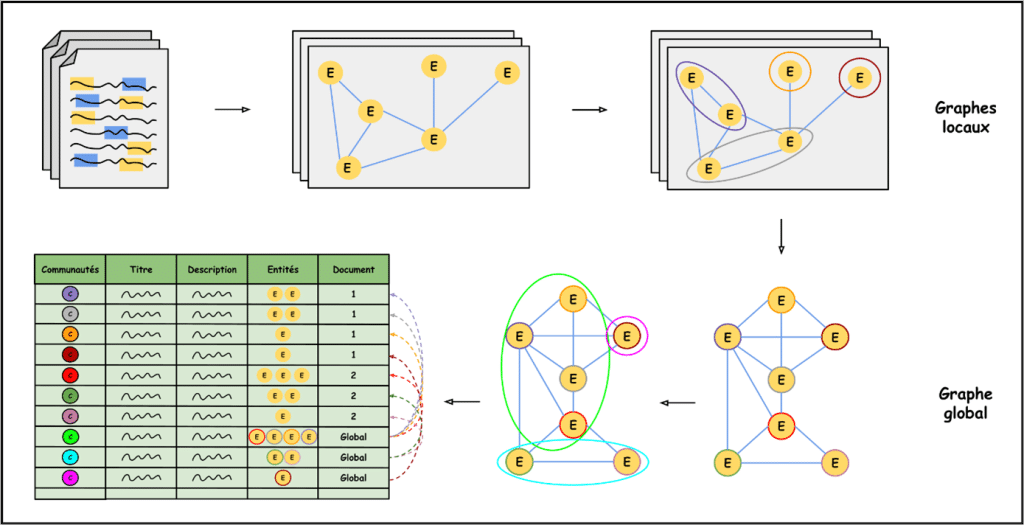
Pour résoudre ces problèmes, nous avons décidé de ne pas faire un seul graphe englobant tous les documents, mais de faire un graphe par document. Cette idée permet de pallier le problème des entités intrinsèques aux documents ne donnant qu’un seul point dans un graphe global.
Désormais, si l’entité « nageur » est détectée, elle deviendra un nœud dans un graphe attaché au document, ce qui permet de réduire les confusions. Cependant, cela engendre une problématique pour des requêtes dont la réponse implique un contexte qui croise plusieurs documents.
Comment lier les documents entre eux ?
Il faut trouver une idée permettant de lier les documents entre eux et cette idée, c’est celle de voir chaque communauté comme un point d’un graphe plus gros au-dessus de tous les autres graphes.
On aurait donc des graphes locaux, c’est-à-dire des graphes de connaissances associés à chaque document, et un graphe global où les nœuds seraient les communautés identifiées dans les différents graphes locaux.
Pour ce faire, nous devons fixer une règle pour les arrêtes, c’est-à-dire un principe pour savoir si deux communautés – donc deux nœuds du graphe global – sont reliées et avec quel poids. Quelle est alors cette règle choisie de façon empirique ? Il s’agit de relier ces deux communautés si elles font partie du même document ou si elles ont une entité en commun. Le poids de l’arc est alors le nombre d’entités communes aux deux communautés auquel on ajoute « 1 » si les communautés proviennent du même document.
Des méthodes de récupération adaptées
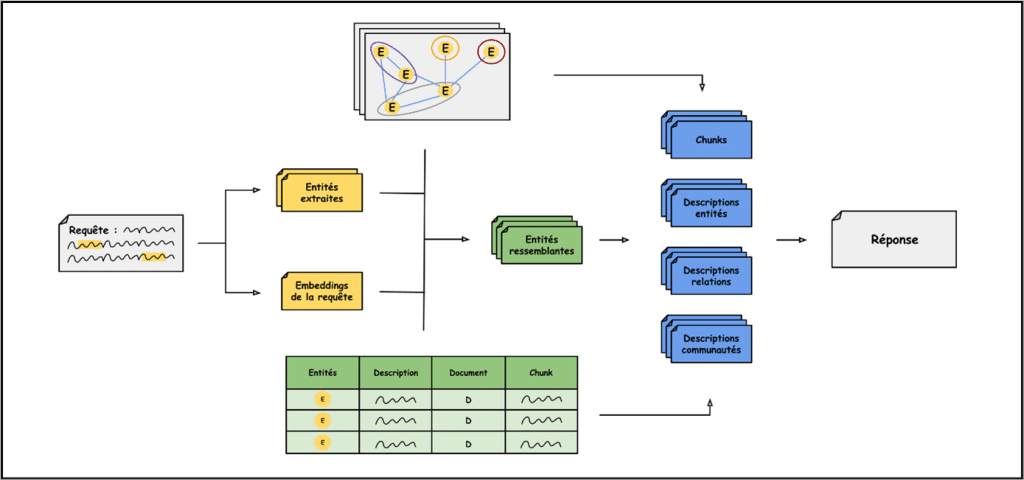
Une fois notre indexation réalisée de la manière décrite dans la section précédente, il ne nous restait plus qu’à récupérer les informations de manière intelligente dans cette forêt de graphes. Lorsqu’une requête arrive, un LLM est appelé pour extraire les entités présentes.
