
Dès que l’on parle du langage Java, au-delà des concepts de base tels que l’héritage et le polymorphisme, le concept de Garbage Collector ressort rapidement et inévitablement. Si son rôle est bien connu, difficile de comprendre comment le processus fonctionne véritablement. Cet article a pour objectif de vous donner un aperçu du système de Garbage Collector (GC) en décrivant son mode de fonctionnement et ses différentes possibilités de mise en œuvre.
Le Garbage Collector Java est un processus automatique, en background, qui gère la mémoire de la machine virtuelle Java.
Il traite principalement de l’allocation et de la désallocation de mémoire pour permettre son utilisation dans notre programme. À la clé : la capacité à créer de nouveaux objets sans avoir à vous soucier, comme c’est le cas par exemple dans le langage C++, de devoir gérer manuellement la mémoire qu’ils occupent.
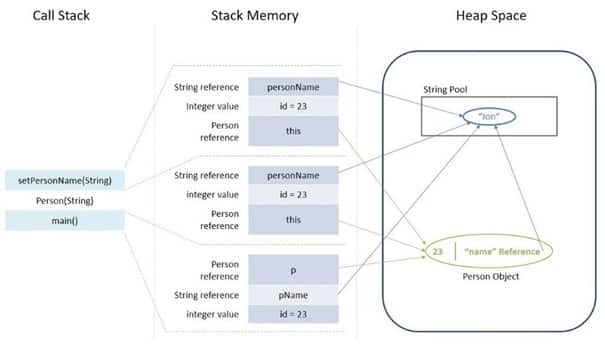
Pour aller plus loin, il est nécessaire d’introduire le concept de Heap (ou tas) et de Stack (ou pile), et la façon dont ils sont gérés par la JVM.
Lors de l’exécution d’un programme ou d’une application, la JVM divise la mémoire en Heap et en Stack. À chaque fois que de nouvelles variables, objets ou méthodes sont déclarées, la JVM alloue de l’espace à ces objets, soit dans Stack, soit dans Heap.
I/ Stack & Garbage Collector
Stack est utilisé pour l’allocation statique et l’exécution des processus. Le mécanisme stocke des valeurs primitives et maintient des références à des objets dans le tas.
Dès qu’une nouvelle méthode est invoquée, un nouveau bloc est créé au sommet de la pile, qui contient des valeurs spécifiques à cette méthode, telles que des variables primitives et des références à des objets dans Heap.
Lorsque la méthode termine l’exécution, le cadre relatif de Stack est vidé, le flux retourne à la méthode appelante et l’espace devient disponible pour la méthode suivante.
II/ Heap & Garbage Collector
Le mécanisme de gestion est utilisé pour l’allocation dynamique de mémoire pour les objets Java et les classes JRE au moment de l’exécution. De nouveaux objets sont toujours créés dans l’espace Heap et les références à ces objets sont stockées dans la mémoire Stack. Ces objets ont un accès global et sont accessibles depuis n’importe quel endroit de l’application.
D’une manière générale, le GC a pour tâche de trouver et d’effacer les objets inutilisés (inaccessibles) de la mémoire mais, en réalité, il garde une trace de chaque objet disponible dans l’espace JVM et supprime ceux qui ne sont pas utilisés. Cette phase est appelée « Stop the World » et peut nécessiter de mettre en pause l’ensemble des threads de l’application (ce qu’on appelle Pause the World).
Pour ce faire, il utilise deux techniques simples appelées Mark et Sweep :
- Mark identifie les objets en mémoire qui sont utilisés et ceux qui ne le sont pas.
- Sweep supprime les objets identifiés lors de la phase précédente.
Au cours de ce processus de nettoyage, tous les threads d’application seront suspendus et aucune transaction ne sera effectuée.
Dans cette phase, tous les cycles du processeur seront utilisés pour nettoyer la mémoire. Une fois terminés, tous les threads seront réaffectés et l’application peut continuer.
