
Quand vous créez un Pipeline à l’aide de Spark ML, il est composé d’une multitude de stages natives au framework Spark, comme Tokenizer, OneHotEncoder, StringIndexer. Pourtant vous aimeriez pouvoir y inclure d’autres stages, développées par vous même. Dans cet article nous prendrons l’exemple d’un transformer très simple, permettant de récupérer en entrée une chaîne de caractère et d’en sortir la chaîne de caractère inverse. Nous verrons ainsi toutes les étapes permettant d’inclure ce transformer dans un Pipeline.
En préambule, rappelons qu’il existe deux concepts bien distincts : transformer et estimator. Pour faire simple, un transformer prend en entrée un DataFrame et en ressort un autre DataFrame tandis qu’un estimator a pour but de créer un transformer en fonction d’un DataFrame passé en entrée.
L’implémentation du ReverseTransformer
Commençons l’implémentation de notre ReverseTransformer, en héritant de la classe transformer de PySpark. L’implémentation se trouvera dans un fichier reverse.py.
from pyspark import keyword_only
from pyspark.ml import Transformer
from pyspark.ml.param.shared import HasInputCol, HasOutputCol
from pyspark.sql.functions import udf
class ReverseTransformer(Transformer, HasInputCol, HasOutputCol):
@keyword_only
def __init__(self, inputCol=None, outputCol=None):
super(ReverseTransformer, self).__init__()
kwargs = self._input_kwargs
self.setParams(**kwargs)
@keyword_only
def setParams(self, inputCol=None, outputCol=None):
kwargs = self._input_kwargs
return self._set(**kwargs)
def _transform(self, dataset):
reverse = udf(lambda sentence: sentence[::-1])(dataset[self.getInputCol()])
return dataset.withColumn(self.getOutputCol(), reverse)
Ici, rien de bien compliqué. Nous avons créé un transformer possédant un attribut inputColumn (représentant la colonne du DataFrame sur laquelle le traitement va s’exécuter) et un attribut outputColumn (représentant la colonne de sortie du résultat du traitement).
Créons désormais un fichier script.py permettant de tester cette stage dans un Pipeline.
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from reverse import ReverseTransformer
session = SparkSession.builder.master("local[*]").getOrCreate()
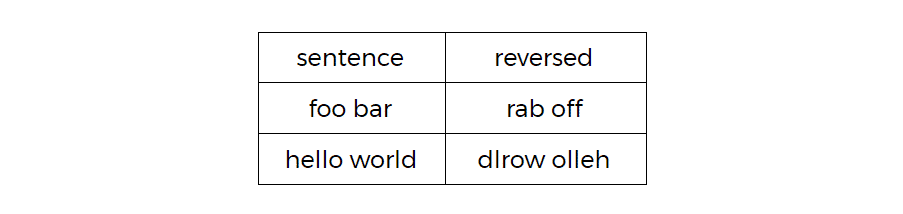
df = session.createDataFrame([("foo bar",),("hello world",)]).toDF("sentence")
reverse = ReverseTransformer(inputCol="sentence", outputCol="reversed")
pipeline = Pipeline(stages=[reverse])
model = pipeline.fit(df)
model.transform(df).show()
Lançons maintenant le script avec la commande suivante : spark-submit –py-files reverse.py script.py
Le résultat affiché devrait être :
Et voilà ! Vous savez désormais comment implémenter un transformer custom ! À partir de la version 2.0.0 de PySpark, il est possible de sauvegarder un Pipeline qui a été fit. En effet, l’un des intérêts principaux de l’API Pipeline réside dans la possibilité d’entraîner un modèle une fois, de le sauvegarder, puis de le réutiliser à l’infini en le chargeant simplement en mémoire.
