
Une nouvelle visite dans le jardin des données en bonne compagnie, ça vous dit ? Il y a deux semaines, nous découvrions Splunk, il est désormais temps de comprendre comment cela fonctionne. Yacine vous en dit plus dans ce nouvel article. Foncez et Splunk n’aura plus aucun secret pour vous !
Le fonctionnement de Splunk
Les entrées du logiciel
Splunk permet de charger des événements (par exemple des ventes) dans son moteur d’indexation :
- Soit en prenant un fichier plat en entrée (fichier Micrsosoft Excel, CSV, OpenDocument…)
- Soit en le connectant à une base de données via un connecteur
- Soit en récupérant les données entrantes sur la connexion (via TCP/IP par exemple) pour en extraire des événements à ajouter au moteur
Il existe tout un magasin d’applications intégrées dans le logiciel pour assurer l’ensemble des connexions possibles avec les solutions du marché. Une large communauté s’est alors formée pour compléter en permanence ce magasin d’applications.
L’analyse de données
Splunk analyse les données, en particulier le timestamp associé à chaque événement, pour ensuite les indexer dans son moteur, le Splunk Indexer.
Le reporting
Le reporting permet de présenter sous forme de rapports les données d’entreprise, par exemple l’évolution des ventes, de manière générale ou selon un angle particulier, afin d’aider à la décision pour la stratégie de l’entreprise.
Grâce à un langage spécifique, le SPL, ou Search Processing Language (voir la section 2.4), il est possible, dans une barre de recherche, d’analyser les données de manière multidimensionnelle pour obtenir facilement et rapidement des tableaux ou des graphes (le moteur d’indexation optimise particulièrement les traitements).
Il est ainsi possible de créer des tableaux de bord qui enregistrent des recherches et permettent de monitorer en direct les résultats.
Remarque :
Splunk n’est pas un logiciel d’ETL. Il ne permet donc pas de faire tout ce qui concerne les jointures. Il est donc suggéré de faire passer en priorité les données par un middleware comme Pentaho (partenaire de Splunk) qui se charge de faire ces jointures, avant de les analyser dans Splunk.
De plus, les données doivent être nettoyées au préalable.
L’exemple des ventes en ligne :
Il pourrait être possible de visualiser en temps réel quels produits sont les plus commandés sur une boutique en ligne et de détecter la hausse des ventes d’un produit en particulier à un moment donné. La marque pourrait alors réagir commercialement ou vérifier l’état des stocks. C’est une vision à court-terme, en live.
Il est également possible de voir quels sont les produits ou les marques qui ont le mieux fonctionné sur l’année écoulée, afin de connaître les habitudes de consommation. On obtient alors une vision à long terme afin d’évaluer les stratégies que peut adopter la direction marketing.
Le Search Processing Language
Le Search Processing Language (SPL) est un langage développé par Splunk qui peut faire penser au SQL par ses possibilités, mais dont la syntaxe est totalement différente. Il permet de tirer le meilleur parti des fonctions proposées par Splunk et de profiter pleinement de la puissance du moteur d’indexation.
Exemple :
La requête ci-dessous permet de réaliser un graphe du nombre de ventes selon les données listées dans lightsaber.csv en fonction du jour de la semaine et du genre du client.
source="listeventes.csv"|chart count by date_wday, CLIENT_GENDER
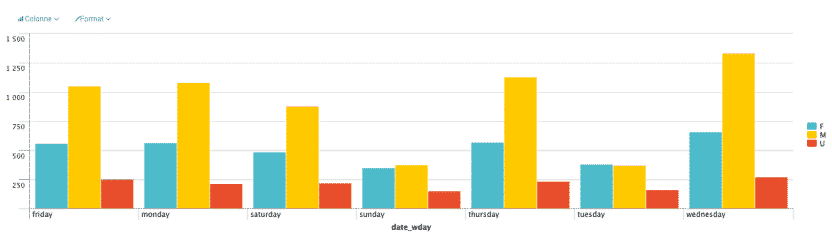
Comme on le voit, les requêtes SPL se rapprochent beaucoup de l’étude des besoins qui est faite au début d’un projet décisionnel.
