
Début 2026, nous disposons désormais d’un recul significatif sur l’adoption de l’intelligence artificielle générative en entreprise. Quelques rapports pertinents voient en effet le jour sur la maturité des entreprises et la concrétisation de leurs projets. McKinsey, Deloitte et MIT se sont récemment penchés sur le sujet, en tirant de premières conclusions grâce à des études menées au niveau mondial et sur plus d’un millier d’entreprises.
Cependant, comme le révèlent les rapports récents de Deloitte et du MIT, les dirigeants d’entreprises font face à des défis majeurs pour concrétiser leurs ambitions, notamment en matière de qualité des données, d’infrastructures et de gouvernance. Bien que le potentiel opérationnel de ces technologies soit aujourd’hui indéniable, nous allons voir dans cet article que leur concrétisation est souvent plus compliquée que prévu.

Avantages de l’IA générative en entreprise : adoption et ROI
Depuis 2024, la plupart des grandes entreprises ont massivement investi dans les projets d’intelligence artificielle et plus particulièrement dans les solutions d’IA générative, disposant désormais d’un recul significatif sur leur retour sur investissement. Une approche proactive dans l’implémentation de ces technologies s’avère essentielle pour capturer pleinement leur valeur et transformer l’expérience client.
Selon une étude de McKinsey de mars 2025 (1), 78% des entreprises utilisent l’IA au sens large pour au moins une fonction business en 2025. Entre 2023 et 2025, l’utilisation de l’IA Gen pour au moins une fonction est passée de 33% à 71%.
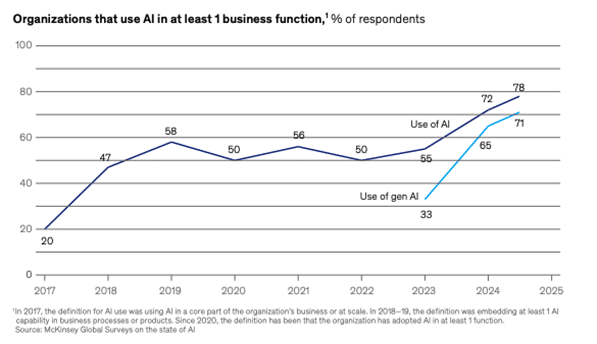
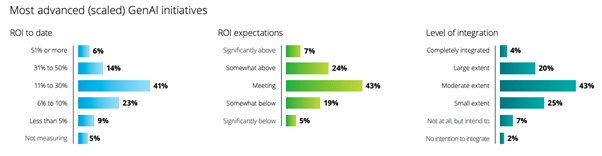
Par ailleurs, Deloitte rapportait dans une étude de janvier 2025 (2) que 74% des projets d’IA générative complètement scalés et déployés en production ont un ROI conforme ou supérieur aux estimations et 78% des entreprises interrogées prévoyaient d’augmenter leurs investissements en IA sur l’année fiscale suivante.
On peut donc considérer que le « jeu en vaut la chandelle » quand les projets arrivent à maturité, mais une gouvernance solide reste indispensable pour concrétiser ces initiatives.
Pour approfondir cette thématique, découvrez les cas d’usage IA générative entreprise les plus performants et leurs facteurs de succès.
Cas d’usage IA générative : assistants virtuels, marketing et personnalisation
Selon les études récentes, cinq applications d’IA générative se démarquent nettement dans les grandes entreprises, chacune offrant une forte valeur ajoutée pour la prise de décision et l’automatisation des tâches répétitives :
Assistants de code : Premier cas d’usage en adoption rapide avec un ROI immédiat (20% à 50%). Ces assistants génèrent et optimisent du code, créent de la documentation technique et accélèrent le débogage, transformant radicalement la productivité des équipes de développement.
Agents internes et automatisation intelligente : Les directions métiers déploient massivement ces assistants basés sur LLM. Un agent RH analyse des centaines de CV en quelques secondes, un agent juridique synthétise des contrats complexes, tandis qu’un agent financier génère automatiquement des rapports d’analyse mensuels. Ces usages améliorent la productivité, la qualité des décisions, et s’appliquent à énormément de métiers différents.