La Local Search Meritis
Ensuite, ces entités provenant de la requête sont vectorisées pour être comparées avec les entités des graphes locaux. Les entités les plus ressemblantes – en pratique les deux entités les plus proches dans l’espace post-embedding pour chaque entité provenant de la requête – deviennent les nœuds de départ pour notre Local Search.
En parallèle, la requête tout entière est également vectorisée pour être comparée aux différentes descriptions des entités retrouvées dans les documents. Cela permet d’éviter un des problèmes évoqués plus haut, qui est celui de se concentrer uniquement sur les noms d’entités. Par conséquent, les trois entités associées aux trois descriptions les plus proches sont ajoutées à notre ensemble d’entités découlant de la requête.
Chaque entité – extraite directement de la requête ou indirectement par sa description – a été retrouvée plusieurs fois au cours de la phase d’indexation et représente donc plusieurs nœuds dans les graphes locaux. Or qui dit plusieurs nœuds, dit plusieurs descriptions de l’entité, plusieurs relations associées, plusieurs communautés affiliées et plusieurs chunks. Pour une entité, on ajoute donc en contexte l’ensemble de ces informations.
Pour l’instant, aucune règle de ranking de ces informations n’a été mise en place et la seule mesure prise pour éviter la surcharge de la fenêtre de contexte est d’ajouter les informations dans l’ordre des entités trouvées et de s’arrêter lorsque la limite approche.
La Global Search Meritis
Voilà ce qu’il en est pour l’instant de la Local Search, mais souvenez-vous : normalement, il y a deux types de requêtes, alors qu’en est-il de la Global Search Meritis ? Et bien pour l’instant, cette Global Search est encore un problème.
Deux versions sont en cours d’étude. La première, très orientée Microsoft, utilise un LLM pour filtrer les communautés intéressantes des communautés inutiles, ce qui induit donc des temps d’inférences très long. La seconde, une méthode orientée Naive avec une comparaison entre la requête et les descriptions des communautés pour des résultats moins précis mais avec une inférence quasi-inexistante.
Intéressé par la data science ?
👉 Découvrez notre cas client concernant le développement d’algorithmes pour une brosse connectée.

Quels résultats pour notre Multi-GraphRAG ?
Des premiers tests ont été réalisés entre la version Naive du RAG, le GraphRAG de Microsoft, la V1 et la V2 d’INnov. La méthode de test a été réadaptée pour obtenir des résultats plus quantitatifs. Il y a donc désormais un corpus de texte identique avec quinze pages sur les jeux de Paris, trente nouvelles questions et une métrique de note donnée par un LLM juge – ici gemma2:9b pour pouvoir faire tourner l’évaluation en local – qui permet de classer les réponses entre elles.
Le LLM juge reçoit trois éléments :
- La question posée ;
- La réponse attendue ;
- Et la réponse donnée par un des RAG.
Il attribue alors une note sur 10 et la moyenne sur les trente questions fait office de note pour comparer les différents RAG entre eux. Cette approche permet deux points :
- Le premier est de pouvoir classer les RAG entre eux ;
- Et le deuxième de pouvoir estimer si les différents RAG sont plutôt bons ou mauvais sur ce data set.
En effet, un RAG meilleur que tous les autres mais avec une moyenne de 2/10 n’est pas véritablement un bon RAG, c’est un RAG moins pire. A contrario, si un RAG finit dernier avec une moyenne de 9,5/10, ce n’est pas un mauvais RAG : c’est que les questions / le corpus de texte ne permet pas d’évaluer avec précision le véritable niveau des RAG.
Comprendre la matrice des résultats
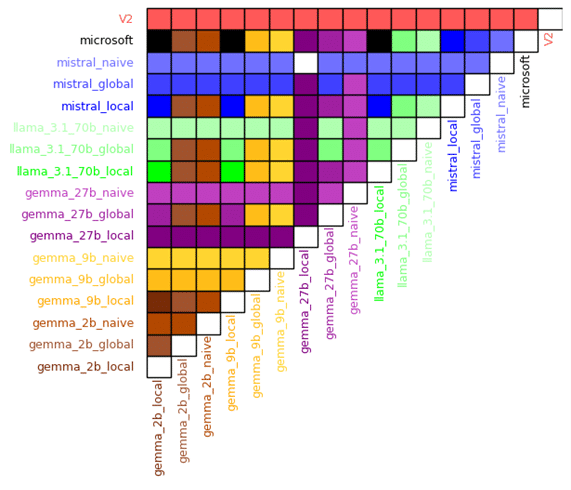
Une fois les moyennes obtenues sur chaque RAG, on peut alors les classer et regarder quel RAG donne des réponses plus pertinentes comparées à un autre RAG. C’est ce que représente la matrice ci-dessous.
