
Le Big Data est un domaine riche en outils divers et variés. Splunk ne fait pas partie des nouveaux arrivants sur ce marché mais savez-vous ce que c’est exactement ? Yacine nous propose de partager son expérience à ce sujet afin que nous en sachions plus.
Introduction à Splunk
En 2007, les cofondateurs de Splunk, Michael Baum, Rob Das et Erik Swan, ont levé 40 millions de dollars. Depuis, l’entreprise est devenue rentable en 2009, rentrée en bourse en 2012 et a intégré le NASDAQ sous le symbole SPLK10. En 2013, elle acquiert Bugsense, entreprise spécialisée dans l’analyse de données mobiles, pour proposer une plateforme d’analyse de supports mobiles utilisée par les développeurs afin d’améliorer les performances et la qualité de leurs applications.
Deux ans plus tard, elle rachète la startup de sécurité informatique Caspida pour 190 millions de dollars, puis noue une alliance avec le prestataire de services de sécurité informatique pour le gouvernement américain, Booz Allen Hamilton Inc.
En avril 2017, Splunk devient la quatrième entreprise qui paye le mieux ses employés aux États-Unis.
Enfin, l’année 2018 a été marquée par l’impact de l’IoT sur le secteur des transports et la ville en général. En ce sens, les nouvelles techniques d’analyse prédictive favorisées par le Machine Learning (ML) vont se généraliser dans l’entreprise, transformant le commerce avec des expériences ML intuitives et prêtes à l’emploi. La technologie de sécurité deviendra alors un catalyseur, permettant de relever le défi d’attaques de plus en plus sophistiquées pour assurer la sécurité des données.
Dans le contexte de transformation actuel, deux questions émergent :
- Pourquoi avons-nous besoin d’utiliser Splunk ?
- Comment résoudre les problèmes auxquels je fais face ?
Pourquoi avons-nous besoin de Splunk ?
Au vu de l’image ci-dessous, il s’avère difficile pour un administrateur Système de comprendre ce qui ne fonctionne pas, de localiser à quelle étape le problème s’est produit et de savoir quelles actions il peut éventuellement mettre en place pour y remédier.
L’analyse de ces données peut en effet prendre plusieurs heures afin de pouvoir comprendre l’incident et trouver la solution adéquate.
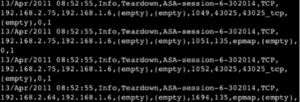
Les principaux éléments de complexité peuvent alors se résumer en trois points :
- La compréhension des données de machine est une action très complexe
- Les données machine ne sont pas structurées
- Les données brutes ne conviennent pas pour l’analyse et la visualisation
C’est là qu’un outil comme Splunk est très utile : il extrait les données machine, puis les traite de façon pertinente. Résultat, l’administrateur peut ainsi identifier et localiser plus facilement les problèmes.
Splunk et Big Data
L’utilité de Splunk a pris une ampleur beaucoup plus importante avec les big data.
Capable de stocker et de traiter de grandes volumétries de données, les analystes ont commencé à intégrer des big data à Splunk. Les tableaux de bord (dashboards) destinés à la visualisation se sont révélés très pertinentes. En conséquence, très rapidement, Splunk a été largement utilisé dans le domaine du big data pour l’analyse.
Définition de Splunk :
La plateforme logicielle Splunk permet de rechercher, d’analyser et de visualiser les données générées par des machines, et collectées à partir des sites web, des applications, des capteurs, des appareils, etc., qui constituent l’infrastructure informatique de l’entreprise.
Sa caractéristique essentielle repose sur le fait que la plateforme ne nécessite pas de base de données car elle utilise largement ses index pour stocker les données.
Collecte et traitement de données via Splunk :
De nombreuses applications et extensions ont été développées par Splunk et par sa communauté de développeurs pour simplifier la connexion et la collecte de données issues de systèmes industriels et des objets connectés.
Les données générées en continu par une machine peuvent être analysées par Splunk en temps réel pour comprendre l’état de cette dernière.