Synthèse d’informations internes (RAG) : La capacité à récupérer, synthétiser et présenter rapidement les données de l’entreprise constitue un avantage compétitif. Les systèmes RAG permettent la recherche avancée d’informations et la génération instantanée de documents synthétiques à partir de multiples sources.
Service client augmenté : Dépassant largement les FAQ, les chatbots accompagnent désormais les clients dans des démarches complexes (prêts bancaires, assurances) et traitent les demandes en quasi-temps réel, réduisant les coûts de support de 20-30 % tout en améliorant la satisfaction client.
Marketing et hyper-personnalisation : Au-delà de la simple création de contenu (articles, visuels, emails), l’enjeu est l’adaptation automatique de chaque message au profil spécifique du client et la déclinaison instantanée des campagnes mondiales en versions locales personnalisées avec des gains de temps de production considérables.
Toutes ces applications d’IA générative ont un point commun : elles requièrent des fondations d’infrastructure data et une gouvernance solides pour livrer des résultats convaincants.
Les obstacles de l’IA générative : 7 défis majeurs à surmonter
Lorsque les dirigeants envisagent d’intégrer l’IA générative dans leurs fonctions métiers, les ambitions se heurtent rapidement à la réalité opérationnelle car généralement assez vagues et portées vers le résultat.
De nombreux POCs sont réalisés, pour peu de concrétisation. Comme le révèle l’étude de Deloitte de 2025, 70 % des organisations ont 30 % ou moins de leurs POCs qui atteignent la maturité en 3 à 6 mois. Ce taux est comparable aux POCs historiques (IoT, digital, data), mais la GenAI concentre cet écart sur un horizon beaucoup plus court (3 à 6 mois vs >12 mois), ce qui accentue la perception d’échec.
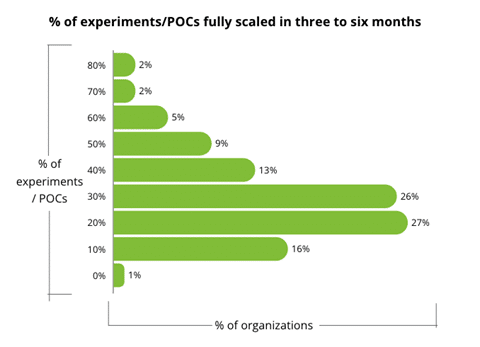
Pour comprendre ce chiffre, il faut réaliser qu’une initiative IA est indissociablement liée à une stratégie data au sens large. Ce décalage entre ambition et concrétisation s’explique par sept points de friction majeurs :
- Qualité des données insuffisante : Plus d’un tiers des entreprises européennes citent la mauvaise qualité des données comme obstacle principal à la concrétisation de leurs projets d’IA générative.
📖Ces problèmes de qualité sont précisément ce qui empêche les projets de passer en production. Découvrez comment les anticiper dans notre livre blanc sur l’industrialisation des projets IA - Infrastructures cloisonnées : La combinaison d’infrastructures héritées, de systèmes obsolètes et d’un manque de gouvernance freine l’adoption de technologies prometteuses.
- Compétences internes & Gouvernance Data : Selon une étude de Forbes Insights (5), 83 % des organisations considèrent la gestion des données comme leur principal défi. 43 % estiment leurs outils analytiques et infrastructures dépassés. En France, seuls 25 % des décideurs déclarent disposer de données disponibles en temps voulu. Le manque d’expertise interne sur les métiers spécifiques de la Data & l’IA est également cité régulièrement.
- Sécurité et propriété intellectuelle : La gestion de la confidentialité pour l’utilisation des données et du cadre légal est une problématique récurrente qui freine de nombreuses initiatives. Les entreprises veulent continuer à maîtriser leurs données et la protection de leur propriété intellectuelle est fondamentale.
- Observabilité des coûts : Une infrastructure mature ne doit pas seulement être performante, elle doit être rentable. C’est un argument clé pour les décideurs. Comprendre la facturation des modèles et notamment la facturation au token est une nouveauté pour les DSI. L’observabilité joue un rôle majeur dans la gestion de cette problématique.
