
Il y a quelque temps, j’ai découvert Apache NiFi, et en tant qu’ingénieur Big Data, je l’ai immédiatement trouvé très attractif. En effet, cet outil permet de travailler sur la donnée avec une grande facilité.
Présentation de Nifi
Apache NiFi est un projet open source de la fondation Apache, supporté par Hortonworks. Il permet d’injecter automatiquement des flux de données entre différents systèmes sources en direction d’autres systèmes en cible.
Par exemple, NiFi peut être très utile dans un cas d’usage comme l’alimentation d’un DataLake Hadoop à partir de plusieurs sources de données.
Basé sur le paradigme de programmation flow-based programming, NiFi fournit une interface web qui permet de construire un flux de données en Drag et Drog. Ainsi, il est possible de définir, de contrôler en temps réel, et d’une certaine manière, de sécuriser l’acheminement de données.
Apache NiFi assure l’intégralité du flux de données, il est tolérant aux pannes, est scalable et a été conçu pour gérer de gros volumes de données en temps réel.
Apache NiFi est compatible avec Kerberos qui assure l’authentification, avec Apache Ranger qui permet la sécurité des autorisations d’accès et avec Apache Knox qui gère la sécurité au niveau authentification et celle des appels REST and HTTP.
Comment l’utiliser ?
NiFi tourne dans une JVM en mode local sur le système d’exploitation hôte (Windows, Linux ou Mac) mais on peut aussi déployer Apache NiFi en mode cluster, un de ses grands atouts une fois en production.
Il est conseillé d’installer le cluster NiFi sur le FrameWork Hadoop, mais vous pouvez également configurer un cluster NiFi en dehors de Hadoop.
Sachez qu’en mode cluster, vous aurez besoin d’Apache Zookeeper pour la gestion de la configuration afin d’assurer la haute disponibilité des services.
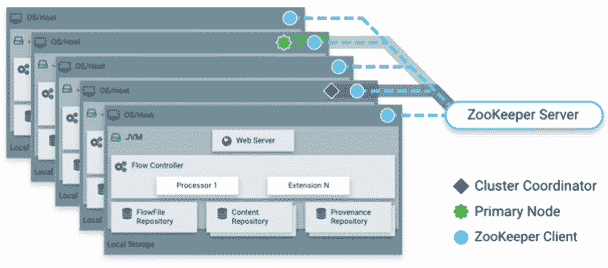 Apache NiFi en mode Cluster
Apache NiFi en mode Cluster
Source : Hortonworks
Apache ZooKeeper élit un nœud unique en tant que coordinateur du cluster.
Tous les nœuds du cluster envoient un signal au coordinateur pour l’informer sur son état.
Le coordinateur de cluster est responsable de la déconnexion et de la connexion des nœuds. En quelque sorte, il joue le rôle du master sans en être réellement un.
En outre, chaque cluster possède un nœud principal, également élu par ZooKeeper.
Pour plus de détails sur le rôle de chaque nœud sur le cluster, je vous invite à lire la documentation NiFi System Administrator’s Guide.
Composants et fonctionnalités
Les composants principaux de NiFi sur la JVM sont les suivants :
- Serveur Web qui héberge l’interface graphique,
- Un flow controler qui orchestre les opérations. Il fournit des tâches à exécuter aux extensions et gère leur ordonnancement,
- FlowFile Repository dans lequel NiFi enregistre l’état d’un FlowFile,
- Content Repository où les données d’un FlowFile sont stockées,
- Répertoire de la provenance où toutes les données d’événement de provenance sont stockées.