Important : il existe également une troisième phase (phase de compactage) réalisée ou non basée sur l’algorithme GC choisi. Cela résout le problème de la mémoire fragmentée. Une fois tous les objets vivants marqués, ils sont déplacés au début de l’espace mémoire, ce qui permet d’éviter d’avoir une mémoire trop fragmentée. Mais le compactage du tas n’est pas gratuit, bien au contraire ! La copie d’objets et la mise à jour de toutes les références à ceux-ci prennent du temps et influent sur la durée de « Stop the world« .
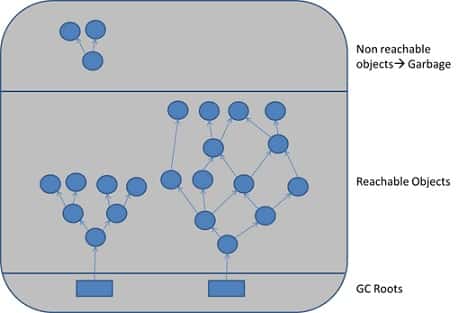
III/ Heap et Roots objects
Les objets sont représentés en mémoire à travers un arbre. Chaque arborescence d’objets doit avoir un ou plusieurs objets racine. Tant que l’application peut atteindre ces racines, l’arbre entier est accessible.
Il existe quatre types de racines GC en Java :
- Variables locales : maintenues en vie par une Stack de threads
- Threads actifs, toujours considérés comme live et donc racine GC
- Variables statiques, référencées par leurs classes
- Références JNI : objets Java créés à partir du code natif dans le cadre d’un appel JNI
IV/ Espace de stockage en Heap
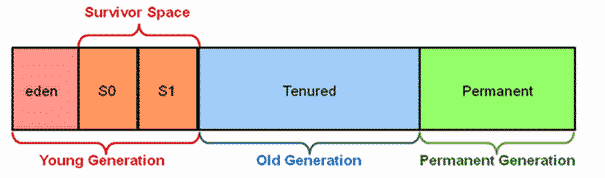
L’espace mémoire Heap est divisé en 3 zones, chacune contenant des références aux objets en les catégorisant en fonction de leur « âge ».
- Young Generation
Il contient les objets nouvellement créés et est à son tour divisé en un espace Eden, dans lequel les objets commencent leur cycle de vie, et en deux espaces Survivor, dans lesquels les objets sont déplacés pour faire de la place à la zone Eden.
- Old Generation or “Tenured Space”
Contient des objets durables qui sont finalement passés de la « Young Generation » à la « Old Generation ». Lorsque des objets sont « nettoyés » par Old Generation, on parle de Major GC. C’est la zone dans laquelle des objets qui ont vécu longtemps vont « mourir ».
- Permanent Generation
Il contient les métadonnées requises par la JVM pour décrire les classes et les méthodes utilisées dans l’application. Il est rempli par la JVM lors de l’exécution en fonction des classes utilisées par l’application. Toutes les implémentations GC ne permettent pas de nettoyer cet air de mémoire.
Important : depuis Java 8, Permanent Generation a été remplacé par Metaspace.
Nous avons dans cet article tenté de préciser davantage ce qu’était le concept de Garbage Collector afin de clarifier son rôle et surtout fonctionnement. Dès lors, il importe désormais d’entrer plus en détails dans sa manière de fonctionner pour bien en comprendre les principaux intérêts, et surtout les tenants et aboutissants.
Références
2: https://github.com/rohgar/scala-spark-4/wiki/Wide-vs-Narrow-Dependencies
3 : https://web.archive.org/web/20201201014628/https://blog.imaginea.com/spark-shuffle-tuning/
4 : https://slideplayer.com/slide/9851801/
5 : https://fr.wikipedia.org/wiki/Timsort
6 : https://www.waitingforcode.com/apache-spark/external-shuffle-service-apache-spark/read
https://spark.apache.org/docs/latest/configuration.html#shuffle-behavior


Vos commentaires
Très bien expliquer et instructif
Merci, c’est tres instructif !