- Intégration aux workflows : La limitation de l’intégration aux workflow des modèles d’IA est une autre grosse contrainte soulevée par le MIT (4). Les IA Agentiques ont notamment besoin d’effectuer des actions sur des services connectés. Il est donc nécessaire d’exposer des API pour permettre ces communications, ce qui entraîne des contraintes techniques et de sécurité des SI.
- Responsabilités RSE : L’utilisation des technologies d’IA générative implique un fort impact Green IT qu’il est nécessaire de mesurer finement et limiter. Il faut ainsi utiliser des solutions bien dimensionnées pour les cas d’usage identifiés, notamment dans le choix des modèles.
Les offres IA Gen Business en SaaS et l’importance de la préparation des données
De plus en plus d’offres business d’IA génératives proposent une offre SaaS plug and play permettant d’intégrer de l’IA directement dans le workplace ou de connecter directement les repositories de l’entreprise et ainsi, d’utiliser la puissance des fonctionnalités d’IA Genérative directement sur leurs données.
Il ne s’agit plus uniquement de se différencier par les modèles, mais par tout l’écosystème autour de l’utilisation de l’IA Gen.
- Open AI propose notamment une offre GPT-Business incluant des connecteurs pour l’ensemble de la suite Google, Teams, mais aussi Dropbox, Github, Notion et beaucoup d’autres.
- Microsoft et Google proposent des fonctionnalités similaires, cette fois-ci directement intégrées aux écosystèmes Google workspace et Office 365.
- Claude en version entreprise propose des fonctionnalités similaires, mais plutôt orienté développement logiciel.

Concrètement, comment cela fonctionne ?
La préparation des données constitue le socle fondamental des solutions d’IA générative en entreprise. Pour exploiter un foundation model sans réentraînement, l’approche Retrieval Augmented Generation (RAG) s’impose.
Un RAG est une architecture qui étend un LLM en lui donnant accès à des données indexées de l’entreprise, afin qu’il puisse les utiliser dans ses réponses. Lorsqu’une source de données externe est connectée, les données sont récupérées, indexées et vectorisées pour pouvoir être utilisées par le LLM. Ce traitement, normalement chronophage, est rendu presque instantané par une parallélisation massive des traitements (scaling horizontal), une utilisation des modèles d’embedding très rapides, et un découpage intelligent (smart chunking).
S’il est donc possible ici d’utiliser des foundation models pré-entraînés et prêt à l’emploi en connexion directe et ainsi s’affranchir de la phase d’entraînement, la problématique de la qualité et de la préparation des données reste centrale. En effet, les résultats sont directement liés au niveau de qualité en entrée. Les foundation models associés à un RAG ont la capacité de gommer certains défauts en sortie, mais n’échappent pas à la règle.
Il faut bien comprendre ici que la préparation des données influence toutes les étapes du pipeline d’IA : ingestion, indexation, vectorisation, recherche et génération.
Impact sur l’ingestion :
- Fichiers mal nommés ou mal classés → indexation chaotique
- Versions multiples → confusion pour le moteur de récupération
- Formats non supportés et mal encodés → perte d’information
Résultats : peu de résultats en recherche et des informations incomplètes
Impact sur la vectorisation et l’indexation :
- Documents mélangés (contrats + mails + notes internes dans un même PDF)
- Mauvaises structurations (longs fichiers non segmentés)
- Blocs de texte irréguliers → embeddings moins cohérents
Impact sur la recherche :
Si la donnée est :
- Redondante
- Contradictoire
- Dispersée dans de multiples fichiers
- Non normalisée
alors l’IA récupère du bruit au lieu d’informations pertinentes, même si GPT-5 ou un autre modèle performant tourne derrière.
Résultats : hallucinations, réponses floues, citations incorrectes
Impact sur la génération :
La génération finale dépend intrinsèquement de la qualité des données source. Des données médiocres induisent des réponses médiocres. Des données propres et bien structurées induisent des réponses fiables, pertinentes, contextualisées.
La génération finale dépend intrinsèquement de la qualité des données source. Des données médiocres induisent des réponses médiocres. Des données propres et bien structurées induisent des réponses fiables, pertinentes, contextualisées.
C’est notamment là que se heurtent de nombreux projets. Des données incomplètes, obsolètes ou incohérentes conduisent les modèles à produire des résultats biaisés. Les silos de données ou l’absence de gouvernance claire peuvent également priver le modèle d’une vision globale, limitant la pertinence de ses analyses et l’évolutivité.