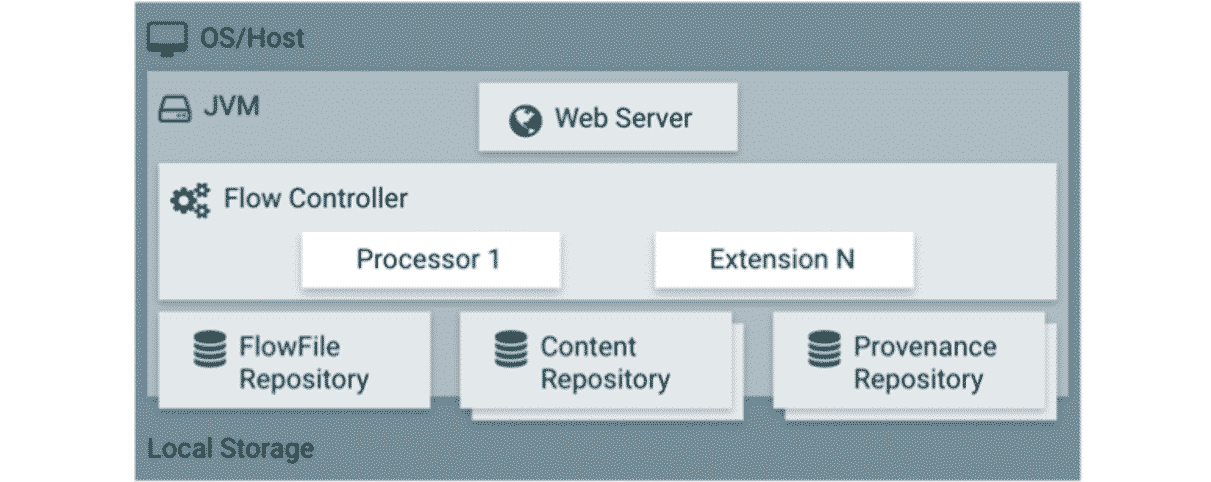 Architecture NiFi
Architecture NiFi
Source : Hortonworks
En outre, NiFi possède plus de 200 connecteurs ou processeurs qui permettent de collecter en temps réel des données issues de plus de 80 sources : bases de données, messages, fichiers, flux Twitter, etc.
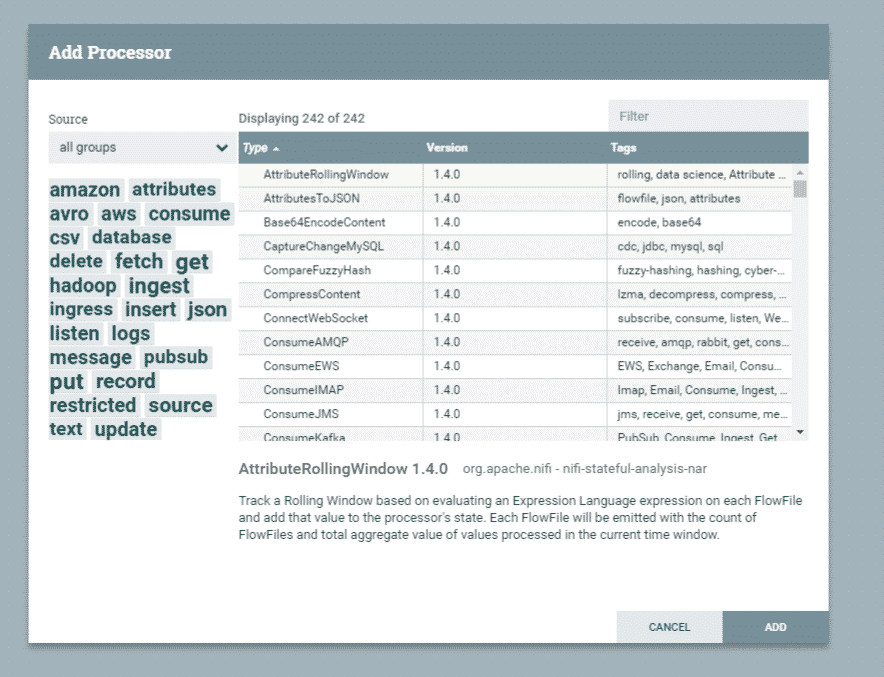 Recherche / Ajout d’un processeur
Recherche / Ajout d’un processeur
Source : Apache NiFi
La richesse de la bibliothèque des processeurs permet de réaliser :
- La data Transformation : compresser ou décompresser des données, convertir un format de données vers un autre (Xml, Json, Txt to Parquet, Avro, etc.) ou bien faire de la crypto et de l’encodage (ConvertCharacterSet, EncryptContent, etc.),
- Les accès aux bases de données : par exemple le processeur Database Access ExecuteSQL ou bien PutHiveQl,
- La Data Ingestion : des processeurs permettent de récupérer des données issues de différentes sources (GetTwitter, GetMongo, GetFile, GetHttp, etc.),
- La Data Egress/Sending Data : des processeurs pour envoyer des données vers des systèmes cible (PutSQL, PutKafka, PutMongo, etc.).
