
Dans cette suite d’article, nous allons voir ensemble l’architecture détaillée du Framework Apache Spark, comprendre les différentes briques qui forment le Framework et voir comment on peut déployer et exécuter des traitements Spark avec les différents clusters manager.
Nous allons commencer dans cet article par l’architecture du Framework et comprendre comment fonctionne les traitements sur ce Framework.
Présentation générale
Apache Spark est un framework de calcul distribué in-memory principalement (mais pas que) qui permet de faire de l’ETL (Extract Transform and Load), de l’ELT (Extract Load and Transform), de l’analytique avec une librairie riche et complète, du Machine Learning et aussi du traitement de graphes sur des gros volumes de données, avec différents formats en batch ou en pseudo-temps réel.
On peut développer des traitements Spark avec plusieurs langages différents, le plus utilisé est bien sur Scala (le framework lui-même étant développé en Scala), le Python, le Java, le SQL et le langage R.
Il faut bien comprendre que Spark n’est pas une base de données et ne stocke rien, il se base sur des systèmes de stockage comme Hadoop, AWS S3, Cassandra, MongoDB, etc.
Les briques qui composent Apache Spark sont les suivantes :
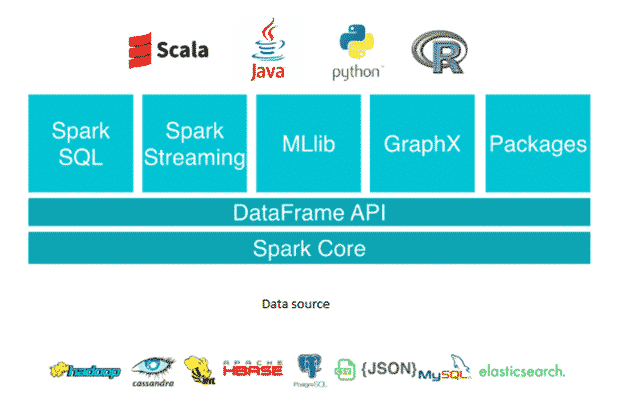
Apache Spark Core
Spark Core, comme son nom l’indique, est le moteur d’exécution du framework, la base du framework. Il fournit la répartition des tâches distribuées, le scheduling et des fonctionnalités lectures/écritures de base. L’API RDD est implémentée (Resilient Distributed Datasets) sur Spark Core, qui est une collection logique de données partitionnées sur le cluster.
Les RDD peuvent être créés de deux façons : l’une est en référençant des jeux de données dans des systèmes de stockage externes (ou bien en le créant via le SparkContext) et la seconde consiste à appliquer des transformations (Map, filtre, Reduce, jointure) sur des RDD existants.
Spark SQL
Spark SQL est le composant qui vient au dessus de la couche Core et qui introduit une nouvelle abstraction de données SchemaRDD, des données structurées et semi-structurées.
Spark SQL fournit des fonctions qui se basent sur Spark Core et ses APIs Scala, Java, Python, SQL et R.
Spark SQL apporte une vision semi-structurée, les DataFrames, et à partir de la version 2 les Datasets, ce qui permet d’extraire, transformer et de charger des données sous différents formats (csv, Json, Parquet, base de données).
La brique Spark SQL s’intègre très bien avec Apache Hive (en utilisant le langage HQL) et aussi avec des connexions JDBC pour se connecter à des serveurs de BI.
Spark Streaming
Spark Streaming est la partie traitement en pseudo temps réel d’Apache Spark. La brique Streaming est basée sur Spark Core et traite la donnée sous forme de mini-batchs espacés par un instant T. L’API de Spark Streaming construit des RDD de type spécifique (des Dstreams) mais les traitements qui seront faits sur les Dstreams sont identiques à ceux de Spark Core classique.
Spark Streaming supporte plusieurs sources de données, tel qu’Apache Kafka, Flume, Kinesis…
MLlib (librairie Machine Learning)
MLlib est une librairie de Machine Learning distribuée et ses algorithmes sont conçus pour être exécutés sur un cluster de machines d’une manière distribuée.
MLlib utilise des RDD aux types spécifiques. Les inputs des algorithmes doivent être des RDD[Vector] (pour des données n’ayant pas de label), des RDD[LabeledPoint] (spécifique à l’apprentissage supervisé) ou bien des RDD[Rating] (pour les systèmes de recommandation). Il faut savoir qu’il existe aussi une autre librairie de Machine Learning sous Spark, Spark ML, qui elle est basée sur l’API Dataframe.