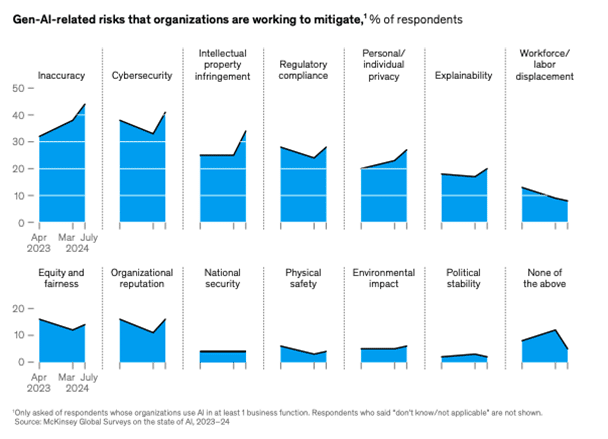
Concrètement, cela signifie que les projets d’IA peinent à dépasser le stade du prototypage, car les entreprises ont besoin avant tout de fiabilité. En effet, selon McKinsey, la moitié des entreprises indiquent qu’elles vérifient peu les résultats générés par IA, et selon Deloitte, 35% des entreprises interviewées indiquent que leur barrière principale à l’adoption des IA Génératives sont les erreurs générées, ayant des conséquences sur les opérations. La barrière n’est donc pas technologique mais organisationnelle.
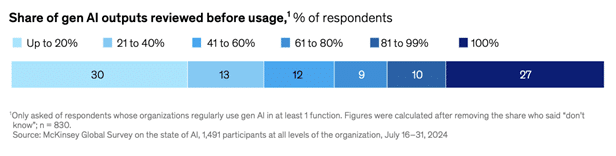
Il faut bien comprendre ici que la préparation des données influence toutes les étapes du pipeline d’IA : ingestion, indexation, vectorisation, recherche et génération.
Sécurité et gouvernance des données pour développer l’IA générative
La sécurité des données représente un point d’attention majeur dans les projets d’IA générative. Traditionnellement, les entreprises gèrent leurs données de manière cloisonnée, avec des politiques d’accès strictes et une gouvernance centralisée au niveau de la DSI (ou un manque pur et simple de gouvernance)
Pour concrétiser une initiative d’IA Gen, la démarche repose sur un principe opposé : le rassemblement et l’indexation de données hétérogènes pour alimenter le modèle. La gouvernance doit également être solide avec des données correctement classifiées, avec les bonnes métadonnées de sécurité, et une fragmentation maîtrisée entre les différents outils de l’entreprise.
Une gestion des flux de données maîtrisée est essentielle pour éviter la fuite de données exposées au modèle.
Les principaux risques incluent :
- Fuites internes : Les données utilisées pour entraîner le modèle ne doivent pas être diffusées aux personnes n’ayant pas l’autorisation de les consulter.
- Fuites externes : L’exposition de modèles via des API externes ou services Cloud crée des vulnérabilités, particulièrement dans des secteurs comme la santé ou la banque où les exigences réglementaires diffèrent.
- Vulnérabilités aux attaques adverses : L’IA agentique, capable d’actions autonomes, introduit de nouvelles surfaces d’attaque comme l’injection de prompt ou le model poisoning.
Pour répondre à ces enjeux, l’approche zero trust s’impose comme standard. Les RAG avancés intègrent désormais des « pré-prompt layers », « context isolation » et « filtrages post-retrieval » pour retraiter les prompts initiaux et cloisonner les demandes. Les fonctionnalités apportent des solutions, mais une gestion de la gouvernance des données reste primordiale dans l’ensemble des cas d’usage.
Ainsi, avant de déployer l’IA Gen à l’échelle, des prérequis techniques et de gouvernance sont indispensables pour garantir une fiabilité durable, adaptée aux spécificités sectorielles.

Les fondations d’une entreprise data driven : données, intégration et gouvernance
L’intelligence artificielle en entreprise n’est plus une simple option mais une nécessité stratégique. Cependant, il existe un décalage significatif entre les ambitions et la concrétisation des projets d’IA. Évaluer son niveau de maturité data permet aux organisations, particulièrement aux moyennes entreprises, de comprendre les fondamentaux nécessaires pour réussir.