Vous l’aviez deviné, avec Apache NiFi, il est possible de construire un pipeline d’ingestion de données riche et complète.
Apache NiFi s’intègre avec différents outils de streaming et sa combinaison avec Apache Kafka est très robuste.
NiFi peut jouer le rôle du producteur pour Kafka.
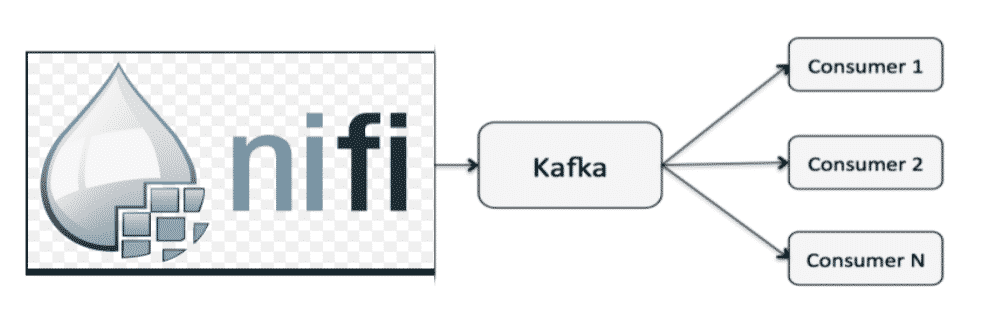 Apache NiFi en producteur de données pour Kafka
Apache NiFi en producteur de données pour Kafka
Source : bryanbende.com
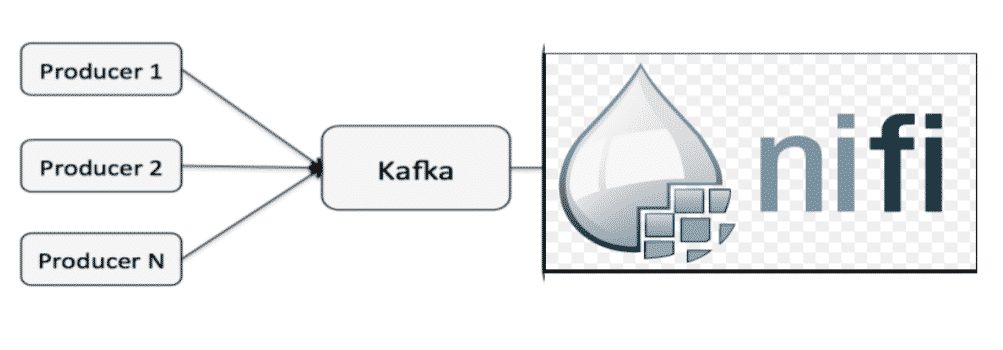 Apache NiFi en consommateur de données
Apache NiFi en consommateur de données
Source : bryanbende.com
De nombreux cas d’usage sont réalisables avec ces deux superbes outils, comme construire un CDC (Change Data Capture), faire du streaming avec Kafka ou encore récupérer des logs de serveurs webs, etc.
