
Nowadays insert data into a datawarehouse in big data architecture is a synonym of Spark. However this is not your only option. Lingxiao give us some clue about why choising Kafka Streams over Spark streaming.
I have spent the last two years in a big French banking group as a Big Data consultant. During this time, I have been part of a team that oversees the development of a streaming platform to perform real-time ETL processing for a reporting application. Even though it is a common topic, I have encountered a lot of problems to achieve it. The streaming platform choice is the first question to consider and an important choice to make. Consequently, I have evaluated many solutions, among which:
- Spark Streaming,
- Spark Structured Streaming,
- Kafka Streams,
and (here comes the spoil !!) we eventually chose the last one.
In this article, we will explain the reason of this choice although Spark Streaming is a more popular streaming platform. Then we will give some clue about the reasons for choosing Kafka Streams over other alternatives.
Introduction of different platforms
Spark Streaming
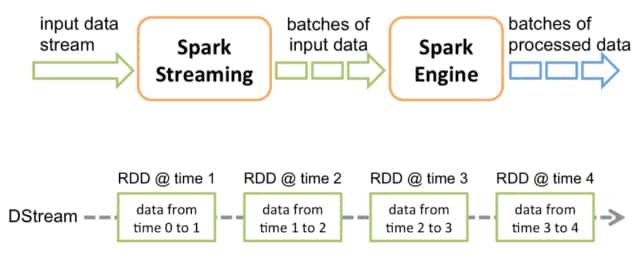
Spark Streaming is an extension of the Spark RDD API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
val ssc = new StreamingContext(conf, Seconds(1))
Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches. The interval in which you divide the data streams can be configured into micro-batch.
Spark Structured Streaming
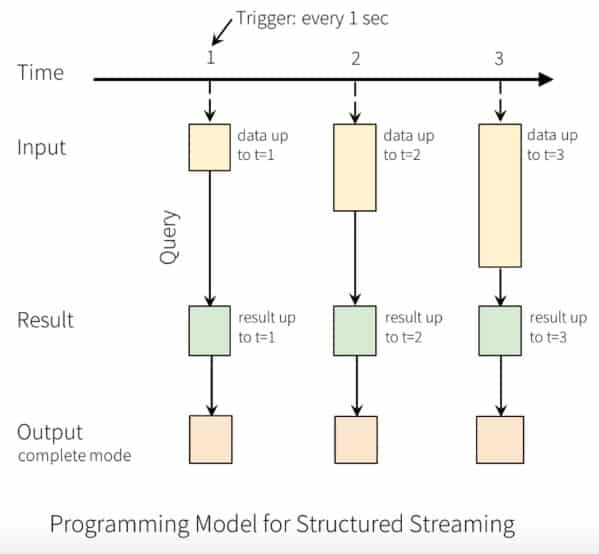
Structured streaming is a scalable and a fault-tolerant stream processing engine built on top of the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously to update the end result as streaming data continue to arrive.
You can use the Dataset/DataFrame API in Scala, Java, Python or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. Finally, the system ensures end-to-end exactly-once fault-tolerance guarantees through checkpointing and Write Ahead Logs. In short, structured streaming provides fast, scalable, fault-tolerant, and end-to-end exactly-once stream processing without having the user to grasp the streaming process.
Although the new version of Spark Structured Streaming provides the continuous streaming mode which promises to give sub latency like Storm and Flink, it is still in an initial stage to be tested with many limitations in operations. Therefore, the cornerstone (in / of??) Spark Structured Streaming is still based on Micro-batch until now.
Kafka Streams
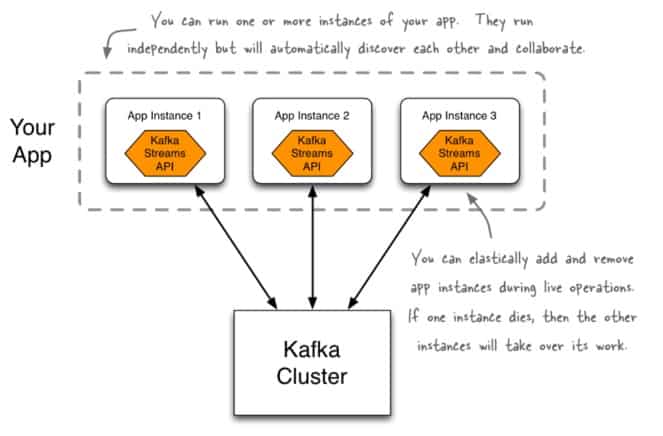
The Streams API of Apache Kafka, available through a Java library, can be used to build highly scalable, elastic, fault-tolerant, distributed applications and microservices. First and foremost, the Kafka Streams API allows you to create real-time applications that power your core business. It is the easiest and the most powerful technology to process data stored in Kafka. It has been built upon important concepts of streaming process such as:
- efficient management of application state,
- fast and efficient aggregations and joins,
- proper distinction between event-time and processing-time,
- seamless handling of late-arriving and out-of-order data.