Ainsi, n’importe quel utilisateur, plus ou moins avancé, et auquel on fournit le bon jeu de données peut s’amuser à effectuer des recherches très simplement.
Syntaxe
Toute requête SPL commence par la source, c’est-à-dire l’ensemble des événements étudiés, suivi d’un pipe ou barre verticale : « | ». La commande qui suit le pipe prend comme paramètre le résultat de la commande qui précède le pipe.
Le glossaire du SPL
- Chart : pour obtenir un graphe
- Timechart : pour obtenir un graphe en fonction du temps
- Top : pour obtenir les premiers résultats
- Count : pour désigner le nombre d’événements, de la même façon que le fait COUNT(*) en SQL
- By : pour comparer une donnée par rapport à une autre
- Limit : ajouter l’option limit=20 à un mot clé, pour obtenir non plus les 10 premiers résultats mais les 20 premiers
- AS
- OVER
- WHERE
Par ailleurs, il est possible de créer des sous-requêtes dans les requêtes pour obtenir des traitements plus fins.
Le logiciel fournit des macros concernant le temps. Il n’est pas nécessaire d’implémenter en SQL la transformation des dates. Par exemple, on a à disposition :
- date_wday pour le jour de la semaine
- date_month pour le mois de l’année
- date_mday pour le jour du mois
Pour plus de détails sur SPL, vous pouvez consulter les liens ci-dessous :
https://docs.splunk.com/Documentation/Splunk/6.2.1/Search/Whatsinthismanual
https://docs.splunk.com/Documentation/Splunk/7.2.1/SearchReference/UnderstandingSPLsyntax
L’interface du logiciel Splunk
Quelles sont alors les interfaces Splunk ? Voici certaines d’entre elles présentées ci-dessous.
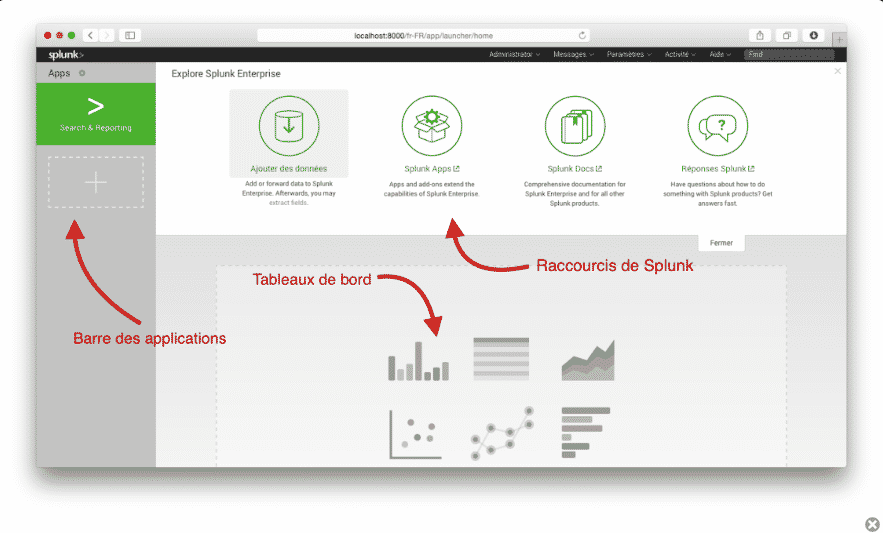
L’interface principale :
Elle donne accès aux applications installées dans la barre latérale gauche. Par défaut, la seule application installée est Search & Reporting. Les sources de données se situent dans la partie centrale haute et les rapports personnalisés (non encore ajoutés) dans la partie centrale inférieure.
