
Un déploiement Ansible se base sur des modules développés en python. Ces modules vont vous permettre de réaliser des actions sur les machines managées…
Créée par Michael DeHaan (auteur de la solution de provisionnement Cobbler) puis rachetée par RedHat en octobre 2015, Ansible est une plateforme logicielle dédiée au déploiement. Très en vogue aujourd’hui dans le monde de l’infrastructure informatique, elle est fortement utilisée par les populations SysOps pour la gestion de parcs informatiques traditionnels. Toutefois, elle s’ouvre de plus en plus vers le modèle Cloud et les intervenants DevOps dans des optiques d’Infrastructure As Code. On vous explique tout sur le déploiement Ansible dans cet article.
Introduction au déploiement Ansible
Un déploiement Ansible permet aujourd’hui la configuration massive de machines, l’installation d’applications, les configurations logicielles et bien d’autres cas d’usage. En conséquence, cette solution vous permet de gérer un parc de machines fraîchement installées comme un parc déjà existant.
Côté concurrence, nous pouvons citer Puppet, Terraform ou encore XLDeploy.
Techniquement, Ansible se base sur les langages ou protocoles suivants :
- La plate-forme est développée en Python
- Le format JSON est utilisé pour les flux de communication tandis que YAML est utilisé pour la partie déclarative
- Le protocole SSH est enfin utilisé pour la communication avec les machines-cibles
À l’identique de Puppet ou Terraform, Ansible se base sur un langage déclaratif : celui-ci va définir des règles plutôt que des procédures, décrire le “quoi” plutôt que le “comment”. Cette caractéristique permet ainsi d’être dissocié du contexte dans lequel le déploiement est réalisé (et nous amener alors vers l’idempotence, que nous détaillerons plus loin).
Par défaut, Ansible ne propose pas d’interface graphique et il faut se tourner vers Ansible Tower / AWX pour bénéficier d’une interface centralisée et visuelle.
Quels sont les prérequis pour utiliser Ansible ?
L’un des principaux avantages d’Ansible est qu’aucun agent n’est nécessaire sur les machines-cibles (se dit d’un fonctionnement agentless).
Dans la pratique, vous devez simplement installer Ansible sur une machine centrale (appelée aussi Control Node). C’est à partir de celle-ci que vous pourrez ensuite interagir avec les machines-cibles (appelées Managed Nodes).
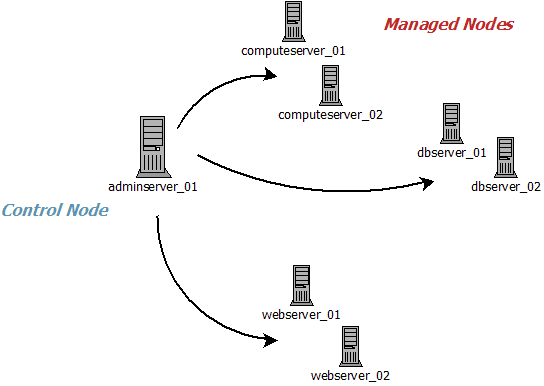
Il est souvent préférable que cette machine centrale soit « proche », d’un point de vue topologie réseau, des machines-cibles. L’un des principaux avantages est qu’Ansible ne nécessite que la présence de Python (2.6 minimum) sur la machine centrale et les machines-cibles.
Une grande simplicité
Dans la pratique, l’installation est très simple, le package étant disponible sur la plupart des OS UNIX. Comme mentionné précédemment, le protocole SSH est le plus usité en termes de protocole de communication Ansible (même si d’autres protocoles peuvent être utilisés) : il convient simplement de déployer la clé publique du compte Ansible sur l’intégralité du parc managé pour que la plate-forme soit opérationnelle.
Un dernier prérequis essentiel est d’autoriser le compte technique utilisé par Ansible à pouvoir utiliser la commande sudo (de la même façon que le déploiement de la clé publique, c’est une action généralement jouée par les équipes d’infrastructure en amont). À la clé : permettre au compte Ansible d’exécuter des commandes “en tant” qu’autre compte, souvent en tant qu’utilisateur “root” pour des actions nécessitant des droits à forts privilèges.
Ansible, dans le détail
Un déploiement Ansible se base sur des modules développés en python. Ces modules vont vous permettre de réaliser des actions sur les machines managées.
Par exemple, le module file vous permet de gérer des fichiers et leurs permissions : https://docs.ansible.com/ansible/2.4/file_module.html .
Le module shell permet quant à lui d’exécuter des commandes sur les Managed Nodes : https://docs.ansible.com/ansible/2.4/shell_module.html .
Enfin, le module pip permet l’installation de librairies Python : https://docs.ansible.com/ansible/2.4/pip_module.html .
