

Avec l’avènement de l’intelligence artificielle, l’essor des objets connectés et l’augmentation des capacités technologiques, nombreuses sont les recherches tentant de simuler le comportement humain et également de reproduire ses capacités cognitives. Dans ce contexte le Deep Learning, littéralement “l’apprentissage profond”, est actuellement un des axes de recherche les plus explorés.
– Alors qu’est-ce donc que le Deep Learning, qu’est-ce qu’un réseau de neurones, quel lien avec notre cerveau humain ?
– Comment cela fonctionne et surtout pour quelles applications ?
– Attachez vos ceintures et plongeons ensemble au cœur du Deep Learning.
I. Qu’est-ce que le Deep Learning ? (définition)
Pour comprendre le Deep Learning et surtout les réseaux de neurones, il ne suffit pas de s’intéresser aux mathématiques et à la technologie. Comprendre le Deep Learning, c’est avant tout remonter à l’élément central de notre vision du monde : l’être humain. L’Homme a en effet toujours cherché à reproduire, simuler l’Homme, de quelque façon que ce soit. Simuler l’humain, c’est chercher à reproduire les différentes capacités qu’il utilise au quotidien : sociales, comportementales, éthiques, physiques… Dans le lot, celle qui renferme le plus de mystère et qui sans doute revêt le plus d’attrait pour la recherche appliquée est la capacité cognitive. C’est elle qui nous permet de connaître, mémoriser, raisonner, apprendre ou encore parler.
Et le Deep Learning dans tout ça ? Son objet est précisément la simulation du cerveau humain par des procédés informatiques. Imaginez un ordinateur qui puisse stocker autant d’informations que notre mémoire et qui sache décider et agir en même temps ! Imaginez un Jarvis d’Iron Man !
Plonger dans le Deep Learning, c’est donner corps à ces concepts de science-fiction, se rendre compte que les avancées sont tangibles et les résultats déjà impressionnants. Les recherches des géants du secteur comme Facebook, Google ou encore Apple dans ce domaine nous le prouvent chaque semaine.
II. Du cerveau au réseau de neurones : comment fonctionne le deep learning ?
Revenons un instant sur la façon dont notre cerveau fonctionne : centre du système nerveux, il est capable d’intégrer les informations, de contrôler la motricité et d’assurer les fonctions cognitives. L’élément central du cerveau est le neurone.
Les neurones communiquent
Un neurone se compose d’un corps cellulaire, d’un axone qui représente le lien de transmission des signaux et d’une synapse qui permet le déclenchement d’un potentiel d’action dans le neurone pour activer une communication avec un autre neurone. Il faut savoir que la force d’un réseau de neurones réside dans la communication de ses neurones à travers des signaux électriques qu’on nomme « influx nerveux ». Ces signaux se caractérisent par des fréquences qui jouent un rôle important au niveau de la propagation des signaux dans le réseau en question.
Ci-dessous une représentation d’un neurone issu du centre de recherche ICM. ⤵
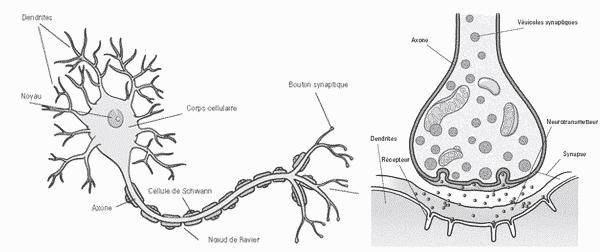
L’influx nerveux se propage le long de l’axone pour terminer son chemin au niveau de la terminaison synaptique. Plus la fréquence de celui-ci est importante, plus le neurone produit des substances chimiques : les neurotransmetteurs (ou neuromédiateurs).
Contenus dans les vésicules, ces derniers sont libérés dans le milieu extracellulaire au niveau de la synapse. Ils vont à leur tour activer ou inhiber un second neurone au niveau de sa dendrite ou de son corps cellulaire. L’influx nerveux poursuit son chemin le long de ce second neurone et ainsi de suite.