Si vous utilisez une version 2.0.0+ de PySpark, essayons de sauvegarder notre Pipeline contenant notre ReverseTransformer. Il suffit pour cela de rajouter cette ligne à la fin de script.py.
model.save("file:///tmp/spark_model")
Relançons maintenant la même commande : spark-submit –py-files reverse.py script.py
Le résultat devrait être le suivant :
AttributeError: ‘ReverseTransformer’ object has no attribute ‘_to_java’
“Ouch”. Impossible de sauvegarder un Pipeline avec des stages custom. SPOIL, le chargement d’un Pipeline avec des stages custom ne fonctionne pas non plus. Pour ceux n’ayant pas besoin de sauvegarder/charger leur Pipeline, vous pouvez dès à présent arrêter de lire cet article. Il vous suffira d’hériter des classes transformer et estimator selon votre besoin et cela s’arrêtera là. Pour les autres, le fun commence maintenant.
Comment ça se fait que les autres ils fonctionnent ?
Nous avons vu que notre ReverseTransformer ne permettait pas à notre PipelineModel d’être sauvegardé sur disque. Dès lors, pourquoi cela fonctionne-t-il avec n’importe quel autre stage native de Spark ?
Prenons l’exemple d’un transformer simple, Tokenizer et regardons comment il est implémenté. Si l’on compare l’implémentation Scala et l’implémentation Python, on pourrait s’attendre à trouver un code sensiblement similaire (quoique syntaxiquement différent), or il n’en est rien. En effet, voici le code Python (sans les commentaires) relatif au Tokenizer :
class Tokenizer(JavaTransformer, HasInputCol, HasOutputCol, JavaMLReadable, JavaMLWritable):
@keyword_only
def __init__(self, inputCol=None, outputCol=None):
super(Tokenizer, self).__init__()
self._java_obj = self._new_java_obj("org.apache.spark.ml.feature.Tokenizer", self.uid)
kwargs = self._input_kwargs
self.setParams(**kwargs)
@keyword_only
@since("1.3.0")
def setParams(self, inputCol=None, outputCol=None):
kwargs = self._input_kwargs
return self._set(**kwargs)
Plusieurs choses intéressantes sont à relever dans ces quelques lignes :
- La méthode transform() censée décrire la transformation à effectuer n’existe pas
- Tokenizer n’hérite pas de Transformer mais de JavaTransformer
- Le code du constructeur semble faire référence à la classe Tokenizer développée en Scala
Il suffit de regarder la classe JavaTransformer pour que tout devienne plus clair.
class JavaTransformer(JavaParams, Transformer):
"""
Base class for :py:class:`Transformer`s that wrap Java/Scala
implementations. Subclasses should ensure they have the transformer Java object
available as _java_obj.
"""
__metaclass__ = ABCMeta
def _transform(self, dataset):
self._transfer_params_to_java()
return DataFrame(self._java_obj.transform(dataset._jdf), dataset.sql_ctx)
En effet, il semble que l’appel à la méthode transform() du Tokenizer PySpark fasse en réalité un appel vers la méthode transform() du Tokenizer Scala. On rappelle que le Tokenizer Scala est instancié dans le constructeur du Tokenizer PySpark :
self._java_obj = self._new_java_obj("org.apache.spark.ml.feature.Tokenizer", self.uid)
On en déduit donc que PySpark n’est pas réellement une implémentation de Spark en Python mais plutôt un wrapper Python autour de l’API Scala.
Je vois pas le rapport avec la choucroute
Pour le moment, certes, aucun rapport avec l’impossibilité de sauvegarder/charger des stages custom. Néanmoins nous sommes sur la bonne piste. Regardons désormais ce qu’il se passe lorsque l’on appelle la méthode save() de PipelineModel (similaire pour Pipeline)
# dans la classe PipelineModel
def save(self, path):
self.write().save(path)
def write(self):
return JavaMLWriter(self)
# dans la classe JavaMLWriter
def __init__(self, instance):
_java_obj = instance._to_java()
# dans la classe PipelineModel
def _to_java(self):
for idx, stage in enumerate(self.getStages()):
java_stages[idx] = stage._to_java()
Je n’ai gardé que les lignes nécessaires à la compréhension du problème dans chaque méthode. La ligne qui nous intéresse tout particulièrement ici est là dernière. On s’aperçoit qu’avant chaque sauvegarde d’un PipelineModel, la totalité de l’objet ainsi que ses stages sont convertis en instanciant l’objet Scala correspondant. La sauvegarde s’effectuera donc sur les objets Scala.