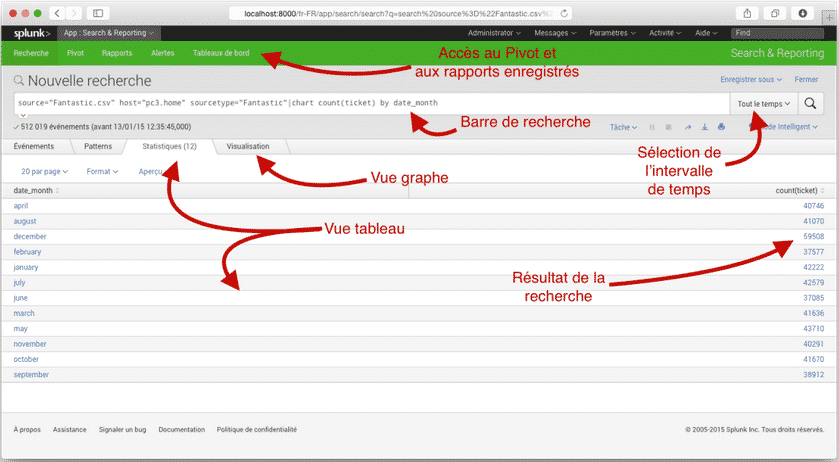
L’interface Search & Reporting :
L’interface Search & Reporting dispose d’un champ de recherche qui permet d’entrer une requête en langage SPL. À droite de ce champ de recherche, on peut préciser la période de temps que l’on veut étudier (en temps réel : la dernière heure ou en temps relatif : un mois précis de l’année dernière…).
La partie basse dispose de plusieurs onglets :
- Statistiques : affiche un tableau des résultats de la requête (sous forme paginée)
- Visualisation : affiche un graphe correspondant à ce tableau de résultats. Splunk propose de choisir le type de graphe créé, comme le fait un tableur même s’il en conseille certains selon ce qui doit être affiché
Par ailleurs, il est possible de :
- Créer des rapports pour pouvoir enregistrer les recherches et voir dynamiquement les évolutions dans les données. Chaque rapport contient une et une seule recherche enregistrée.
- Créer des tableaux de bord qui contiennent plusieurs rapports et ainsi obtenir une vue d’ensemble des données très rapidement.
L’application Search & Reporting peut aussi être gérée de manière plus visuelle que le champ de recherche en utilisant le Pivot. Celui-ci permet de directement choisir ce que l’on souhaite voir en abscisse et en ordonnée de sorte que l’on peut avoir très rapidement un petit aperçu des données, sans même connaître le SPL.
Avantages et inconvénients de Splunk
Les principaux avantages de Splunk :
- Tableaux de bord non statiques : les données peuvent être monitorées en temps réel.
- Possibilité d’adapter à la taille de l’infrastructure : on peut l’utiliser pour une petite structure qui crée assez peu de données, comme on peut le mettre en clusters ou en version cloud dans le cas d’importants volumes de données à intégrer.
- Simplicité des fonctions de base : n’importe quelle personne peut créer des rapports, sans avoir besoin d’être analyste de données. Les requêtes sont en langage courant et l’interface est très dépouillée.
- Grande évolutivité grâce à la communauté Splunk qui fournit de nombreux connecteurs et extensions.
- Puissance du moteur d’indexation.
Les principaux inconvénients de Splunk :
- Aucun dispositif d’ETL : il n’existe pas de moyen simple de corriger les données ou d’effectuer de jointures. Il faut donc avoir un intermédiaire qui fait ce travail pour fournir des événements en entrée.
- Nouveau langage à apprendre en parallèle de tous les autres.
- Prix au gigaoctet de données traitées.
L’architecture Splunk
Splunk est donc une plateforme logicielle qui permet de rechercher, d’analyser et de visualiser les données notamment dans un contexte de big data. Une solution qui offre de nombreux avantages notamment la capacité à visualiser l’activité en temps réel. Mais pour y parvenir, quelle mécanique se cache derrière Splunk ? Voici une présentation de la structure de la plateforme analytique spécialisée dans les données « machines ».