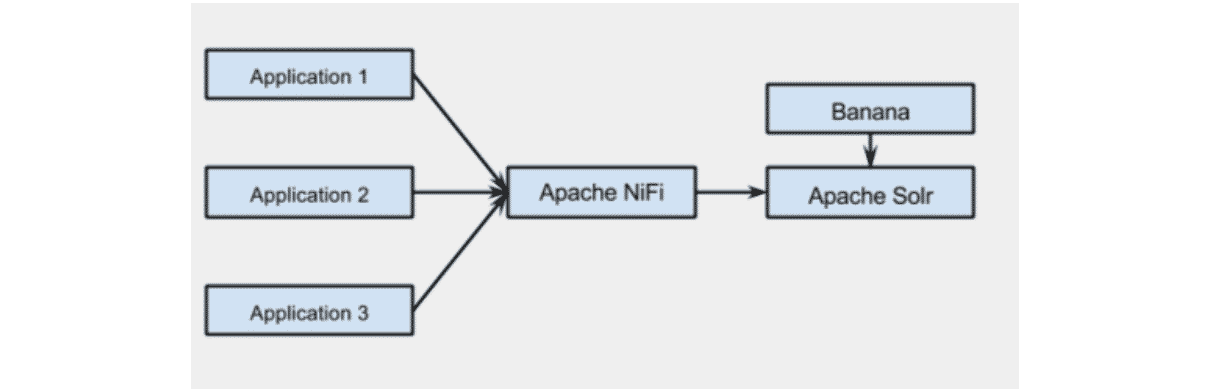 Préparer les données pour les indexer dans Apache Solr
Préparer les données pour les indexer dans Apache Solr
Source : bryanbende.com
On peut également stocker les données sortantes d’Apache Nifi sur le Cloud, notamment sur le cloud d’Amazon (S3 ou Readshift).
Je ne vais pas détailler plus les processeurs fournis par Apache NiFi, vous les trouverez à cette adresse. Sachez qu’Apache NiFi vous permet de vous connecter à beaucoup d’outils producteurs de données, d’effectuer des transformations sur les données récoltées et de les stocker et de les envoyer vers différents outils de stockage ou analytiques.
Exemple d’utilisation
Installation
Pour pouvoir utiliser et tester Apache NiFi, il suffit de télécharger le fichier source ou binaire sur le site Apache ou hortonworks (https://nifi.apache.org/download.html).
Lancez ensuite le fichier run-nifi.bat qui se trouve dans le répertoire nifi-1.4.0-binnifi-1.4.0bin si vous êtes sur Windows, ou bien binnifi.sh run pour les utilisateurs linux/mac.
Cette fenêtre s’affiche :
 Démarrage de Apache NiFi
Démarrage de Apache NiFi
Source : CMD Windows
Puis, sur un votre navigateur Web, saisissez l’adresse : localhost:8080.
Vous obtenez alors cette fenêtre :
 Fenêtre principale de Apache NiFi
Fenêtre principale de Apache NiFi
Source : Apache NiFi
Apache NiFi est désormais installé et lancé sur votre poste de travail.
Pour vous permettre de prendre la main avec NiFi, je vais prendre l’exemple d’un data flow qui récupère des logs générés par un serveur web HTTP.
Nous allons utiliser le processeur GetHTTP et nous allons le brancher sur l’API REST du serveur Apache NiFi.
Mise en place
On ajoute le processeur GetHTTP, pour récupérer des données générées par un serveur HTTP et les écrire dans un FlowFile.
On configure le processeur avec les paramètres qui nous intéressent, en l‘occurrence l’adresse http.
Pour rajouter un processeur, cliquez sur le bouton “Processor”.
 Ajout d’un processeur
Ajout d’un processeur
Source : Apache NiFi
Puis, sélectionnez le processeur qui vous intéresse. Dans notre exemple, on rajoute le processeur GetHTTP.