Pour résumer simplement et comprendre comment ça marche.
L’information est reçue par les dendrites sous forme d’un influx de neurotransmetteurs, se rassemble dans le corps de la cellule et s’écoule vers le bas de l’axone. Chaque neurone est relié à plusieurs neurones en “entrée” c’est à dire au niveau de ses dendrites et en “sortie” c’est à dire au niveau de son axone. C’est ce fonctionnement “entrée/traitement/sortie” qui a inspiré la recherche et a conduit à tenter de reproduire un neurone de manière artificielle.
Qu’est ce qu’un neurone en langage machine ?
Le concept de neurone artificiel fait partie des champs de recherche et d’action du Deep Learning, à tel point que les deux sujets sont souvent à tort confondus. L’objectif du Deep Learning est le suivant : prédire une sortie Y (une caractéristique) à travers un ensemble de données Xi en entrée, que l’on appelle les observations. Par exemple, voir une forme longue (X1), jaune (X2), courbée (X3) et tubulaire (X4) et prédire que c’est une banane (Y). Un des moyens d’y arriver mis en avant par la recherche a été de simuler la réponse d’un neurone dit “artificiel” à ces observations et de mettre au point un algorithme permettant de traiter et pondérer les observations pour en prédire une caractéristique.
Le graphe ci-dessous est une représentation d’un neurone artificiel, les dendrites reçoivent des signaux, la fréquence de chaque signal dépend du poids Wi. Ces signaux sont ensuites transmis vers le corps de la cellule. Cette dernière est caractérisée par deux éléments importants, la fonction d’activation et la condition d’activation. C’est en vérifiant la condition d’activation qu’on active l’axone pour émettre à nouveau des signaux aux neurones qui suivent à travers leurs dendrites et ainsi de suite.
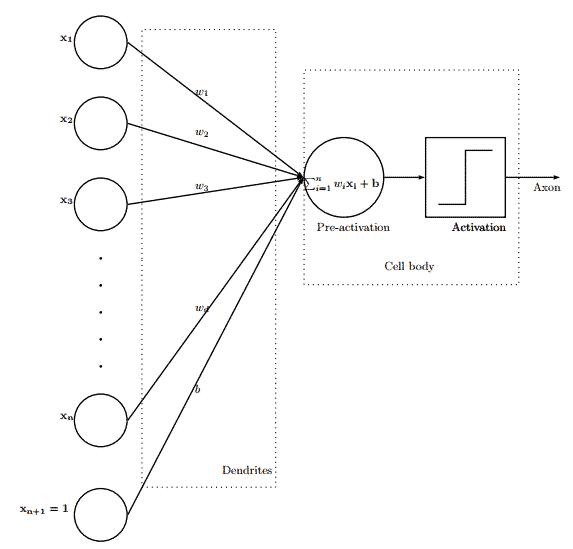
Cette représentation est appelée le perceptron, un algorithme d’apprentissage supervisé pour les classifications binaires linéaires. Cela fait beaucoup de mots inconnus alors arrêtons nous un instant sur chacun de ces termes car ils seront importants pour la suite !
- Algorithme : le perceptron est une suite d’opérations et de calcul = la somme des entrées, leur pondération, la vérification d’une condition et la production d’un résultat d’activation.
- Apprentissage : l’algorithme doit être “entraîné”, c’est à dire qu’en fonction d’une prédiction voulue, le poids des différentes entrées va évoluer et il faudra trouver une valeur optimale pour chacune.
- Supervisé : l’algorithme trouve les valeurs optimales de ses poids à partir d’une base de données d’exemples dont on connaît déjà la prédiction. Par exemple on a une base de données de photos de banane et on “règle” notre algorithme jusqu’à ce que chaque photo (ou presque) soit classé comme banane.
- Classification : l’algorithme permet de prédire une caractéristique en sortie et cette caractéristique sert à classer les différentes entrées entre elles. Par exemple, trouver toutes les bananes dans un panel de photos de fruits.