Structure de Splunk
Trois composantes principales forment Splunk :
- Un CLI
- Une interface Web super intuitive écrite en Python et Ajax
- Un daemon en C++ qui réalise la collection de données, l’indexation et la recherche. Ce daemon fournit des API accessibles en REST favorisant son intégration avec n’importe quel framework Web.
L’ensemble de ces composants s’appuient sur un « data store » distribué et propriétaire.
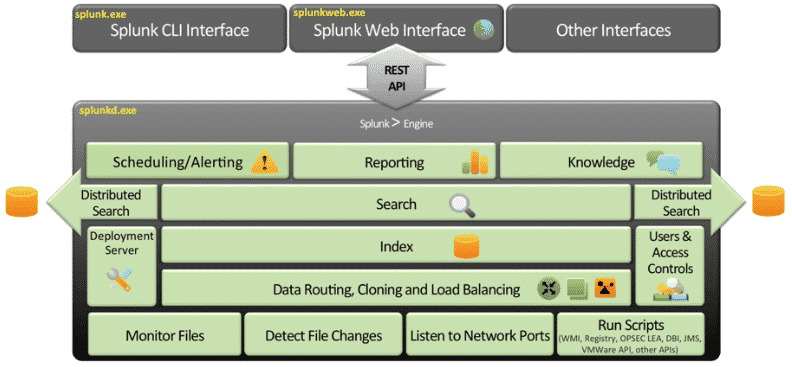
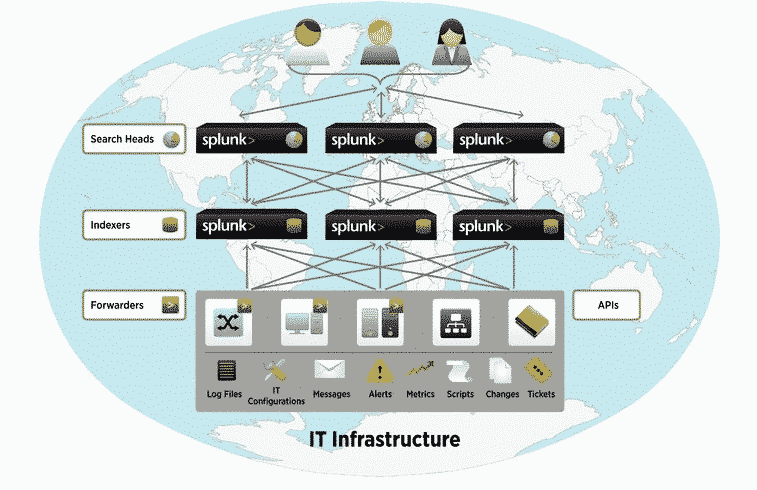
Architecture fonctionnelle de Splunk
L’architecture fonctionnelle de Splunk repose sur trois composantes fondamentales destinées à simplifier une implémentation très distribuée dans l’esprit du big data.
Les « Splunk Search Heads » : ils jouent le rôle de Master Nodes et concrétisent les recherches à travers tous les « Data Store ». Les Search Heads savent quel nœud « Splunk Indexer » appeler et quel index interroger. Les serveurs « Search Heads » jouent donc le rôle d’interface entre l’utilisateur et les données : ils reçoivent les requêtes des utilisateurs, les relaient aux indexers, puis regroupent leurs réponses pour les présenter aux utilisateurs.
Les « Splunk Indexers » : ce sont les « slave nodes » typiques d’une architecture big data. Typiquement, ils sont dédiés à l’exécution du Daemon Splunk. Ils reçoivent les données, les indexent selon une syntaxe spécifique (transformant le flux de caractère en « évènements »), puis ils les préparent pour le stockage.