Ainsi, il devient logique que la sauvegarde, mais aussi le chargement, qui fait une opération similaire, d’un transformer custom ne soit pas possible car nous n’avons pas de __java_obj correspondant.
Ne reste plus alors qu’à suivre le modèle de Spark, en deux étapes : La première consiste en l’implémentation du ReverseTransformer en Scala ou Java. La seconde en l’implémentation du ReverseTransformer wrapper en Python.
J’ai trouvé une autre solution à ce problème dont le côté “hack” fait que le Pipeline sauvegardé ne pourra être utilisé qu’avec PySpark. Elle a le défaut d’apporter pas mal de complexité côté Python, aussi je ne la recommande pas particulièrement. Revenons donc à notre solution.
Interfacer Python et Scala
Le code du transformer Scala permettant d’inverser une chaîne de caractère est très simple, le voici :
package reverse
import org.apache.spark.ml.UnaryTransformer
import org.apache.spark.ml.util.{DefaultParamsReadable, DefaultParamsWritable, Identifiable}
import org.apache.spark.sql.types.StringType
class ReverseTransformer(override val uid: String) extends UnaryTransformer[String, String, ReverseTransformer]
with DefaultParamsWritable {
def this() = this(Identifiable.randomUID("rv"))
override protected def createTransformFunc = _.reverse
override def outputDataType = StringType
}
object ReverseTransformer extends DefaultParamsReadable[ReverseTransformer] {
override def load(path: String): ReverseTransformer = super.load(path)
}
Ici j’utilise UnaryTransformer car ma fonctionnalité est très simple à implémenter, cela évite donc beaucoup de boilerplate code. Le trait DefaultParamsWritable permet de fournir une implémentation par défaut de la sauvegarde de la stage tandis que DefaultParamsReadable permet de fournir une implémentation par défaut de la lecture de la stage.
Il ne nous reste désormais plus qu’à implémenter le wrapper Python. Il suffit pour cela d’imiter la classe Tokenizer que l’on peut trouver dans le fichier source pyspark.ml.feature.py.
from pyspark import keyword_only
from pyspark.ml.util import JavaMLReadable, JavaMLWritable
from pyspark.ml.wrapper import JavaTransformer
from pyspark.ml.param.shared import HasInputCol, HasOutputCol
class ReverseTransformer(JavaTransformer, HasInputCol, HasOutputCol, JavaMLReadable, JavaMLWritable):
@keyword_only
def __init__(self, inputCol=None, outputCol=None):
super(ReverseTransformer, self).__init__()
self._java_obj = self._new_java_obj("reverse.ReverseTransformer", self.uid)
kwargs = self._input_kwargs
self.setParams(**kwargs)
@keyword_only
def setParams(self, inputCol=None, outputCol=None):
kwargs = self._input_kwargs
return self._set(**kwargs)
Le decorator keyword_only sert à forcer l’utilisation des paramètres nommés. Il n’est pas obligatoire mais je préfère suivre l’implémentation des développeurs de PySpark qui eux l’utilisent et qui apporte plus de lisibilité.