L’intersection d’une ligne et d’une colonne forme une case colorée qui est, soit blanche si les deux agents RAG ont obtenu la même note, soit de la même couleur que le nom de l’agent vainqueur. Par exemple, l’intersection entre « Microsoft » et « gemma_27b_local » est une case mauve, ce qui indique que la recherche locale du GraphRAG utilisée avec gemma2:27b a obtenu une meilleure note moyenne que la méthode de recherche du GraphRAG de Microsoft – ici utilisée avec le modèle GPT-4 Turbo.
Comment interpréter les résultats ?
Plusieurs points sont à noter lorsqu’on interprète ces résultats. Tout d’abord, il est intéressant de noter que pour la plupart des modèles, le RAG Naive semble être meilleur que les recherches locales et globales du GraphRAG.
Cependant, il faut éviter cet écueil en se rappelant que normalement, ces deux méthodes de recherche ne sont que deux faces d’une même pièce. En effet, il faut théoriquement choisir l’une ou l’autre selon le type de requête reçu. Or, le principe de « function calling » n’étant pas encore implémenté, on ne peut pour l’instant que regarder les résultats séparément.
Une deuxième remarque qui saute aux yeux, c’est la performance plutôt médiocre du GraphRAG Microsoft pourtant utilisé avec GPT-4o-mini. Encore une fois, attention à ne pas surinterpréter et rappelons par acquis de conscience que le GraphRAG de Microsoft est initialement prévu pour faire de la synthèse de textes et d’idées. Il est donc rassurant que sur un data set avec des questions assez précises et très peu orientées synthétisation de données, cette méthode performe moins.
En revanche, un résultat beaucoup plus encourageant est celui de la version 2 du GraphRAG Meritis – le Multi-GraphRAG – qui emporte haut la main tous ces duels avec une moyenne de 7,8/10 loin devant les deuxièmes ex æquo : Meritis GraphRAG V1 par gemma2 : 27b et RAG Naive par mistral-large, avec une note moyenne de 6/10.
Vous envisagez de développer des solutions de Machine Learning ?
👉 Découvrez notre cas client concernant l’industrialisation d’algorithmes pour une enseigne de grande distribution !

Les RAG, c’est fini ?
Si après avoir lu cet article, vous avez le sentiment d’arriver trop tard et qu’il n’y a plus rien à faire côté RAG, rassurez-vous, ce n’est pas le cas. D’un point de vue interne à Meritis, nos prochaines missions RAG orientées sont les suivantes :
Variabilité des résultats
Les réponses des LLM – incluant une part non-négligeable d’aléatoire et la méthode du Multi-GraphRAG reposant sur des LLM pour l’indexation, la récupération et la génération –, souffrent d’un mal : la variabilité de ces résultats. Il faut donc pouvoir répéter suffisamment de fois des expériences coûteuses en temps pour obtenir des résultats solides.
Comparaison de modèles
Le choix du LLM est crucial car son utilisation est omniprésente dans la méthode. Il faut donc répéter les expériences en utilisant différents modèles pour pouvoir conclure quant à l’efficacité de la méthode selon la taille du modèle.
Mise au point de la Global Search
Aucune Global Search réellement novatrice n’est mise en place dans la méthode Multi-GraphRAG. Une grande partie « recherche et brainstorming » est à entrevoir avant d’obtenir une méthode de recherche globale performante.
Implémentation du function calling
Pour que le Multi-GraphRAG soit considéré comme une approche RAG en tant que telle, l’idéal serait que le choix entre une recherche locale et globale ne soit pas laissé à l’utilisateur mais automatiquement fait selon la nature de la requête. Pour cela, il faut imaginer une méthode permettant de classifier la requête de manière efficace.
Data set académique
Une fois les dernières implémentations faites, la méthode de Multi-GraphRAG devra se confronter à des data sets dits académiques c’est-à-dire habituellement utilisés pour évaluer les RAG, sans quoi, elle ne pourra prouver sa véritable valeur. La mise en place des graphes étant longue, il est naturel et sain de d’abord tester la méthode sur un petit data set fait main. Mais les résultats prennent réellement sens lorsqu’ils sont confrontés aux métriques habituelles des problèmes de même nature.
D’un point de vue plus général, le RAG fait encore beaucoup parler de lui dans les articles récents d’IA générative. Les cas d’usages du RAG étant très étendus, il est probable qu’aucune solution miracle, unifiant toutes les solutions et s’appliquant à n’importe quel type de données, ne soit un jour trouvée. En attendant, des recherches sont menées et de nouvelles solutions voient le jour avec leurs lots d’avantages et d’inconvénients.
Pour continuer vos lectures sur le sujet de l’IA générative : Découvrez notre article mettant en avant certaines limites de ChatGPT
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.




Pas encore de commentaires