Voilà ce qui fait la force de cet outil : le nombre important et surtout très varié de modules disponibles (https://docs.ansible.com/ansible/2.8/modules/list_of_all_modules.html). Ansible peut s’interfacer avec un écosystème Cloud (public ou privé), une base de données Postgresql, une queue RabbitMQ ou même encore une plate-forme Kubernetes.
Nous verrons également dans un prochain article qu’il est possible de développer son propre module Python.
Côté déploiement
Du point de vue du déploiement, comme évoqué précédemment, les actions sont exécutées sur des machines distantes dites « managées ». Afin de faciliter la gestion de ces machines (sur des parcs de grande taille ou variés), Ansible met à disposition de l’utilisateur un système d’inventaires.
Ces inventaires permettent de classifier votre parc et de pouvoir interagir avec vos machines de façon structurée. Ci-dessous, un exemple de fichier d’inventaire basé sur l’architecture illustrée plus-haut :
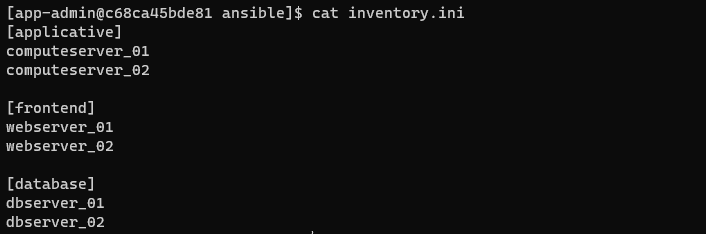
Le fichier d’inventaire peut être en format INI (comme ci-dessus) ou sous d’autres formats tels que YAML. Dans cet article, nous partons du principe que notre architecture est “figée” (nos noms de serveurs sont connus et statiques). Néanmoins, il est également possible d’interagir avec des infrastructures de type Cloud en utilisant des inventaires ”dynamiques”.
Comment lancer des actions
Pour terminer, il existe deux façons de lancer des actions via Ansible :
- Lancer une commande ad-hoc
- Exécuter un jeu d’instructions, appelé communément playbook
Nous traiterons en particulier de ce dernier, aujourd’hui le plus employé car il permet des constructions complexes de jeux d’action.
En résumé, lors d’un déploiement Ansible, l’utilisateur appelle des jeux d’actions (playbooks) afin d’exécuter des modules sur un inventaire de machines-cibles.
Ansible, par l’exemple
Pour cet exemple, l’architecture-cible sera celle illustrée plus haut :
- 2 serveurs applicatifs “compute”
- 2 frontaux “web”
- 2 bases de données “database”
À noter que le nombre de serveurs importe peu et que le jeu d’actions ainsi que le résultat seraient les mêmes sur une architecture plus grande.
Nous partons du principe que l’infrastructure est opérationnelle :
- Ansible est installé sur notre serveur central (Control Node)
- La clé publique du compte Ansible est déployée sur les machines-cibles
- Le compte est autorisé à utiliser la commande sudo sur ces machines
- Les machines-cibles sont référencées dans un fichier d’inventaire
Afin de valider le bon fonctionnement de notre architecture, nous pouvons au préalable lancer une commande simple sur une partie de notre inventaire.
Lancement de commandes ad-hoc
Comme mentionné précédemment, Ansible permet le lancement de commandes ad-hoc. Nous allons donc lancer la commande suivante afin de valider que nos machines-cibles sont disponibles et accessibles :

Analysons cette ligne de commande :
$ ansible frontend –m ping –i inventory.ini
- ansible est la commande permettant d’appeler des actions ou playbooks
- frontend est la section de notre inventaire (défini précédemment) permettant de lancer cette action sur les serveurs webserver_xx
- L’option -m indique à la commande ansible d’utiliser un module. Ici, nous appelons le module ping
- L’option -i permet d’indiquer le chemin vers notre fichier d’inventaire
Le résultat de cette commande est le suivant :
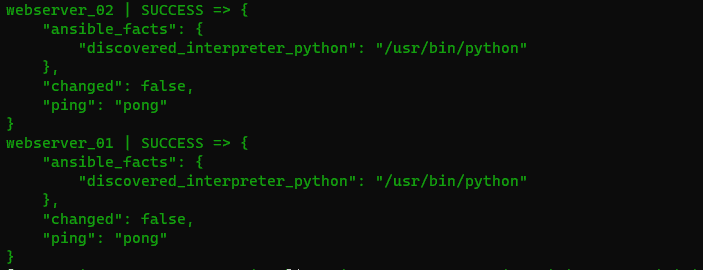
Comme l’indique le retour (par sa couleur mais également le statut SUCCESS), la commande s’est correctement terminée.