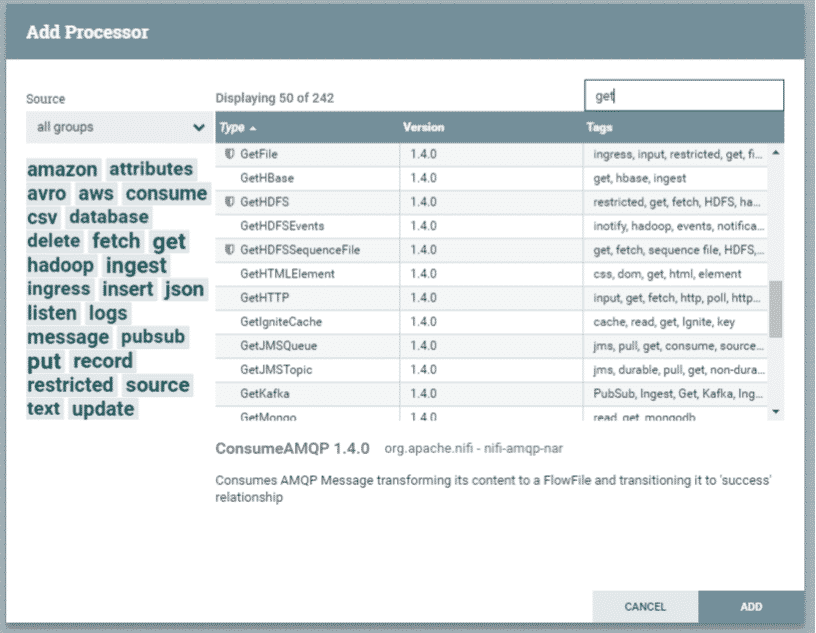 Fenêtre de recherche des processeurs
Fenêtre de recherche des processeurs
Source : Apache NiFi
Processeur log attribute
Le 2e processeur est LogAttribute qui affiche les logs générés par le serveur HTTP.
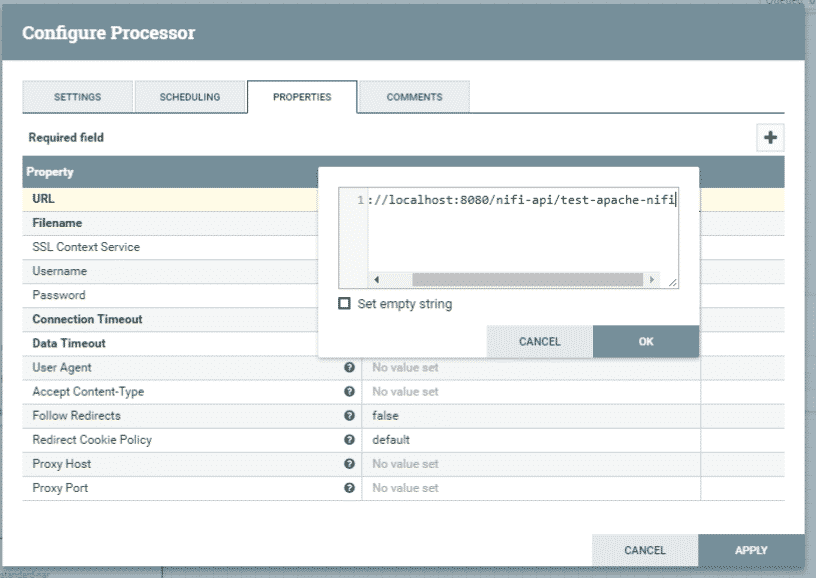 Configuration du processeur 1
Configuration du processeur 1
Source : Apache NiFi
Il faut cocher la case “Success”. Le paramètre “Penality Duration” sert à contrôler le temps accordé à ce processeur quand il pénalise le flux. S’il dépasse 30 secondes, relancez-le. “Yield Duration” permet pour sa part de programmer à nouveau le traitement après la durée mentionnée.