- Binaire : l’algorithme sépare un ensemble de valeurs d’entrée en seulement deux classes différentes (banane ou autre)
- Linéaire : l’algorithme sépare un ensemble de valeurs de manière linéaire. Prenons l’exemple d’une feuille de papier où vous auriez tracé une diagonale droite. Cette diagonale est une séparation linéaire de la feuille de papier. Si vous aviez tracé un rond au milieu de la feuille, la séparation sera considérée comme non linéaire.
Et si on revenait à la source ?
L’algo précédent est nommé : Perceptron simple. L’apparition du perceptron a eu lieu en 1957 au Laboratoire d’aéronautique de Cornell par Frank Rosenblatt. Avant de se manifester en tant qu’algorithme, le perceptron a été conçu initialement en tant que machine. Cette dernière avait pour but la reconnaissance d’image à travers un réseau de 400 photocellules reliées d’une manière aléatoire (représentation artificielle des liaisons de neurones). Les poids ont été encodés dans des potentiomètres et leurs mises à jour s’effectuaient à travers des moteurs électriques.

L’algorithme du perceptron simple présente un inconvénient de taille quand il est appliqué à des cas de la vie réelle : sa linéarité. En effet, tout ne peut pas être séparé et classé en traçant une droite sur une feuille de papier. L’exemple du classificateur de banane utilisé plus haut en est la preuve. Il a donc fallu trouver un moyen de répondre à cette non linéarité, et c’est là que la notion de profondeur est arrivée. Le passage d’un perceptron simple (une couche de neurones) à un perceptron multi-couches est une des réponses à cette problématique, c’est l’apparition des réseaux de neurones profonds.

III. Comprendre les réseaux de neurones profonds
Un réseau de neurone profond consiste en des milliers voire des millions de neurones organisés en couches interconnectées grâce à des liens pondérés (Wi). Chaque nœud est caractérisé par l’ensemble {Fi(fonction d’activation) + Ci(condition d’activation)}. Le travail de l’apprentissage est donc de trouver la combinaison optimale des Wi/Fi/Ci pour générer les meilleurs résultats en termes de prédiction et d’estimation.
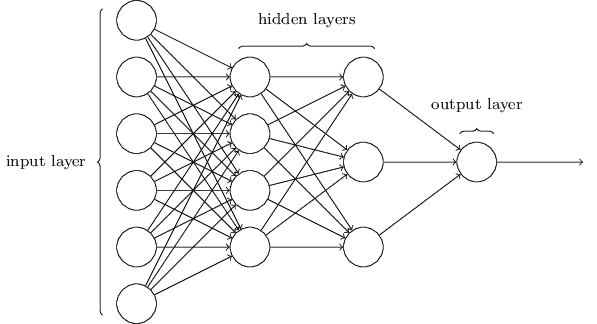
Nous venons maintenant de traiter la non linéarité mais comment désormais entraîner notre réseau et trouver les valeurs de ses millions de poids ? Parmi les diverses solutions envisageables, une des plus utilisées est la backpropagation.
Backpropagation : comment cet apprentissage est fait concrètement ? (comprendre l’algorithme)
Phase d’apprentissage
Entrée X d’exemple => Réseau de neurones => Sortie Y préalablement connue
Dans cette étape, on va d’abord chercher à construire un modèle qui nous servira dans un second temps à faire des prédictions. Comme mentionné plus tôt, l’idée est de déterminer la bonne combinaison des Wi/Fi/Ci. Pour ce faire, on définit une fonction d’erreur qui calcule la différence entre la sortie réelle du réseau et sa sortie attendue après qu’un cas a circulé à travers le réseau.
Soit Y et Y’ deux vecteurs respectivement la sortie réelle et la sortie attendue du réseau.