Il faut garder à l’esprit que chaque architecture data est différente en fonction des cas d’usage et de la topologie de l’entreprise. Cependant, il y a des questions qui doivent systématiquement être adressées, peu importe le contexte. On peut notamment citer l’importance de mettre en place :
- Des données fiables et accessibles : La qualité et l’accessibilité des données (internes et externes) constituent le socle de tout projet IA, avec une gestion des métadonnées centrale pour la classification et la sécurité.
- Une infrastructure performante : Puissance de calcul, stockage massif et scalabilité, généralement via des solutions cloud.
- Une gouvernance solide : Conformité RGPD, traçabilité, gestion claire des droits d’accès et un « AI Security Framework » dérivé du zero trust avec un data lineage étendu à l’IA.
- Des compétences spécialisées : Data engineers, Data architects, Data analysts, MLOps, data Scientists/AI Engineers, responsables organisationnels, Data manager/Data Stewart : Une équipe data doit être suffisamment structurée et doit pouvoir évoluer en fonction des besoins.
- Une intégration fluide : Les modèles d’IA doivent s’interfacer avec les systèmes existants (CRM, ERP, e-commerce…) pour s’alimenter, ce qui nécessite des API.
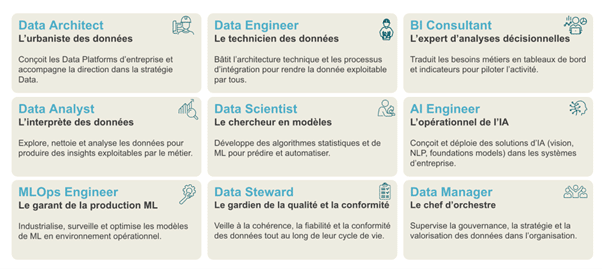
La stratégie à adopter doit également s’adapter aux besoins de toutes les parties prenantes au sein de l’entreprise, sans favoriser un pôle, mais sans négliger une fonction et leurs priorités.
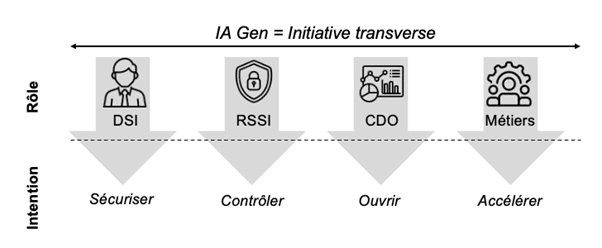
En somme, pour exploiter l’IA à grande échelle, les DSI doivent doter l’entreprise d’une fondation évolutive et bien gouvernée, tout en s’assurant d’avoir les bonnes compétences et une stratégie d’intégration.
C’est uniquement à ces conditions que les projets d’IA Gen peuvent passer au stade de production et réaliser tout leur potentiel.
Maturité data et intégration IA : évaluer son niveau pour passer à l’échelle
Lorsqu’un manque de résultat est identifié, les initiatives sont souvent stoppées ou dé-priorisées. Il est donc primordial d’évaluer sa maturité et mettre en place des processus d’amélioration itératifs. Afin de se positionner, définissons les grands niveaux de maturité que l’on retrouve dans les entreprises :
Niveau 1 : Fragmentation et bricolage
Les données sont éclatées dans une multitude de fichiers et d’outils (Excel, Divers Drives, silos départementaux…). Il n’y a pas de gouvernance en place, et pas de référentiel commun. Ce niveau de maturité implique des erreurs fréquentes, une lenteur d’accès à l’information, une faible évolutivité. À ce stade, l’entreprise reste très artisanale dans sa gestion de la donnée.
Niveau 2 : Centralisation partielle
Un premier pas est fait avec la mise en place de certains outils de centralisation des données, typiquement un entrepôt de données (data warehouse) ou un data lake. Une gouvernance commence à apparaître. L’idée est d’avoir un référentiel unique pour les données clés (clients, ventes, etc.). Toutefois, la centralisation est souvent incomplète : certains départements continuent à travailler en autonomie. La qualité des données progresse, mais la gouvernance reste encore limitée.