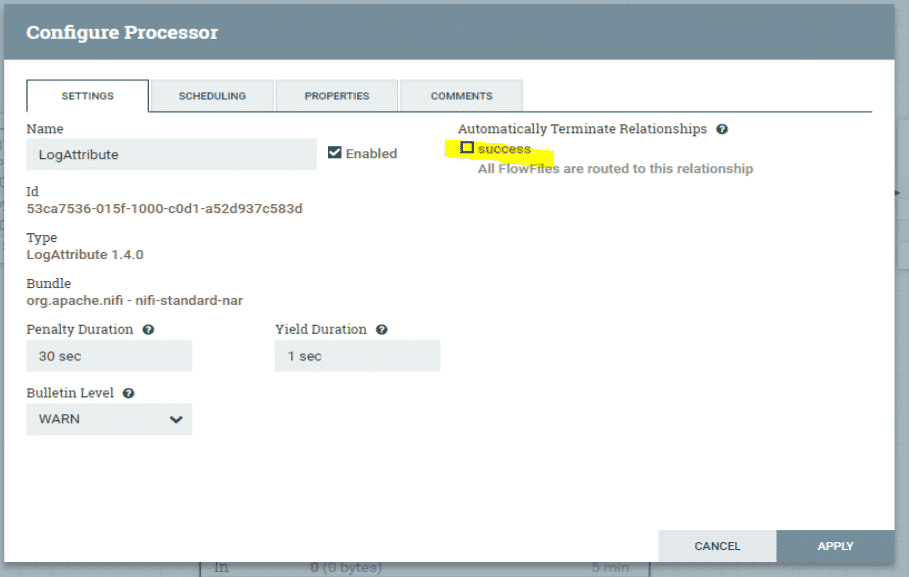 Configuration du processeur 2
Configuration du processeur 2
Source : Apache NiFi
Voici ce à quoi ressemble alors le flux de données, assez simple :
 Un flux de données sur Apache NiFi
Un flux de données sur Apache NiFi
Source : Apache NiFi
Exécution
Lancez alors le flux pour voir le résultat en effectuant un clic droit sur un processeur. Choisissez View data provenance ou View state pour obtenir les informations sur l’état du processeur.
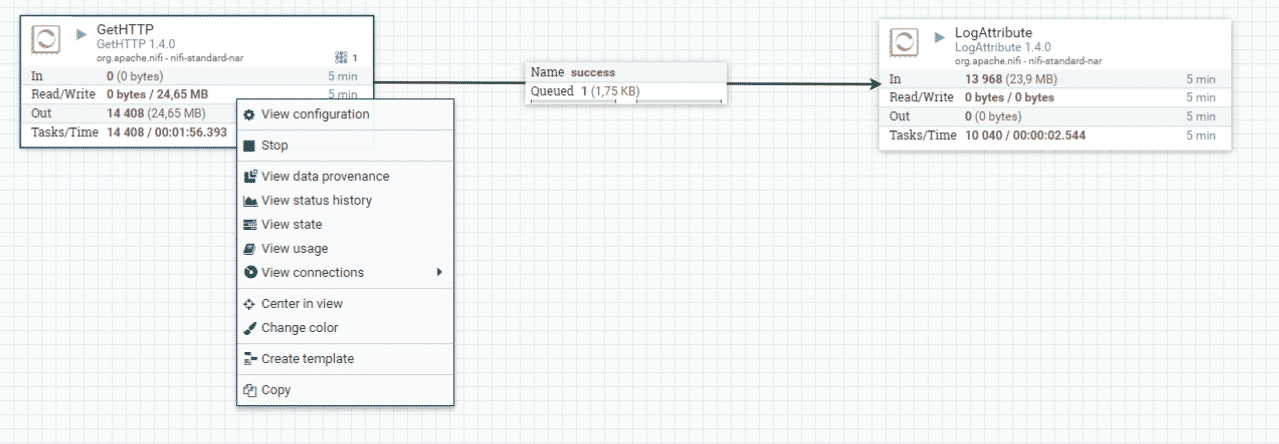
Détails du flux traité par le processeur
Source : Apache NiFi
Une autre fenêtre affiche alors les statistiques du flux de données.