L’erreur de rétropropagation est E ( Y, Y’ ) = (1/2)*square(|| Y – Y’ ||)
A travers cette fonction perte, on cherche à optimiser le modèle (ie Wi/Ci/Fi) de tel façon à minimiser E ( Y, Y’ ).
Cas concret avec l’utilisation de R
D’après http://gekkoquant.com
library(neuralnet)
#Chargement de la librairie neuralnet
#Création d’un réseau de neurones basé sur la Backpropagation
#Récupération des données en entrée et leur sortie attendue
traininginput <- ...
trainingoutput <- ...
#Assembler les Xi Y en une seule variable
trainingdata <- cbind(traininginput,trainingoutput)
colnames(trainingdata) <- c("Input","Output")
#Training du réseau de neurones avec backpropagation
#Dans notre exemple, le réseau aura 10 couches intermédiaires. Avec un seuil pour la fonction d’erreur de 0.01. Ce seuil servira de condition pour arrêter l'entraînement du modèle.
model <- neuralnet(Output ~ Input, trainingdata, hidden=10, threshold=0.01)
#neuralnet peut prendre plusieurs autres paramètres optionnels, les poids initiaux Wi, le nombre de répétition des propagations etc.. que je vous invite ici.
Revenons sur les quelques lignes de code ci-dessus. Dans un premier temps, l’initialisation des poids Wi se fait aléatoirement ce qui mène à avoir une sortie Y’ qui permettra de calculer E (Y, Y’ ).
Vient ensuite l’étape de la rétropropagation :
Pour chaque neurone k = {1, . . . , n}, on calcule l’erreur propre au neurone en question ε(k). On met à jour ensuite les poids et on propage ainsi de suite jusqu’à atteindre le seuil d’erreur préalablement fixé.
On peut donc enchaîner directement vers la phase de prédiction une fois le modèle conçu.
Phase de prédiction
Entrée X d’exemple => Réseau de neurones => Sortie Y à prédire
OutputPred <- compute(Model, NewDataSet) #Modele conçu, Nouvelles entrées Xi
Les réseaux profonds ont révolutionné la reconnaissance d’image. Le chercheur en intelligence artificielle et vision artificielle Yann LeCun a notamment abouti à des résultats surprenants grâce aux modèles de réseaux profonds dits Réseaux convolutifs (souvent abrégés en CNN pour Convolutional Neural Networks).
Reconnaissance d’image : l’une des applications parmi les plus intéressantes
L’idée est de pouvoir classifier une ou plusieurs images, par exemple : est-ce que cette photo est celle d’un visage ?. Pour ce faire, il est crucial dans un premier temps de convertir notre image en une matrice (les dimensions étant le nombre de pixels) qui sera l’input (entrée) de notre classifieur (Régression linéaire/ non linéaire, Perceptron, Réseau de neurones etc…).
Le premier réseau profond conçu pour la reconnaissance des images a été élaboré par Yann LeCun, chercheur en intelligence artificielle chez Facebook. Le réseau a été mis en place en 1998 et a été nommé LeNet.
Le schéma ci-dessous résume son architecture :
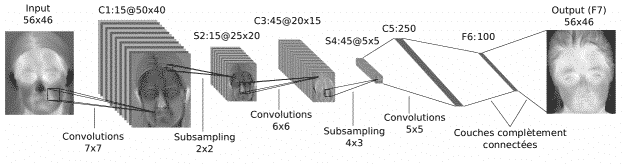
1. Convolution
La première étape dans cette architecture est celle de la convolution de l’image que l’on souhaite classifier. La convolution est le fait de mettre en valeur quelques caractéristiques bien choisies dans l’image source afin d’avoir la même image mais avec une sorte de filtre, comme vous pouvez le voir dans l’image de l’étape 2, l’accent est plutôt mis sur le contour du visage. Cette opération est faite en appliquant une matrice prédéfinie sur la matrice source de l’image initiale. Il faut savoir qu’il existe plusieurs matrices de convolutions et chacune d’entres elles vise un aspect particulier de l’image. Lors de cette première étape, plusieurs filtres de convolutions sont appliqués sur l’image initiale, conduisant donc à la génération de plusieurs images distinctes au niveau de la forme.