GraphX
GraphX est un framework de traitement de graphe distribué sur Spark. Il fournit une API pour faire du calcul graphe qui peut modéliser les graphes définis par l’utilisateur en utilisant l’API d’abstraction Pregel. Il fournit également une durée d’exécution optimisée pour cette abstraction.
Fonctionnement
Le succès du framework Spark face à l’implémentation de MapReduce sur Hadoop est dû principalement à des étapes de Shuffle moins coûteuses (MapReduce fait plusieurs lectures/écritures disque alors que Spark en limite beaucoup et stocke les données des étapes intermédiaires en mémoire).
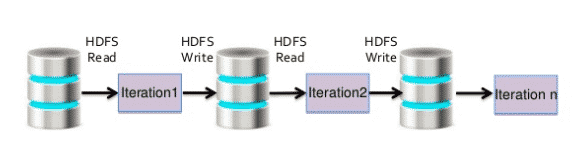

Un autre point qui donne à Spark des performances supérieures à celle de MapReduce : les évaluations paresseuses (« lazy evaluation ») des requêtes.
La lazy evaluation
Qu’est-ce qu’une lazy evaluation (en français évaluation paresseuse) et pourquoi Apache spark est basé sur la lazy evaluation ?
Tout d’abord, il faut savoir qu’en Spark, vous avez deux types d’opérations, les transformations et les actions (nous parlerons en détails des deux opérations dans un autre article consacré aux shuffles).
Les transformations en Spark sont ce qu’on appelle lazy, cela veut dire que, quand vous exécutez des fonctions de transformation en Spark, le framework ne va pas les exécuter de suite mais garde un enregistrement de la fonction appelée. L’ensemble de ces opérations vont construire un graphe DAG (Directed Acyclic Graph : nous parlerons en détails du graphe dans un prochain article consacré à l’anatomie d’un job spark), l’ensemble des opérations d’un traitement Spark est exécuté lorsqu’une fonction de type action est invoquée dans le programme (exemple : un count, un reduce, un write …).
Vous l’aviez peut-être deviné, dans l’évaluation paresseuse, les données ne sont pas chargées depuis la source tant que cela n’est pas nécessaire. Ainsi, on évite les exécutions de code coûteuses et inutiles et on gagne en performance lors de l’exécution, c’est ce qui fait, en autre, l’avantage d’Apache Spark vs MapReduce de Hadoop.
Architecture globale de Spark
Nous allons voir maintenant en détail l’architecture du framework Spark.
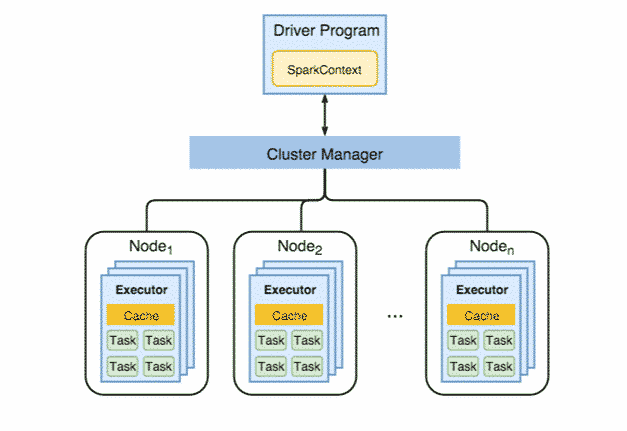
Spark s’exécute en mode maître esclave, c’est-à-dire un master et un ou plusieurs workers.
On peut exécuter des programmes en mode standalone scheduler (le mode natif qui gère un cluster Spark) ou bien en se basant sur un cluster manager qui gère les ressources du cluster (Yarn, Mesos ou Kubernetes).
Il faut faire la différence entre lancer un traitement Spark en mode standalone et en mode local. Dans ce dernier mode, Spark lance toutes les tâches sur une seule JVM et le parallélisme se fera en fonction des nombres de threads (pour voir si vous êtes en mode local, lancer cette commande sc.isLocal et pour définir le nombre de threads pour la session Spark, il faut le définir via le master -- local[n]).
Lorsque vous lancez un traitement sur le framework Spark, vous passez par le Driver qui est en quelque sorte le master, lui-même communique avec le cluster manager, ce dernier gère les ressources des workers (les workers exécutent le traitement à proprement parler).