Les « Splunk Forwarders » : ce sont les agents collecteurs de logs, installés au plus proche des sources de données. Leur rôle est de collecter les données et de les envoyer vers les indexers. Splunk dispose de quelques Forwarders atypiques qui, plutôt que de balayer les journaux, permettent de capturer directement des données sur un flux réseau par exemple. Dans le même ordre d’idées, depuis la version 6.3, Splunk propose des API HTTP/JSON pensées pour l’IoT et pour les processus DevOps afin d’ingérer directement des données à raison de millions d’évènements par seconde sans passer par des agents.
Splunk peut facilement être décliné dans un contexte d’architecture modeste grâce à une entité qui assure toutes les fonctions de collecte, d’indexation, de recherche et de restitution.
Mais il peut aussi être décliné en architecture ultra distribuée comme nous la connaissons au sein de notre environnement de travail qui impose de respecter des normes de cloisonnements architecturaux stricts par respect pour les normes de sécurité. Splunk s’y conforme aisément en se déclinant en autant de versions déployables au travers de ses entités spécialisées : agents collecteurs (très peu gourmands en ressources), renvoyant eux-mêmes vers des indexers en cluster qui, finalement, mettent la donnée à disposition d’entités spécialisées dans la recherche / restitution des données.
Les deux sous-sections suivantes présentent les deux clusters d’indexer et de Search Head.
Cluster indexer
Le Cluster Master
Le cluster gère la réplication de données et le fail over, il distribue les applications vers les indexers soit par un CLI ou par le web.
Le cluster master fournit aux Search Head la liste des indexers qui les gèrent via une interface de gestion.
Les indexers
Les indexers stockent les données dans des buckets, qui composent les indexers, et répliquent ces données avec les autres indexers par le Replication-Factor et le Search-Factor. Les buckets se composent de deux parties : raw-data (données compressées) et files-indexers.
La configuration de Cluster Indexer Master peut se faire de trois manières :
- L’interface web
- Le fichier de configuration
- En ligne de commande
La configuration des indexers peut quant à elle être effectuée de deux manières :
- L’interface web
- Le fichier de configuration
Cluster Search Head
Le rôle principal du Search Head est de restituer les donnes requêtées, sa configuration peut se faire de deux manières :
- Indexers clustering
- Fichier de configuration
Le cluster Search Head se constitue d’un deployer et de search heads : le deployer sert à stocker les applications et les distribue vers les search heads.
Le Search Head exécute les recherches et réplique les données avec les autres membres du cluster via le Replication Factor.
Enfin, un capitaine est un membre du cluster qui intègre des fonctionnalités supplémentaires.
Liens et sources
Documentation en ligne de Splunk
Aide en ligne de Splunk
« Splunk Announces Agreement to Acquire BugSense » [archive], Splunk (consulté le 16 septembre 2013)
Julie Verhage, « These Are the Highest-Paying Companies in America », Bloomberg Business, 12 avril 2017
Annexes
Guide d’installation de Splunk
Splunk est une plateforme de collecte et d’analyse de données générées par une infrastructure technologique, les différentes étapes de son installation sont présentées comme suit.
Installation de Splunk Serveur (Ubuntu 14.04)
- Créez un compte sur le site de Splunk : www.splunk.com
Liens de téléchargement :
https://www.splunk.com/en_us/download/splunk-enterprise.html
https://www.splunk.com/en_us/download/universal-forwarder.html
- Choisissez le paquet correspondant à votre système : dans ce cas, il s’agit d’un Ubuntu.
- Puis copiez le lien wget et exécutez-le en ligne de commande :

- Installez
dpkg-i splunk-6.4.1-debde650d26e-linux-2.6-amd64.deb3 - Créez le script de démarrage
/opt/splunk/bin/splunk enable boot-start - Acceptez la licence
- Redémarrez le service Splunk Start
Exemple de surveillance avec Splunk
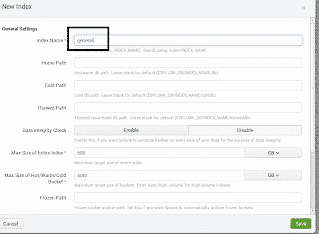
Nous demandons à Splunk d’indexer (pointer) ver un répertoire /var/log/syslog sur sa propre base de données afin qu’il surveille la machine Ubuntu sur laquelle il est installé.