2. Pooling
La deuxième étape, dite pooling, consiste en la réduction des dimensions des images (matrices). Le but de cette étape est de garder le maximum d’informations pertinentes même en réduisant les dimensions. Les fonctions de pooling les plus utilisés sont (max/avg pooling).
Les étapes de Convolution et de Pooling sont ensuite itérées autant de fois que nécessaire jusqu’à ce que toutes les caractéristiques de l’image soit classifiées (exemple ici : le contour du visage, les yeux, le nez, la bouche…)
3. Fully connected
L’étape des couches complètement connectées est tout simplement l’application d’un réseau de neurones classique à toutes les caractéristiques classifiées par les étapes précédentes. L’output de ce réseau se réduit finalement à une probabilité qui permet de préciser à quel degré l’image en question est bien un visage !
4. La Compétition ImageNet
La compétition ImageNet est un challenge international où des équipes de recherches s’affrontent à coup d’algorithmes de reconnaissance d’image. Chacun dispose de la base ImageNet et doit fournir la classification la plus juste possible. Lors de cette compétition l’impact de l’introduction des réseaux convolutifs a été impressionnant ! L’image ci-dessous nous montre comment le taux d’erreurs des modèles conçus a baissé d’une manière significative (en rouge les modèles CNN) :
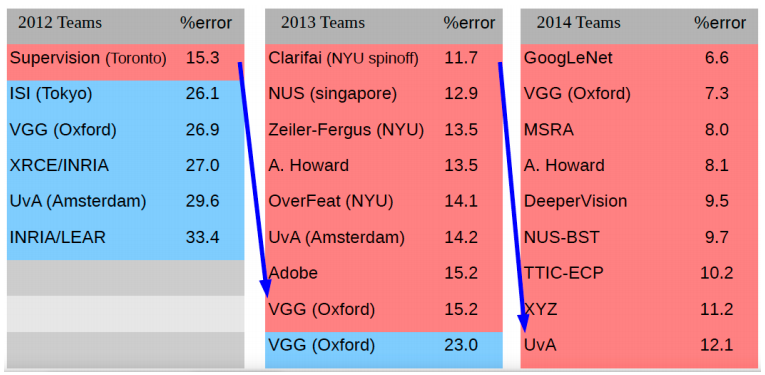
Conclusion
Le concept de neurone artificiel et de Perceptron n’est pas une découverte “récente” dans le monde des mathématiques et de la programmation (déjà plus de 60 ans). Mais cette découverte est arrivée beaucoup trop tôt au regard de la puissance de calcul disponible à l’époque et du volume de données à traiter. C’est pourquoi il a fallu du temps pour que ces concepts qui constituent le coeur de la recherche du Deep Learning trouvent des applications concrètes.
Entraîner un algorithme de classification de banane n’aurait jamais été rentable au vu des sommes astronomique de temps et d’argent requises, mais la donne a changé ces dernières années avec l’augmentation de la puissance de calcul et la réduction des coûts associés. Même un particulier peut aujourd’hui envisager de mettre sur pied un réseau de neurones (pas trop) profond et l’entraîner chez soi ou sur le cloud. C’est donc la combinaison d’une baisse des coûts et des temps de calcul ainsi que d’une augmentation exponentielle du volume de données à traiter qui a redonné vie au Deep Learning, et force est de constater que ces deux tendances ne sont pas prêtes de s’inverser. Après tout le Deep Learning est déjà rentré dans notre quotidien par le biais du système de recommandation de Netflix ou encore de Face ID, la reconnaissance faciale made by Apple, et les applications concrètes ne cessent d’être de plus en plus bluffantes !
Le moteur de recherche du géant américain « Google » est lui aussi de plus en plus performant et ne cesse de nous étonner. Grâce à ses programmes, ensemble de techniques et algorithmes il est devenu capable d’avoir une détection automatique de nos intentions de recherches de l’utilisateur.