Pour l’exemple, voici le retour de la même commande dans le cas où les machines-cibles sont inaccessibles d’un point de vue réseau :
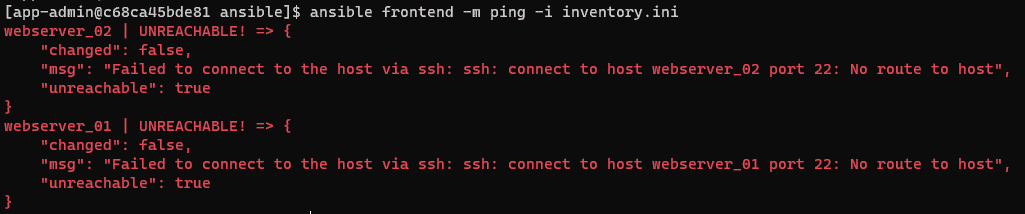
Comme vous pouvez le constater, le résultat est affiché en rouge (le résultat de la commande sera toujours coloré selon son statut) et la valeur du champ unreachable (renvoyée par le module ping) sera true, ce qui indique que la machine est inaccessible.
Attention, ce module n’effectue pas une simple requête ICMP entre le Control Node et vos machines-cibles comme le fait la commande universelle système ping. Ce module, comme indiqué dans sa page d’aide, va bien tester l’accès à distance de notre compte Ansible à partir du Control Node vers les Managed Nodes mentionnés (i.e. connexion SSH entre la machine centrale et les machines managées + vérification présence Python sur machine-cible).
Le playbook
Notre infrastructure étant opérationnelle, nous pouvons désormais imaginer lancer des actions plus poussées. Le lancement de commandes simples, comme précédemment, peut être très vite limité dans le cadre de déploiements plus complexes. Nous allons donc utiliser maintenant un playbook, qui est un enchaînement d’actions.
Partons du principe que nous souhaitons créer un compte utilisateur sur un ensemble précis de machines.
Voici le playbook qui permettra de réaliser cette action :
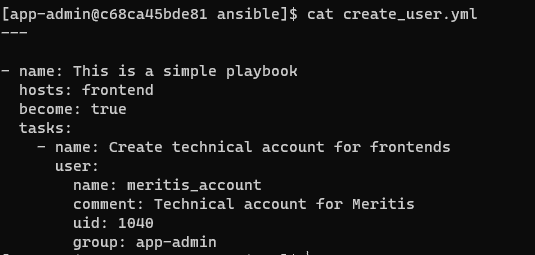
Comme mentionné précédemment, le format utilisé est le format YAML. L’indentation est ici très importante et Ansible vous notifiera très rapidement (à l’exécution de votre playbook) si son format n’est pas correct.
Ce playbook est simple et choisi comme exemple pour facilement l’analyser. Le playbook va alors appeler une tâche sur les serveurs appartenant à la section frontend de notre inventaire. Cette tâche appellera quant à elle le module user.
La structure du playbook
Décortiquons un peu le playbook ainsi que sa structure :
— -> indique le début du document
– name: This is a simple playbook –> nom de ce jeu d’actions
hosts: frontend -> indique la section de machines-cibles de notre inventaire
become: true -> paramètre indiquant que l’action nécessite une élévation de privilèges
tasks: -> indique une section de tâches à executer
– name: Create technical account for frontends -> nom de la tâche
user: -> nom du module utilisé
name: meritis_account -> paramètre du module (ici nom du compte à créer)
comment: Technical account for Meritis -> paramètre du module (ici commentaire lié au compte créé)
uid: 1040 -> paramètre du module (User Id du compte créé)
group: app-admin -> paramètre du module (Groupe d’appartenance du compte créé)
- Plus d’informations à propos de la création de playbooks ici.
Nous allons ensuite exécuter le playbook. Si nous comparons avec le lancement d’actions simples, comme effectuées précédemment, seule la commande appelée change :
$ ansible-playbook create_user.yml -i inventory.ini
Vous remarquerez que nous ne précisons plus les hosts cibles sur la ligne de commande car ils sont mentionnés dans le playbook (hosts: frontend).
Voici le résultat :
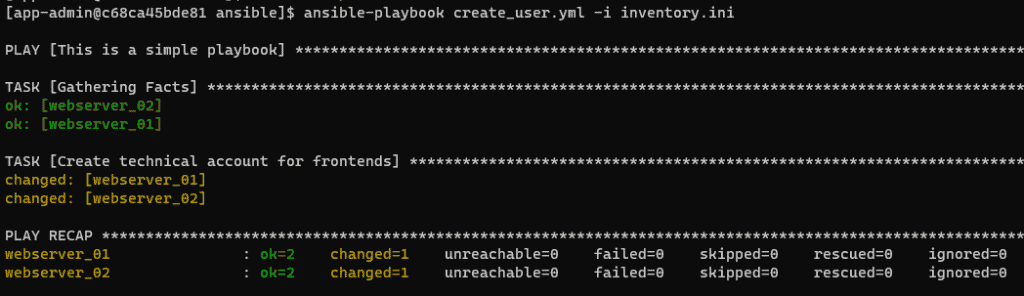
Comme vous pouvez le voir, rien n’indique explicitement que le compte existe désormais. Seul un changement d’attribut (changed) indique qu’un paramètre a été changé.
