
Les systèmes multi-agents, comme définis dans la première partie de cet article « L’intelligence artificielle, nouveau système multi-agent ». L’intelligence artificielle, nouveau système multi-agent », sont pleins de promesses. Cependant, pour en tirer le plein potentiel, il faut définir en amont l’architecture du système afin d’articuler de la manière la plus efficace possible les interactions entre les différents agents.

Architecture centralisée vs architecture décentralisée
Il existe deux principaux types d’architectures :
- Les architectures centralisées ;
- Les architectures décentralisées.
Centralisation
Dans une architecture centralisée, toutes les communications et tous les transferts de données ou d’informations transitent, et sont interprétés par un unique agent.
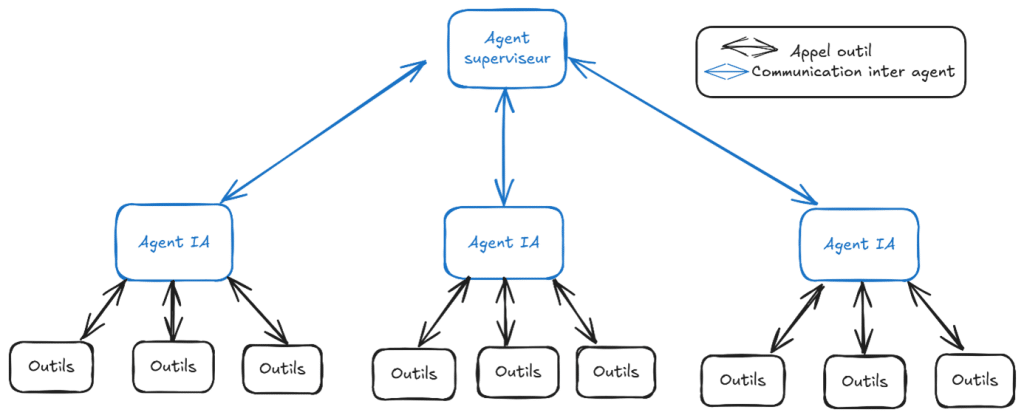
Cet agent du système, faisant office de chef d’orchestre, connaît l’état du système complet tandis que tous les autres n’ont qu’une connaissance locale de l’environnement.
Cette architecture propose de nombreux avantages. La coordination des agents est rendue plus facile par la vision d’ensemble du superviseur lui permettant d’appeler le bon agent, et d’optimiser la prise de décision et les performances globales du système. De plus, dans une telle architecture, les agents n’ont ni besoin d’analyser l’environnement, ni de prendre de décisions, ce qui permet d’alléger leur implémentation.
Malgré tous ses bienfaits, l’architecture centralisée a ses limites et ses inconvénients. Le premier d’entre eux étant le passage à l’échelle. Quand un unique agent s’occupe de coordonner tous les autres, il perd grandement en efficacité quand le nombre d’agents augmente. Imaginez un PDG qui doit manager individuellement l’ensemble de ses collaborateurs ! L’agent superviseur devient un goulet d’étranglement pour le système, incapable d’analyser en continu un large environnement en des temps raisonnables.
Reprenons les deux exemples de systèmes multi-agents mentionnés dans la première partie, en supposant qu’ils soient construits au sein d’une organisation centralisée.
Dans une ville intelligente centralisée, les feux de circulation changent d’état selon les directives d’un centre de commandement, les capteurs ne font que récolter des informations, sans les analyser, avant de les transmettre au cerveau du système. Une fois toutes les données et informations recueillies, le centre de commandement pourra transmettre des directives à chacun des agents pour faire tendre le système vers l’état visé.
Le réseau de véhicules autonomes centralisé, en raison d’allers-retours trop nombreux entre les différents agents et le superviseur, relève plus de l’expérience de pensée que d’une éventualité concrète. Mais prêtons-nous quand même à l’exercice. Dans un système de voitures autonomes centralisé, un centre de commandement est responsable de l’ensemble des décisions prises par tous les agents. Si une caméra (c’est-à-dire un outil de l’agent voiture) repère un enfant sur le point de traverser, l’information sera transmise à la voiture, puis au centre de commandement qui imposera à l’agent voiture de freiner. Les échanges d’information et d’injonctions répétés dans cet exemple coûteront au système des fractions de secondes précieuses.
Certains systèmes, tels que les véhicules autonomes, nécessitent une prise de décision instantanée qui n’est pas permise par une architecture purement centralisée où toute décision est prise par un agent principal. On comprend aisément que cette architecture présente de fortes limitations et ne peut pas être adoptée dans tous les contextes.
Et si votre IA savait enfin où chercher pour mieux répondre ?
👉 Découvrez notre article « Le RAG ou comment enrichir les modèles d’IA générative »
Décentralisation
Les architectures décentralisées sont une alternative prometteuse pour pallier ces problèmes de passage à l’échelle. Le principe est simple : répartir l’autorité et la responsabilité entre les différents agents.