Le deep learning s’applique à tous les secteurs d’activité. Découvrez dans cet article rédigé en anglais, le Deep Learning appliqué à l’industrie médicale.
————————
Comme eux, vous pouvez également exploiter votre data et mettre en place des algorithmes capables d’imiter le comportement humain, de reproduire des capacités cognitives et/ou des analyses prédictives.
Meritis peut vous accompagner dans votre stratégie data d’entreprise grâce à l’IA et au deep learning.
Nous mettons en place des experts pluridisciplinaire afin de mener à bien tous vos projets Data.
Parmi eux on retrouve, des Data Scientist, Data engineer, Expert IA, Expert Deep Learning, Expert en Machine Learning et bien d’autres experts Meritis.
Contactez-nous pour en savoir plus.
?? Vous souhaitez approfondir vos connaissances en IA ? Découvrez notre article qui explique le fonctionnement du Machine Learning




Vos commentaires
je travaille sur la synthese de la parole à partir du texte avec les SMS et j’aimerai savoir comment il est possible d’utiliser le deep learning pour la réalisation d’un systeme TTS pour les SMS
Que pensez-vous du blob ? D »autres formes d’intelligence que humaine peuvent exister,n’est ce pas? Une neurologie decentralisee et non hierarchique peut etre possible…Les réseaux de neurones ne sont pour l’instant que des annuaires logiques améliorés…
J’aimerais savoir comment implementer une application deep learning dédiée à la reconnaissance de signature manuscrite cursive en ligne(on line). Merci
Bonjour, vulgarisation intéressante. Un point de détail, on n’entraîne pas un algorithme, c’est lui qui entraîne un modèle. Le MLP est un modèle particulier, comme le RBF. Les deux ont la même architecture, mais la formule qui permet d’intégrer l’information dans le neurone, avant l’activation, est différente. Il y a des dizaines d’architecture de RNA différentes, et autant d’algorithmes d’apprentissage; un même algorithme pouvant être appliqué sur plusieurs architectures.
Un point intéressant à développer, au delà de l’aspect technique, est l’aspect éthique. Un RNA est un modèle aveugle, qui n’a aucune conscience de ce qu’il fait, et qui peut être aussi bien utilisé en bien, qu’en mal. Les avancées depuis ces dernières années ont placé ces outils au centre de nombreux processus, et l’éthique se pose réellement comme un risque majeur aujourd’hui. La pénétration de ces technologies dans notre quotidien demandent à ce que chaque nouvelle application soit mûrement réfléchie quant à son impact social. La technologie n’est pas la réponse à de nombreux problèmes, et se cacher derrière n’est que le signe d’une grande faiblesse d’esprit (ou d’une malhonnêteté inavouée, non la technologie n’est pas toujours là pour notre bien, elle sert aussi à tracer ce que chacun fait ou pense via les réseaux sociaux ou les applications « intelligentes » sur les smartphones; elle offre donc à toute dictature potentielle un outils inestimable et inespéré, il y a 20 ans encore).
Rabelais disait : « science sans conscience n’est que ruine de l’âme… »
.
Ce que je n’arrive pas à savoir, c’est si après la phase d’apprentissage le système continue à apprendre?
Dit autrement, une machine qui a appris à détecter une banane à partir d’une base de données peut continuer à s’améliorer avec le temps?
Un peu comme nous…
Car ça change tout, tout devienne possible si elle continue à apprendre….
Bonjour, Sur des algorithmes standards, l’apprentissage est une phase qui permet de s’adapter au données présente. L’utilisation qui est faite ensuite de cet algorithme ne lui permet donc pas de s’améliorer.
Cependant, il existe des techniques dites de renforcement Learning qui permette de « corriger » l’apprentissage. Mais il faut le prévoir dans la conception du workflow d’apprentissage.
Merci bien ces informations, je suis dans mes premiers pas.