ReverseTransformer("a", "b") #erreur
ReverseTransformer(inputCol="a", outputCol="b") #ok
Attention cependant, il faut absolument que le nom du fichier dans lequel se trouve votre classe Python soit le même que le nom du package contenant votre classe Scala. La raison est simple, au chargement d’un Pipeline, Spark va essayer de faire la correspondance entre votre classe Scala et votre classe Python en partant du postulat suivant :
[org.apache.spark].x.y.z.MaClass se trouve dans le fichier [pyspark].x.y.z.py
Par exemple, la classe org.apache.spark.ml.feature.Tokenizer se trouve dans le fichier pyspark.ml.feature.py.
La démo, sans l’effet démo
Afin de pouvoir faire appel à votre classe Scala dans votre code Python il est tout d’abord nécessaire de la packager. Pour cela vous allez devoir créer un fat JAR qui contiendra votre classe et toutes ses dépendances par le biais du plugin assembly (si vous utilisez sbt) ou alors les plugins assembly ou shade (si vous utilisez maven).
Une fois le fat JAR assemblé, il va falloir le rendre accessible dans le classpath de Spark. Pour ce faire, nous avons plusieurs solutions :
La solution “one shot” qui utilise l’option –jars au lancement du script afin que le jar soit chargé au classpath. C’est celle que j’utiliserai plus tard dans l’article.
La solution “durable” consistant à fournir les paramètres spark.driver.extraClassPath et/ou spark.executor.extraClassPath dans le fichier de configuration de Spark (qui se trouve au niveau de $SPARK_HOME/conf/spark-defaults.conf). Cette solution est à privilégier si vous vous servez régulièrement de certains jars, cela vous évitera de devoir les spécifier à chaque fois (et qu’ils soient envoyés à vos worker à chaque lancement du job).
Pour ma part j’ai assemblé le ReverseTransformer Scala dans un jar custom.jar et j’ai implémenté le ReverseTransformer Python dans un fichier “reverse.py”.
Enfin, j’ai repris le fichier script.py pour y ajouter quelques lignes afin de tester la sauvegarde et le chargement. Voici le fichier final :
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline, PipelineModel
from reverse import ReverseTransformer
spark = SparkSession.builder.master("local[*]").getOrCreate()
df = spark.createDataFrame([("foo bar",),("hello world",)]).toDF("sentences")
reverse = ReverseTransformer(inputCol="sentences",outputCol="reversed")
pipeline = Pipeline(stages=[reverse])
model = pipeline.fit(df)
model.save("file:///tmp/spark_model")
loaded = PipelineModel.load("file:///tmp/spark_model")
loaded.transform(df).show()
On relance une dernière fois le script, attention, la commande à changé :
spark-submit –jars custom.jar –py-files reverse.py script.py
Le résultat affiché devrait être :

Et voilà ! Vous savez désormais comment implémenter un transformer custom, et comment faire pour qu’ils puissent être sauvegardés et chargés dans un Pipeline !

Vos commentaires
Bonjour, hello, I will continue in english 🙂
Great article ! I stumbled upon this issue with what I’m trying to do.
So, my issue is that I have to be able to serialize (store as a stage within a model pipeline, save, load and transform) some steps for data cleaning that are not serializeable otherwise using PySpark.
If I correctly understood from your article this is possible only if the function is written in Scala (Spark) and then call it from PySpark and be able to and save, load and transform.
I am wondering if it’s a way to make it all from PySpark even though I need the model pipeline to be ran from Scala afterwards.
Your answer will be much appreciated.
Regards,
Raluca
Hello Raluca,
I’m glad you enjoyed the article !
I fear that I’m not quite understanding what you’re asking here.
If you’re using PySpark and the Pipeline API and you want to be able to save and load a pipeline, you have two cases :
– either your Pipeline is only composed of spark native stages
– or your Pipeline contains at least one custome stage
If you have a custom stage, the only way to make your Pipeline loadable / saveable is to do as shown in the article (e.g code it in scala and create a corresponding wrapper in pyspark)
If you don’t, then you can directly save it / load it.
In any case, once your Pipeline is saved you can load it using scala or python, as you wish.
I hope it answered your question, otherwise I’ll be glad to help you !