La blockchain est un exemple de système décentralisé (mais sans IA). Cette technologie de stockage sécurisé et transparent de l’information repose sur un réseau de machines détenant toutes une copie de la blockchain. Chaque modification de la chaîne doit donc se faire avec l’accord de toutes les machines, ce qui, moyennant un nombre important de machines, garantit l’intégrité de l’information.
La blockchain est un système totalement décentralisé mais l’organisation de chaque système est unique et peut nécessiter une structure fortement organisée ou au contraire bien plus souple. Dans la pratique, les systèmes d’envergure utilisent souvent des organisations hiérarchiques dans lesquelles, comme au sein d’une entreprise, chaque agent est responsable de certaines actions, et gère d’autres agents et outils.
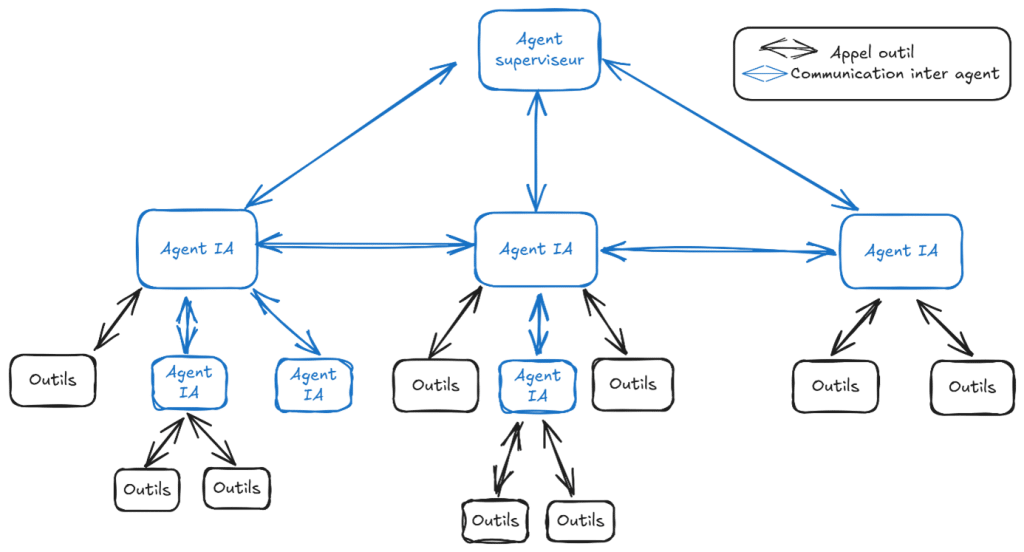
Les systèmes multi-agents IA décentralisés reposent sur des agents communiquant entre eux, et chacun dispose de la liberté de prendre ses propres décisions en fonction de ses connaissances locales, de l’environnement et des interactions avec d’autres agents.
En plus de faciliter le passage à l’échelle en évitant de surcharger un agent central responsable de toutes les prises de décision, les systèmes multi-agents décentralisés sont moins vulnérables à la casse ou au mauvais fonctionnement d’un agent. Chacun étant plus autonome, il saura s’adapter aux modifications de l’environnement. Cependant, toutes ces améliorations sont rendues possibles par une implémentation plus complexe et par conséquent plus coûteuse.
Observons désormais ce qu’il advient de nos exemples s’ils sont construits dans un système décentralisé. La ville intelligente décentralisée parvient à prendre des décisions beaucoup plus locales et à réduire les flux d’informations inutiles. Un capteur de luminosité transmet directement aux lampadaires du quartier la donnée qui leur indique s’il est nécessaire qu’ils soient allumés, tandis qu’un capteur de mouvement adapte la luminosité à la circulation des passants et des voitures pour ne pas éclairer toute la nuit des rues vides. Les feux de circulation adaptent leur durée aux voitures présentes aux carrefours à un instant T.
Ainsi, dans une architecture décentralisée, on peut multiplier les informations collectées sans crainte de surcharger le centre de commandement qui ne prend que des décisions globales, celle d’allumer l’ensemble des capteurs de luminosité par exemple.
Dans un réseau de véhicules autonomes décentralisé, chaque voiture avertit celle de derrière qu’elle va ralentir, qu’un piéton s’apprête à traverser au mauvais endroit, que le feu est passé à l’orange… Ces transmissions d’information se font sans intermédiaire permettant d’alléger l’analyse et le stockage global, et d’accélérer la prise de décision par tous les agents.
Envie de découvrir les derniers travaux de la cellule innovation de Meritis sur le RAG ?
👉 Découvrez notre article « Une quête d’innovation, le Multi-GraphRAG by Meritis »

Edge AI
Pour pousser la décentralisation encore plus loin, et réduire la latence et le temps de prise de décision, une autre solution est envisageable : l’« Edge AI » ou « IA en périphérie ». Cela consiste à placer des modèles de machine learning et d’intelligence artificielle directement sur des dispositifs IoT (Internet of Things), tels que des caméras ou des capteurs, plutôt que sur des serveurs distants ou dans le cloud. Les modèles sont alors directement appliqués sur la donnée collectée par leur hôte, sans aucun transfert.