Le Driver s’exécute dans une JVM qui héberge notamment le SparkContext et pilote la construction de graphe DAG (à travers le DAGScheduler et Task Scheduler).
Le Driver héberge aussi le Spark Web UI, une interface web pour monitorer les traitements Spark ( http://[MasterHostname]:4040 par défaut à cette adresse).
On peut lancer un traitement Spark sous deux modes d’exécution :
- Mode client : le driver est créé dans la machine qui soumet l’application (machine locale ou machine qui héberge le master)
- Mode cluster : le driver est créé à l’intérieur du cluster (dans une machine worker).
La mémoire et le nombre de cœurs CPU alloués au Driver peuvent être définis lors de l’exécution du traitement Spark avec les deux paramètres suivants : --driver-memory (par défaut 1g) et –driver-cores (par défaut 1 core)
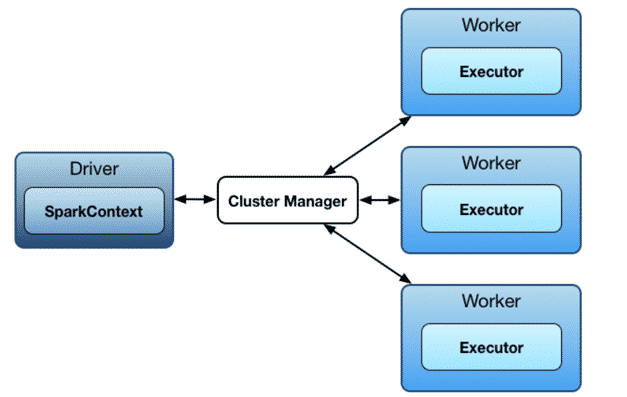
SparkContext est le point d’accès à toutes les fonctionnalités de Spark. Il faut savoir qu’un seul SparkContext existe par JVM (on peut modifier le paramètre via spark.driver.allowMultipleContexts mais il est recommandé d’avoir un seul SparkContext par JVM) et le Driver l’utilise pour se connecter au gestionnaire du cluster afin de communiquer et de soumettre des jobs Spark.
Grâce à SparkContext, le driver peut instancier d’autres contextes tels que SQLContext, HiveContext et StreamingContext, etc.
Cependant, depuis la version Apache Spark 2.0, SparkSession peut accéder à toutes les fonctionnalités de Spark via un point d’entrée unifié. En plus de faciliter l’accès aux fonctionnalités Spark, il simplifie également les contextes sous-jacents pour manipuler les données.
Pour créer un SparkContext, on doit d’abord créer un SparkConf, ce dernier stocke les paramètres de configuration, le Driver les récupère afin de les passer en paramètres au SparkContext.
Vous l’avez compris, pour pouvoir exécuter des jobs Spark en local ou sur un cluster, vous devrez définir quelques paramètres de configurations.
Avec SparkConf on peut customiser beaucoup de paramètres du cluster et job spark, le parallélisme, les ressources allouées aux jobs, le shuffle, etc.
Maintenant que nous avons vu le rôle du master et quelques configurations importantes, nous allons voir le rôle des slaves (les workers).
Concrètement, un worker va exécuter un traitement Spark. C’est un nœud dans un cluster Spark dans lequel un ou plusieurs exécuteurs vont exécuter les taches.
Quand le SparkContext est instancié, chaque worker (ou plusieurs) lance un exécuteur (ou plusieurs), en fonction des paramètres définis dans le SparkConf. En effet, les exécuteurs sont finalement des JVM séparées qui vont être créées. Une fois créés, les exécuteurs se connecteront à l’instance Driver. Une fois la connexion faite, ce dernier leur envoie les taches à exécuter par exemple : flatMap, map and reduceByKey. Lorsque le Driver se termine, les exécuteurs s’arrêteront aussi.
Vous pouvez définir les paramètres des workers et les exécuteurs soit lors de la création de SparkConf soit lors de l’exécution de votre job Spark par exemple : spark.executor.cores qui définit le nombre de core par exécuteur ou bien spark.executor.memory pour la quantité de RAM allouée.
Pour résumé : dans un cluster vous aurez 1 worker = 1 nœud (physique ou virtuel, on peut avoir plusieurs workers virtuels sur une seule machine physique) et dans chaque worker, vous aurez 1 à n exécuteurs.
Au final, un exécuteur traite une ou plusieurs taches (via la création d’une TaskRunner).