Voici comment Splunk collecte les données :
Extraction des données de plusieurs systèmes en temps réel
Le traitement en temps réel reste le principal point fort de de Splunk car, au fil des années, les périphériques de stockage se sont améliorés et les processeurs sont devenus plus efficaces… mais pas le mouvement de données. Cette technique ne s’est pas améliorée et constitue le goulot d’étranglement dans la plupart des processus.
Parmi les autres avantages de la mise en œuvre de Splunk :
- Les données d’entrée peuvent être dans n’importe quel format, par exemple. .csv, json ou autres.
- La possibilité de configuration de Splunk pour lancer une notification d’alertes / d’événements au début d’un état de la machine.
- La capacité de prédiction précise des ressources nécessaires pour la mise à l’échelle de l’infrastructure.
- La possibilité de créer des objets de connaissance dédiés à l’intelligence opérationnelle.
Qu’est-ce qu’un objet de connaissance ? Il s’agit d’une entité définie par l’utilisateur à l’aide de laquelle vous pouvez enrichir vos données existantes en extrayant des informations précieuses. Il peut s’agir de recherches enregistrées, de types d’événements, de recherches, de rapports, d’alertes ou bien d’autres encore, ce qui facilite la configuration des informations sur vos systèmes.
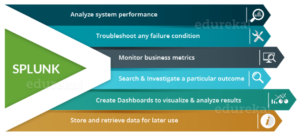
Certaines fonctionnalités de Splunk peuvent être mentionnées dans la figure suivante :
Cas d’usage : l’utilisation de Splunk pour l’analyse des données médicales
Les données médicales des patients localisés à distance à l’aide d’appareils IoT (capteurs) sont collectées et transmises à Splunk. Le logiciel les traite et toute activité anormale peut ainsi être signalée au médecin et au patient via l’interface patient. Ici, Splunk intervient pour :
- Signaler des problèmes de santé en temps réel
- Approfondir le dossier médical et analyser les tendances
- Alarmer / alerter à la fois le médecin et le patient lorsque son état de santé se dégrade
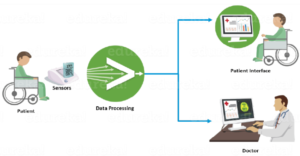
Exemple de traitement de données médicales par Splunk
Les caractéristiques de Splunk
Parmi les principales fonctionnalités de Splunk, on peut noter :
- Le traitement de données en temps réel.
- Les données d’entrée pour Splunk peuvent être dans n’importe quel format comme CSV, JSON et autres.
- Vous pouvez facilement rechercher et étudier un résultat particulier avec Splunk
- Le logiciel vous permet de dépanner n’importe quelle condition d’échec pour améliorer les performances.
- Vous pouvez surveiller n’importe quelle métrique d’entreprise et prendre une décision éclairée.
- Il est possible de visualiser et d’analyser les résultats au moyen de puissants tableaux de bord.
- Vous pouvez analyser les performances de tout système informatique avec l’outil Splunk.
- Splunk vous permet même d’intégrer une intelligence artificielle dans votre stratégie de données.
Autres applications de Splunk
Toutefois, la liste des applications de Splunk ne s’arrête pas là tant ses possibilités sont vastes :
- Vous pouvez déployer Splunk en analyse web pour comprendre les indicateurs de performance clés et améliorer vos performances.
- L’utilisation dans les opérations informatiques permet de détecter les intrusions, les violations et les abus de réseau.
- Capacité à suivre, analyser et affiner les initiatives de marketing numérique avec Splunk.
- À l’avenir, Splunk facilitera le travail sur l’Internet des objets.
- Son application dans les systèmes d’automatisation industrielle permet de vérifier que tout fonctionne comme prévu.
- Splunk aide le responsable en cybersécurité à choisir la meilleure solution pour sécuriser les systèmes informatiques.
Comparaison de Splunk avec ELK (Elastic, Logstash, Kibana)
Nous pouvons comparer Splunk et ELK en prenant en compte les critères suivants :

Splunk est un système d’analyse de donnée très alléchant sur le papier en provenance d’une société parfaitement rodée dans ce domaine. Dans un prochain article, nous parlerons plus en détail de son fonctionnement. J’espère que cette première partie vous aura donné envie d’en apprendre plus sur Splunk.
Source des visuels : Edureka

Pas encore de commentaires