Avec la multiplication des systèmes IA, les applications centralisées deviennent complexes et coûteuses en développement et en infrastructure. L’IA en périphérie permet de décentraliser davantage et de réduire le partage cloud de la donnée. En résultent une baisse des dépenses et de l’utilisation de la bande passante, mais surtout un gain considérable en sécurité puisque la donnée ne quitte jamais le hardware.
Grâce à la non-circulation de la donnée, les temps de latence du système sont réduits drastiquement. Dans le cas de la voiture autonome, comme dans beaucoup d’autres, la moindre milliseconde de latence peut avoir des effets considérables.
Apprentissage fédéré
Une autre perspective d’organisation, plus hiérarchique et moins centralisée, est « l’apprentissage fédéré ». Cela consiste à entraîner un modèle global à partir de ce que des modèles plus locaux ont appris mais en ne partageant que les poids et les biais des modèles, et non la donnée. Objectif : réduire la puissance de calcul nécessaire et la circulation de la donnée. Cela permet alors de respecter la confidentialité des données, notamment celles soumises au RGPD.
La procédure est la suivante :
- Le serveur global fournit aux serveurs locaux un modèle initial ;
- Chaque serveur entraîne ce modèle à partir des données qu’il a à sa disposition. Il crée une mise à jour locale du modèle ;
- Les serveurs locaux transmettent cette mise à jour au serveur global ;
- Le serveur agrège ces mises à jour pour améliorer le modèle global ;
- Le modèle global est renvoyé aux serveurs locaux et le cycle redémarre.
L’IA en périphérie et l’apprentissage fédéré permettent un plus grand contrôle de la circulation de l’information tout en maintenant les performances du système et en optimisant les temps de prise de décision. La démocratisation de ces approches de décentralisation est un pas de plus vers l’essor des systèmes multi-agents d’intelligence artificielle à grande échelle dans notre quotidien.
Vous souhaitez savoir comment l’IA apprend ?
👉 Découvrez notre article « Introduction au Deep Learning : les réseaux de neurones »

Conclusion
Quel sera l’impact du développement de tels systèmes ? Certes, la segmentation en sous-tâches plus simples et la recherche de spécialisation rendent compétitifs les plus petits modèles, moins coûteux et moins gourmands en énergie. Mais, comme démontré plus haut, ces systèmes favorisent aussi la prolifération des données. Nous dirigeons-nous alors vers une rationalisation de l’intelligence artificielle grâce à ces systèmes multi-agents ou vers des systèmes toujours plus complexes, coûteux et énergivores ?
Les tendances actuelles du marché de l’IA poussent à envisager plus sérieusement la seconde option pour les géants traditionnels du secteur pour qui le coût n’est pas un sujet et seule la performance compte. Ceux-là continueront certainement à utiliser et à produire des modèles toujours plus gros et toujours plus gourmands en puissance de calcul.
En janvier 2025, la société chinoise Deepseek est venue ébranler cette dynamique en proposant un modèle basé sur une architecture MoE (Mixture of Experts). Le modèle est basé sur plusieurs experts activés uniquement en cas de besoin. Ainsi, « seulement » 37 milliards de paramètres sont activés à la fois. Les acteurs les plus importants commencent à s’intéresser aux systèmes multi-agents. Cependant, ces architectures pourraient être une porte d’entrée pour des plus petits acteurs dans un secteur où seuls les géants semblent être en mesure de créer des produits de qualité opérationnelle. L’utilisation de modèles légers mais extrêmement performants au sein de la bonne architecture réduit drastiquement le ticket d’entrée pour des tâches précises et ouvre la voie aux plus petits acteurs.
Une jeune startup chinoise nommée Manus a récemment fait parler d’elle en dévoilant son « IA Générale » qui permet de réaliser des analyses approfondies des marchés financiers ou d’organiser intégralement des vacances au Japon et ce, en complète autonomie. Cela n’est qu’un exemple des applications de l’IA multi-agent qui voient le jour et repoussent toujours plus loin les frontières de l’imagination.
Au sein de la cellule Innovation de Meritis, nous avons récemment expérimenté un système multi-agent pour une tâche de détection d’incohérences. La donnée d’entrée du système est une base de connaissances d’entreprise. Nous avons développé plusieurs agents. Le premier pour extraire et reformuler les informations contenues dans les documents. Un second agent parcourt ensuite l’ensemble des informations extraites pour déterminer une liste de types d’information. Si leur nombre est trop important, un nouvel agent est appelé pour nettoyer cette liste et fusionner les types qui peuvent l’être. Ensuite, à chaque information est assigné un ou plusieurs types. Les informations de même type sont ensuite comparées deux à deux par un LLM afin de déceler d’éventuelles incohérences.
Nous avons testé notre système avec des modèles de tailles variables, de 8 à 123 milliards de paramètres. Tous testés sur les mêmes données, ils obtiennent des résultats très variés, et ce ne sont pas les plus gros les meilleurs ! Quoi qu’il en soit, les systèmes multi-agents ont le potentiel de devenir les David face à des Goliath déjà bien implantés. Affaire à suivre.
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.



Pas encore de commentaires