Créez un index nommé général : Setting>index>new index
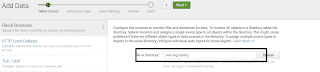
Vous devez ensuite ajouter la source de données :
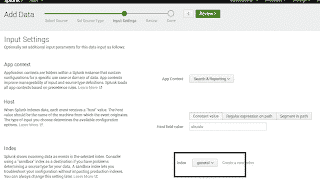
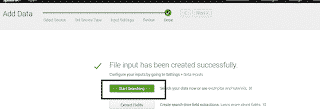
Exemple de recherche de log SNMP sur le serveur Splunk :
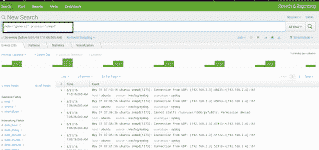
Transformez cette recherche en un panneau du tableau de bord :
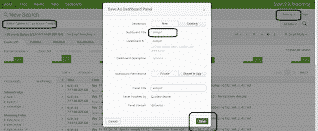
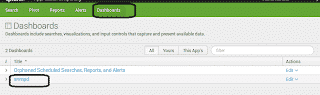
Le spunk universal forwarder est alors installé sur une nouvelle machine à surveiller.
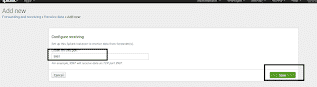
Autorisez le serveur Spunk à recevoir les éléments redirigés des clients : Forwarding and receiving>configure receiving>new>
Installation du client splunk
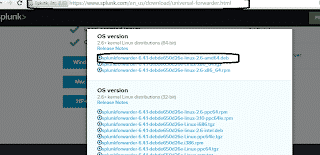
Sur le client (un Ubuntu également), téléchargez le paquet :
https://www.splunk.com/en_us/download/universal-forwarder.html
Copiez le lien wget et exécutez-le en ligne de commande :
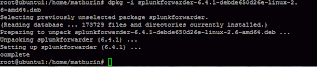
Lancez le script de démarrage : /opt/splunkforwarder/bin/splunk enable boot-start
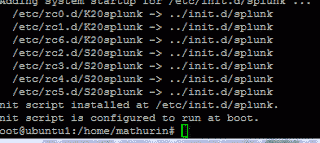
Redémarrez le service /opt/splunkforwarder/bin/splunk start
Lancez la commande qui permet de spécifier les paramètres utiles pour accéder au serveur splunk (récepteur ) :
/opt/splunkforwarder/bin/splunk add forward-server 10.10.10.50:9997
![]()
Changez le mot de passe : /opt/splunkforwarder/bin/splunk edit user admin -password abcd1234
Vérification : /opt/splunkforwarder/bin/splunk list forward-server
![]()
Pour spécifier la source de données :
La commande suivante permet, par exemple, d’ajouter le journal système local à l’index « général » que nous avons précédemment ajouté sur le serveur, et de lui donner le type « syslog » : /opt/splunkforwarder/bin/splunk add monitor /var/log/syslog -index general -sourcetype syslog
![]()
Sur le tableau de bord du serveur :
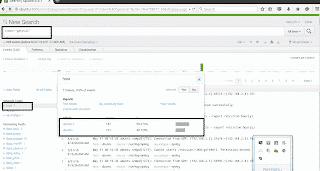
Le forwarder a été ajouté avec succès et ses logs centralisés. Il est alors possible d’associer des résultats de recherche à des alertes.

Vos commentaires
Très bien expliqué. Merci beaucoup pour ce travail.