Niveau 3 : Infrastructure moderne et gouvernée
L’entreprise franchit un cap en modernisant ses architectures, souvent via le cloud ou un modèle hybride. Les données structurées (tables, bases SQL) comme non structurées (texte, images, logs, etc.) sont prises en compte. On trouve :
- Des pipelines de données automatisés pour fiabiliser les flux,
- Les données sont nettoyées et de bonne qualité/fiabilité,
- Des règles de gouvernance sont établies (catalogues, référentiels maîtres, politiques d’accès),
- Des équipes data et fonctionnelles sont formées pour assurer la cohérence et commencent à mettre en place du MLOps, les premiers cas d’usage IA.
Niveau 4 : Organisation data-driven et architecture évolutive
Au plus haut niveau, la donnée devient un véritable produit. Les équipes métiers y accèdent directement via des “data products” documentés et gouvernés. Les architectures reposent sur des approches modernes comme la Data Fabric ou le Data Mesh, connectées à l’ensemble des sources (SaaS, IoT, bases on-premise, etc.). Les décisions se prennent sur des données fiables et disponibles, et l’IA est intégrée dans les processus clés.
Bien entendu, ces niveaux sont schématiques. Néanmoins, ce cadre aide à évaluer où l’on se trouve et quelle est la prochaine étape pour évoluer. Or, beaucoup d’entreprises réalisent aujourd’hui qu’elles stagnent à un niveau de maturité insuffisant (1 ou 2) vis-à-vis des ambitions qu’elles nourrissent en IA. De manière réaliste, l’intégration de l’IA Gen pour une utilisation à grande échelle en entreprise nécessite à minima un niveau de maturité 3 pour garantir suffisamment de fiabilité et de résultats.
Des exemples français de transformation Data et IA : impact mesurable
De grands groupes français ont entrepris des évolutions majeures de leur infrastructure data pour concrétiser leurs ambitions à l’échelle :
(6) L’Oréal : Transformation Data & IA Driven : Le leader mondial a opéré une mutation profonde. En centralisant les données de plus de 30 systèmes (ERP, CRM, PIM) via une plateforme unifiée, L’Oréal a pu déployer des services innovants à grande échelle.
- Cas d’usage : Lancement de L’Oréal GPT (interne) pour assister les collaborateurs et développement d’outils comme TrendSpotter pour détecter les tendances produits avant la concurrence
- Impact : Accélération de la R&D et personnalisation accrue de l’expérience client grâce à une data unifiée et gouvernée
(7) Carrefour : L’IA au service du « Digital Retail » : Dans le cadre de sa stratégie 2026, Carrefour a massivement investi dans la data pour transformer son modèle opérationnel et l’expérience client.
- Cas d’usage : Déploiement de Hopla, un chatbot basé sur l’IA générative pour aider les clients à faire leurs courses (budget, idées recettes), et utilisation de l’IA pour l’optimisation des assortiments et la gestion des prix (réduction de 95% des erreurs d’étiquetage)
- Impact : L’enseigne vise 600 millions d’euros de création de valeur additionnelle grâce au digital et à la data d’ici 2026
(8) TotalEnergies : La Digital Factory comme moteur de valeur L’énergéticien s’appuie sur sa « Digital Factory » pour accélérer sa transition énergétique et optimiser ses opérations industrielles
- Cas d’usage : Déploiement de Copilot pour les collaborateurs et utilisation du supercalculateur Pangea (l’un des plus puissants au monde) pour optimiser l’imagerie sismique et le pilotage des actifs renouvelables en temps réel
- Impact : L’entreprise vise une génération de valeur de 1,5 milliard de dollars par an grâce au digital dès 2025
(9) Sanofi : L’IA « at scale » de la recherche à la production : Sanofi a intégré l’IA dans toute sa chaîne de valeur pour devenir le premier groupe pharmaceutique propulsé par l’IA à grande échelle
- Cas d’usage : Utilisation de modèles prédictifs pour accélérer la découverte de nouveaux médicaments (réduisant des processus de plusieurs semaines à quelques heures) et optimisation des chaînes de production via des jumeaux numériques
Impact : Réduction significative du time-to-market pour les nouveaux traitements et amélioration de la prise de décision clinique
En conclusion, la volonté pour les entreprises d’investir dans l’IA générative doit agir comme un puissant catalyseur de la modernisation des systèmes d’information. Pour exploiter à son plein potentiel les promesses des technologies, les entreprises n’ont d’autre choix que de repenser leurs infrastructures et leur gouvernance des données. Il s’agit d’un investissement lourd en technologie, en organisation et en conduite du changement, mais indispensable pour inscrire l’IA au cœur de la création de valeur.