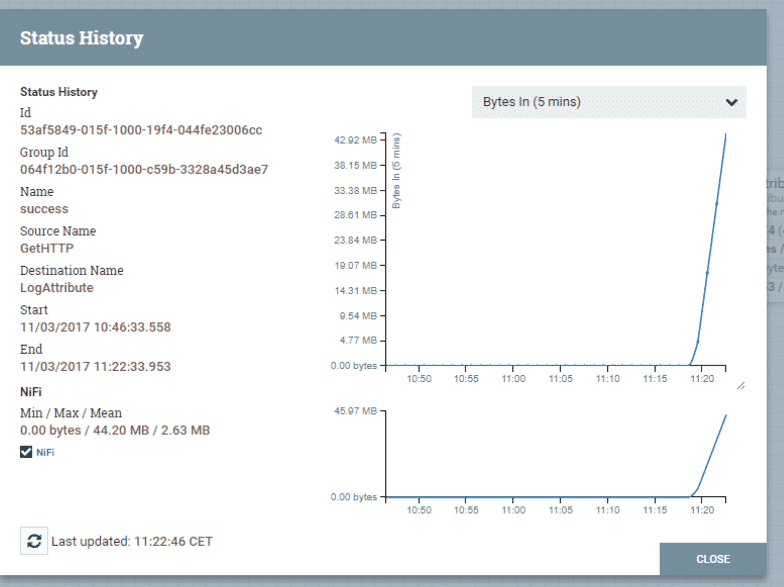
Détails du statut du processeur
Source : Apache NiFi
Vous obtenez les données récupérées du serveur Web afin d’effectuer une analyse.
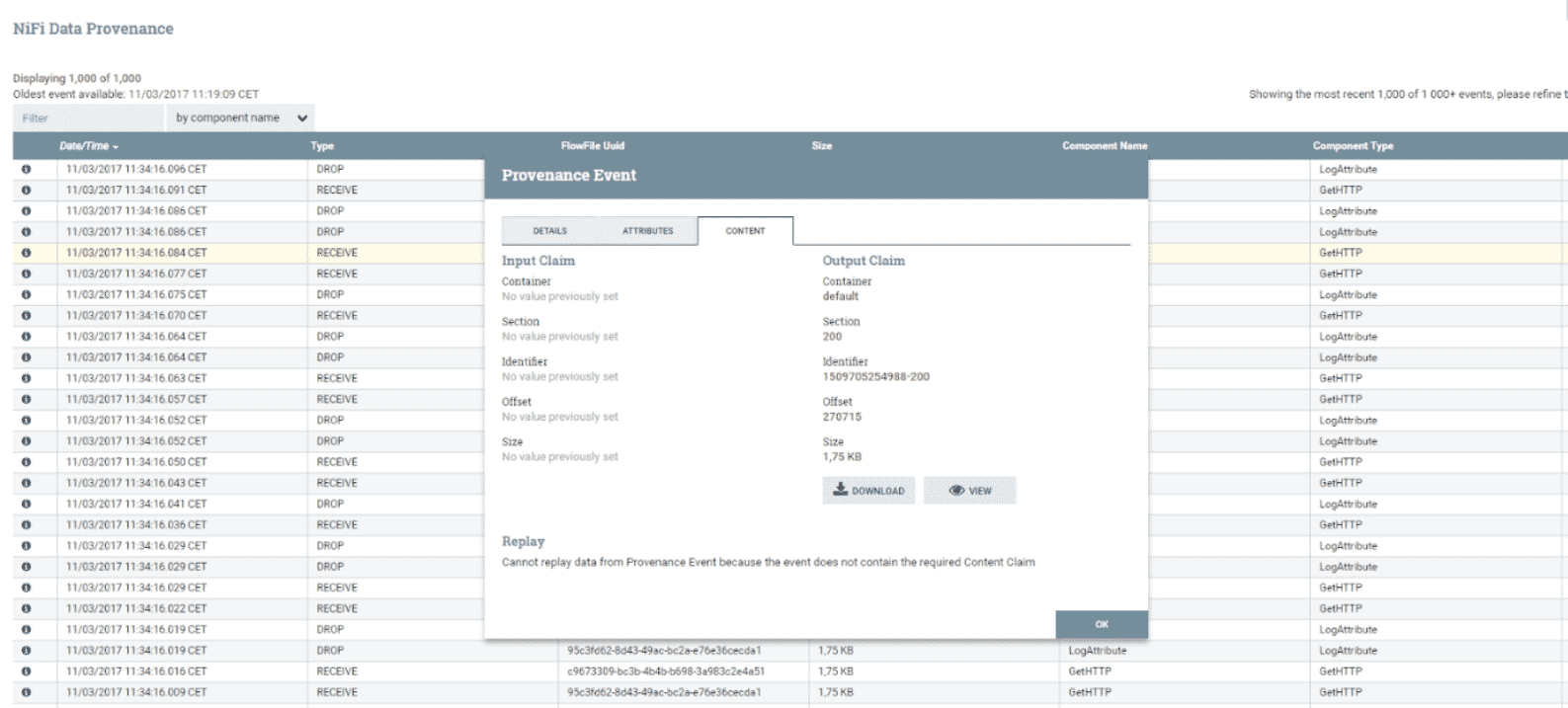
Information sur un flux récupéré par Apache NiFi
Source : Apache NiFi
Une autre fenêtre s’ouvre et détaille les informations récupérées depuis le serveur web.
 Un Json récupéré depuis le serveur Web par Apache NiFi
Un Json récupéré depuis le serveur Web par Apache NiFi
Source : Apache NiFi
Ma conclusion sur Apache NiFi
On peut facilement imaginer l’utilité d’un Data flow qui récupère des logs d’un serveur (Web, BDD ou autres) afin d’analyser le comportement ou de surveiller l’état des machines.
Pour construire un Data flow plus complexe, il sera intéressant d’utiliser le processeur InvokeHttp qui peut être configuré dynamiquement.
Apache NiFi facilite la construction d’un pipeline de données. Avec les différents processeurs de sa bibliothèque, on peut facilement récupérer les données d’un broker Kafka, de serveurs Web, de Twitter, etc., puis les injecter dans différents systèmes en sortie comme par exemple Elastic, S3 ou HDFS.
De plus, l’interface graphique interactive de NiFi permet de créer rapidement des flux de données.