Hello Clement,
Yes my issue is that I have a couple of custom transformers. I was not sure if new version of Spark 2.3.0 is able to solve this without Scala. https://issues.apache.org/jira/browse/SPARK-17025 .
Regards,
Raluca
Ah, at last they made it !
I looked up the code in Github and found that Scala can load Pipelines composed of Scala stages whereas PySpark can load Pipelines composed of Scala AND Python stages.
So it seems that you cannot load a custom Pipeline stage written in Python from Scala side.
See for yourself :
https://github.com/apache/spark/blob/master/python/pyspark/ml/pipeline.py (see load)
https://github.com/apache/spark/blob/master/mllib/src/main/scala/org/apache/spark/ml/util/ReadWrite.scala (see load)
Yes, they made it but not quite working for the issue « So it seems that you cannot load a custom Pipeline stage written in Python from Scala side. »
So, this draws me back to your solution that I suppose you’ve tested already.
What I have been able to do till now is to make a custom transformer, add the _to_java method, include it in a pipeline, running fit() then saving the pipeline model (after fit).
Then, after loading it it crashes at transform, or even when loading. Used different approaches from the internet.
I haven’t found a working example on the internet so I suppose you’re solution might work.
Regards,
Raluca
Are you sure you need to add the _to_java method ? I think I read somewhere that your custom stage shouldn’t inherit JavaTransformer (since you implement it python-side). Anyway, yes my solution works so I guess that’s a good workaround !
The _to_java is for saving purposes, otherwise I get an error when trying to save the model after fitting the pipeline.
Also in your article that the native transformers in PySpark like Tokenizer don’t have Transformer but JavaTransformer.
My custom transformer is of a Transformer type not estimator and just added the _to_java method but I haven’t tried with JavaTransformer.
See this: https://stackoverflow.com/questions/49311339/save-custom-transformers-in-pyspark and tried also this https://stackoverflow.com/questions/41399399/serialize-a-custom-transformer-using-python-to-be-used-within-a-pyspark-ml-pipel/44377489#44377489 .
Raluca
Hello Clément,
I’m trying to replicate and test your example and I have errors when trying to make Scala script for ReverseTransformer into the jar file custom.jar.
I’m using scalac custom.scala -d custom.jar in console.
How you bundled the file into the jar file?
Regards,
Raluca
Hello Clement,
Merci pour le partage.
J’ai essaye de modifier la methode _tranform dans le code python et j’arrive a avoir les resultats escomptes quand je run spark submit du code python spark-submit –jars custom.jar –py-files reverse.py script.py . Je souhaiterai save le pipeline depuis python et le loader dans mon code spark scala mais je me rend compte qu’il run toujours l’inverse initial certainement a cause de override protected def createTransformFunc = _.reverse dans la classe class ReverseTransformer(override val uid: String) extends UnaryTransformer[String, String, ReverseTransformer].
Avez-vous une idee de comment runner/implementer un transformer en python et le loader dans un code scala svp>
Merci
Hello !
Oui à l’étape de save/load le transformer python n’est qu’un « wrapper » permettant l’appel à la classe définie en Scala. La fonction est bien définie dans createTransformFunc comme tu l’as remarqué.
Si j’ai bien compris ta question et d’après mes connaissances il n’est pas possible d’écrire un transformer en python (c’est à dire l’implémenter entièrement en python) et le loader dans un code Scala.
D’après ce que je sais il est désormais possible de tout faire en python depuis les dernières version de Spark, c’est à dire implémenter des stages custom en python et les save/load dans un code python. Par contre si tu souhaites lancer Spark Scala il te faut un code Scala.
En bref, ce qu’il est possible de faire :
Transformer implémenté en scala -> possibilité de le run en Scala ou en Python (avec la technique du wrapper comme montré dans l’article)
Transformer implémenté en python -> run uniquement en python
En espérant t’avoir aidé !