Déploiement idempotent
Lançons une seconde itération, pour l’exemple :
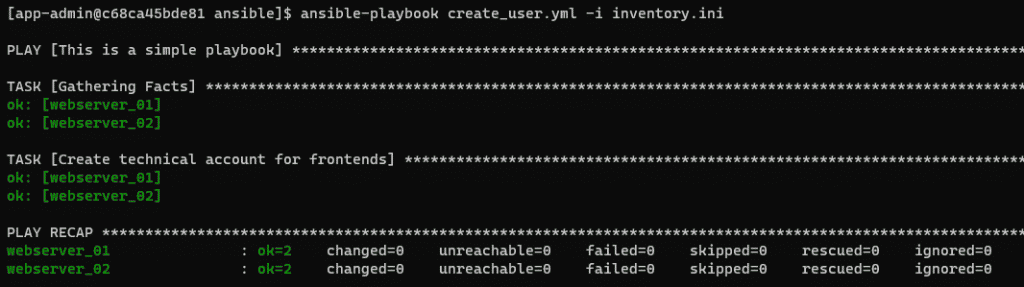
Vous pouvez observer que l’attribut est désormais ok et non plus changed.
Ce comportement est un point très important : un déploiement Ansible est idempotent au niveau de ces actions. Qu’est-ce que cela signifie ? Qu’une action exécutée une fois peut l’être ensuite de façon répétée et aura toujours le même résultat.
Dans notre cas, le compte a été créé sur les machines-cibles une première fois. Si nous rejouons le même playbook, Ansible ne créera pas à nouveau le compte et ce, à chaque fois que nous rejouerons cette action.
Cette spécificité d’Ansible est très importante. Elle permet de garantir que la configuration souhaitée sera toujours la même et qu’il n’y a pas de risques à la réappliquer.
Attention néanmoins à la construction de vos playbooks (et des modules utilisés) et assurez-vous du contexte dans lequel ils sont joués. Dans le cadre d’une migration d’infrastructure, il peut être nécessaire d’appeler des commandes unitaires (via le module shell) en post-installation pour appliquer des correctifs ou des modifications ne devant être joués que dans le cadre d’un déplacement de données par exemple.
Le playbook utilisé pourra donc être rejoué quel que soit le contexte mais il faudra alors apposer des conditions sur les tâches de post-installation qui risqueraient d’avoir un impact sur une infrastructure déjà migrée.
Regardons désormais si le compte est disponible sur une des machines-cibles :

Le compte existe bien et possède bien les attributs demandés.
Le playbook ci-dessus ne réalise qu’une action mais il est désormais possible de chaîner d’autres tâches, pouvant appeler d’autres modules. Il est également possible de jouer d’autres actions sur des hosts différents, présents dans votre inventaire. Les possibilités sont variées et infinies.
Vous trouverez ci-dessous des exemples de playbooks plus fournis qui vous donneront une idée de ce qui est possible d’automatiser et de déployer :
Conclusion
À travers cet article, nous avons pu découvrir le déploiement Ansible :
- Son rôle et ses cas d’usage
- Les prérequis nécessaires pour le fonctionnement de la plateforme
- Son mode de fonctionnement à travers ses appels, ses inventaires, ses playbooks
- Un exemple simple de playbook
Bien évidemment, cet outil est complexe et nous avons survolé son mode de fonctionnement simple. Nous découvrirons dans un prochain article l’usage de rôles Ansible, la création d’un module personnalisé ainsi que la notion de variables et de templates.
Références
Si vous souhaitez aller plus loin et découvrir la mise en place de pipelines CI/CD pour votre projet applicatif, vous trouverez toutes les informations nécessaires dans cet article : https://meritis.fr/meme-le-plus-petit-projet-merite-davoir-son-pipeline-ci-cd-partie-2/
Pour plus d’informations sur les nouveaux rôles et acteurs DevOps : https://meritis.fr/devops-avez-dit-devops/

Vos commentaires
Merci, Mathieu !
J’utilise déjà Ansible, mais j’ai tout de même trouvé cet article intéressant. J’attends avec hâte le prochain sur la création de modules custom ?
Très bon Article bien construit.
Pour un novice comme moi cela donne envie de sauter le pas!
Merci Mathieu.
#HiddenTalent
Très bon article clair et concis.
Merci Mathieu !
Super article 🙂 Merci !
Très intéressant en tout cas