Cet outil relativement peu connu dans le monde du Big data présente selon moi une très grande efficacité et facilite certaines tâches dans la construction d’un pipeline de données complexes.

Vos commentaires
Excellente presentation de NiFi..
Excellent article, bravo ! je sais enfin c’est quoi NIFI.
Un très bon article pour comprendre l’intérêt de Apache NiFi bravo
So apache nifi makes it easy to build a data pipeline . With the various processors in its library, you can easily retrieve data from a Kafka broker, Web servers, Twitter, etc., and then inject them into different output systems such as Elastic, S3 or HDFS.
Super Article . Merci beaucoup. Je comprends enfin ce qu’est NIFI
Bonjour,
Je souhaiterai former une personne à cette technologie. Pouvez-vous me dire quels sont les organismes de formation qui donnent cette formation.
Je vous remercie d’avance pour votre retour.
Bien cordialement
Madame Elisabeth DESCHAMP
quels sont les limites d’apache Nifi ??
Belle présentation sur Nifi. Merci.
Merci pour votre article : synthétique et clair ! En quelques minutes de lecture on comprend le but et le fonctionnement de APACHE NIFI. Bravo !
Bonjour
Merci pour cette synthèse très claire et efficace.
Avez vous d’autres sujets sur le big data et l’infrastructure hadoop?
Cdt
bonjour..
merci beaucoup pour cette magnifique explication
mais est ce que tu peut m’expliquer l’utilisation de NIFI pour la reconfiguration du Gateway.
Cdt