Vous venez de lire les défis,
Voici comment les surmonter.
Notre guide expert décrypte les leviers concrets pour industrialiser vos projets IA.
Accompagnement du Groupe Meritis pour vos projets IA générative
Vous aussi, vous rencontrez probablement certaines des problématiques évoquées dans cet article. Pour tirer le meilleur parti des technologies d’IA générative, le groupe Meritis vous accompagne à chaque étape de votre transformation :
- Évaluation et audit de votre maturité data et IA actuelle
- Définition d’une feuille de route pragmatique adaptée à vos enjeux métiers
- Mise en œuvre opérationnelle avec nos experts pour garantir des résultats concrets
N’hésitez pas à nous contacter pour échanger autour de vos problématiques.
FAQ sur l’IA générative
Il n’existe pas une « meilleure » IA générative universelle, mais plutôt celle qui s’intègre naturellement à l’environnement numérique existant de l’entreprise. En 2026, les leaders que sont OpenAI, Google, Microsoft, Anthropic, Mistral offrent des outils d’IA aux capacités différenciées. Pour les petites entreprises, l’enjeu est de sélectionner une solution adaptée à leurs besoins spécifiques plutôt que de rechercher la plus performante techniquement. Le potentiel de l’IA réside dans son adéquation avec votre contexte d’utilisation.
L’IA générative est classée en plusieurs catégories en fonction des modalités qu’elle traite. Les modèles textuels (LLM) tels que GPT-5 ou Mistral produisent du contenu écrit, du code et des analyses. Les modèles visuels sont en train de concevoir des images (Midjourney, DALL-E) ou des vidéos. La voix et la musique sont produites par les modèles audio, tandis que les multimodaux combinent plusieurs types de données. L’IA générative est maintenant utilisée dans tous les domaines : assistants de code, agents conversationnels, outils de synthèse documentaire, créateurs de contenu marketing et assistants métier spécialisés. Chaque forme d’IA a un potentiel particulier en fonction des besoins spécifiques de l’entreprise, allant de l’optimisation des processus à la création de nouvelles offres.
Sources :
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.

- McKinsey : The state of AI (mars 2025) https://www.mckinsey.com/~/media/mckinsey/business%20functions/quantumblack/our%20insights/the%20state%20of%20ai/2025/the-state-of-ai-how-organizations-are-rewiring-to-capture-value_final.pdf
- Deloitte : State of generative AI (janvier 2025)
https://www.deloitte.com/az/en/issues/generative-ai/state-of-generative-ai-in-enterprise.html - Accenture : “Une nouvelle ère de l’IA apportera une autonomie sans précédent aux entreprises” (janvier 2025) https://newsroom.accenture.fr/fr/news/2025/accenture-technology-vision-2025-une-nouvelle-ere-de-l-ia-apportera-une-autonomie-sans-precedent-aux-entreprises
- MIT: The GenAI Divide: State of AI in Business 2025 (juillet 2025)
https://www.artificialintelligence-news.com/wp-content/uploads/2025/08/ai_report_2025.pdf - Forbes Insights AI (2025)
https://www.forbes.com/insights-intelai/ai-issue-1/ - L’Oréal : Rapports annuels 2024/2025 et articles sur la stratégie « Beauty Tech »
- Carrefour : Communications sur le plan « Carrefour 2026 », le lancement du chatbot Hopla et les résultats opérationnels présentés lors des salons Tech for Retail
- TotalEnergies : Communication de la Digital Factory et objectifs chiffrés de création de valeur (1.5 Md$/an) annoncés pour 2025
- Sanofi : Annonces lors de VivaTech 2024/2025 sur l’ambition « All-in on AI » et l’accélération de la R&D


Pas encore de commentaires