L’exécuteur s’exécute dans un processus java, la mémoire disponible dans ce cas est égale à la taille du heap, cette zone disponible est aussi « splittée » en plusieurs parties avec pour chacune un rôle spécifique.
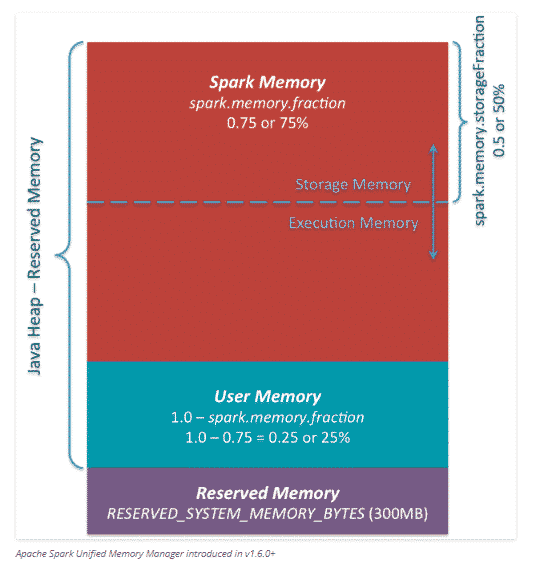
La partie Reserved Memory est réservée au système et ce paramètre est hardcodé, on peut le modifier via spark.testing.reservedMemory mais ce n’est pas recommandé par les créateurs de Spark.
User Memory : c’est le pool mémoire libre à l’utilisateur pour y stocker des données qui vont être utilisées lors de l’exécution du job.
Dans Spark 1.6.0, la taille de ce pool de mémoire peut être calculée comme suit («Java Heap» – «Mémoire réservée») * (1.0 – spark.memory.fraction), qui est par défaut égale à («Java Heap» – 300 Mo) * 0,25.
Par exemple, avec un segment de mémoire de 4 Go, vous disposerez de 949 Mo de mémoire utilisateur.
Spark Memory : cette partie est gérée par Spark.
Sa taille peut être calculée de la manière suivante («Java Heap» – «Mémoire réservée») * spark.memory.fraction : valeurs par défaut de Spark 1.6.0 («Java Heap» – 300 Mo) * 0,75. Par exemple, avec un heap de 4 Go, ce pool aura une taille de 2847 Mo.
Cette partie est divisée en deux, une partie pour le stockage et une pour l’exécution, et la limite entre elles est définie par le paramètre spark.memory.storageFraction.
La partie stockage est utilisée à la fois pour stocker les données en cache et aussi pour des données sérialisées temporairement qui vont être utilisées dans le programme.
Execution Memory : est utilisée pour stocker les objets requis lors de l’exécution des tâches Spark par exemple les shuffles, joins, sorts et les agrégations.
Comprendre ces détails vous aidera à mieux configurer les ressources de vos Workers/ Executeurs / Driver, surtout quand vous allez devoir optimiser votre traitement spark.
Communication au sein du cluster
Les workers sont chargés de communiquer au driver du cluster la disponibilité de leurs ressources.
La communication avec le Driver se fait via une interface RPC (actuellement Akka), sauf si le cluster manager est Mesos alors la communication se fera en mode in fine-grained.
Les nœuds du cluster (master comme workers) exposent par ailleurs une interface Web permettant de surveiller l’état du cluster ainsi que l’avancement des traitements. Chaque nœud ouvre donc deux ports :
- un port pour la communication interne : port 7077 par défaut pour le master, port aléatoire pour les workers
- un port pour l’interface Web : port 8080 par défaut pour le master, port 8081 par défaut pour les workers
Les workers continuent à envoyer des métriques au driver pour les tâches actives à chaque spark.executor.heartbeatInterval (la valeur par défaut est 10s avec un délai initial aléatoire afin que les pulsations des différents exécuteurs ne s’accumulent pas sur le pilote).
A la fin du job spark, le driver libère les ressources allouées aux workers via le cluster manager afin d’exécuter d’éventuels prochains traitements.
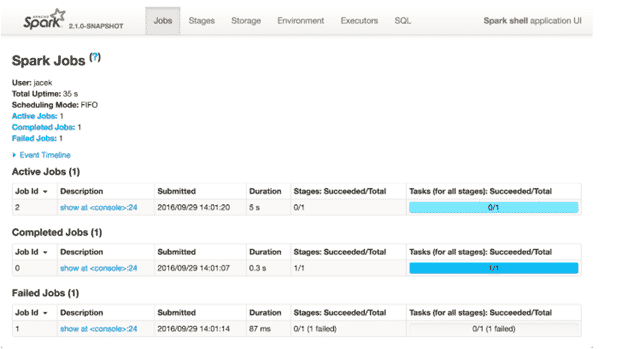
Spark UI
Spark UI est l’interface web des applications Spark, elle permet de surveiller et d’inspecter les exécutions des jobs Spark dans un navigateur web. Elle fournit les informations affichées sur les onglets suivants (qui ne sont peut-être pas tous visibles immédiatement, mais uniquement après l’utilisation des modules respectifs, par exemple les onglets SQL ou Streaming): Stages, Storages, Environnement et Executors.
Cette console est très utile pour voir en détail l’exécution des jobs Spark, comprendre ce qui se passe dans chaque étape de l’exécution ( la durée de chaque stage/étape , le I/O shuffle, les informations sur les exécuteurs, etc.)
Mais pour avoir plus de détails et de log, il est préférable de voir les logs générés grâce à log4j.
Log4j est configurable via conf/log4j.properties (valeurs possible OFF, FATAL, ERROR , WARN, INFO, DEBUG, TRACE ou ALL)
Pyspark
Pour les personnes qui utilisent Spark avec le langage Python, sachez que le Pyspark est construit sur l’API Java de Spark. Les données sont traitées en Python et mises en cache / shufflées dans une JVM.
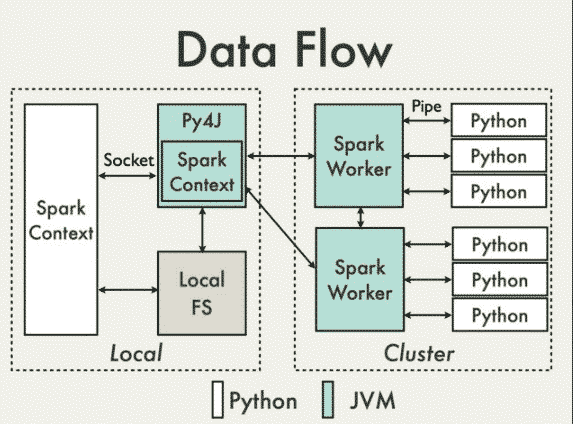
Dans le programme du Driver Python, SparkContext utilise Py4J pour lancer une JVM et créer un JavaSparkContext, le JavaSparkContext communique avec les workers du cluster.
Py4J est uniquement utilisé avec le driver pour la communication locale entre les objets Python et le JavaSparkContext : les grands transferts de données sont effectués via un mécanisme différent.
Les transformations RDD en Python sont mappées en transformations objets PythonRDD en Java. Sur les workers distants, les objets PythonRDD lancent des sous-processus Python et communiquent avec eux à l’aide de canaux, en envoyant le code de l’utilisateur et les données à traiter.
Sachez que les experts du framework incitent les data engineers à privilégier l’utilisation du langage Scala car, à script équivalent entre Python et Scala, le dernier sera plus performant en raison de la communication entre le Python et la JVM.
Conclusion
Nous avons vu l’architecture du framework Spark ainsi que les principaux composants, nous allons voir dans les prochains articles comment lancer un cluster Spark et comment exécuter des jobs avec un ressource manager différent.
Nous allons parler des différentes manières de travailler sur Spark. Spark-shell, qui instancie une application Spark en mode standalone par défaut, Spark-submit et les principaux paramètres et aussi le SparkLauncher qui permet de lancer un job Spark dans un programme informatique.
Pour finir, j’aimerais attirer votre attention sur un autre système open source qui peut jouer le rôle d’un ressource manager pour un cluster Spark, Nomad. Par contre, ce gestionnaire de cluster n’est pas officiellement supporté par le projet Spark, du moins pas pour le moment.

Vos commentaires
Merci pour cet article.
Le texte, les explications avec les illustrations (schémas) sont clairs
Merci beaucoup pour cet article !
Merci pour ce résumé.
Ca récapitule l’essentiel a savoir sur l’architecture distribué de spark.
Merci beaucoup !
Débutant en data engineering, je trouve ces contenus très instructifs, même si certains termes techniques m’obligent encore à creuser pour mieux comprendre — ce qui est très formateur.
Thanks @Abdelwahab Touil