A unique feature of the Kafka Streams API is that the application you build with it are standard. So, it can be packaged, deployed, and monitored like any other Java application – there is no need to install separate processing clusters or similar special-purpose and expensive infrastructure!
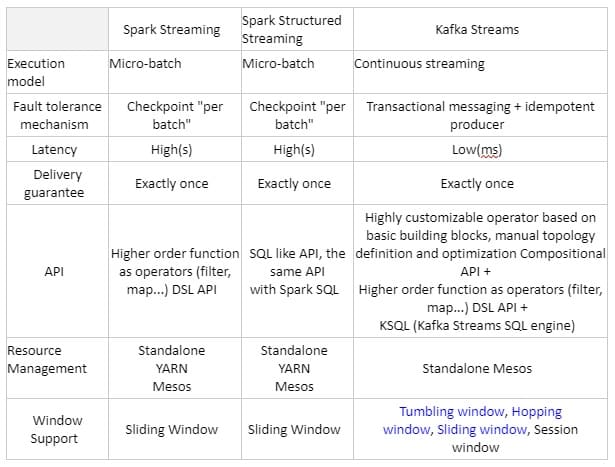
Comparison of Spark Streaming, Spark Structured Streaming and Kafka Streams
Why did we choose Kafka Streams?
Our application is named NeoLinks. It is a reporting application for clients of a Security Services company. Each day, this application receives millions of messages using many formats (such as CSV or SWIFT) from different sources (like message queues from other transactional applications) and different businesses (Derivatives, Fund Administration, Cash, and so on).
In our process, all messages must be parsed using WebSphere TX and pushed into different topics. Then either Kafka Streams or Spark Streaming is used to do the Streaming ETL processing. Finally, the prepared data will be loaded into Sybase ASE (data provider for our web and mobile application), Sybase IQ (our OLAP data warehouse) and ElasticSearch (service provider for documents search).
![]()
We have tested both solutions of Kafka Streams and Spark Streaming. Finally, we went for the former one for the reasons below:
- We have more than 10 business lines, and each business line has its own ETL Logic. Our total import volume is big, however limited to a maximum of 10G per day for each business line. Therefore, it is not very interesting for us to build a big « centralized » Spark Cluster to do the various jobs. What we need is a micro-service big data platform which can provide isolated environments for different business lines. Kafka Streams and Mesos can satisfy those requirements.
- For some businesses, we need to guarantee the transaction for the processing of streaming despite complex ETL business logic. We have 16 different modules for each import file, and each module has its own logic of ETL. We have the responsibility to guarantee the integrality of the 16 modules for the processing of each import file. This is impossible to realize with Spark Streaming’s SQL API and hard to achieve with Spark Streaming’s DSL API. Finally, we we chose to resolve this issue using the Kafka Streams Processor API with our custom Processors and StateStores.
- The overhead for the generation and scheduling of micro-batch of Spark Streaming and Spark Structured Streaming is huge. If you want to reach a latency of few milliseconds, the overhead may be unaffordable.
- Lastly, I have observed that, for the same task, Kafka Streams consume much less memory than Spark Streaming and Spark Structured Streaming.
Conclusion
During these two years spent building this application (maybe a small precision about this application can come here. It is always good to wrap up with a small summary.), I have shown that Kafka Streams is agile and easy to use. It consumes fewer resources compared to Spark Streaming. Therefore, you should consider Kafka Streams when:
- Your business does not have a huge volume of import (this avoids maintaining a big cluster to distribute computation),
- You want to do custom operations or/and maintain a complex state during the streaming process,
- You have a requirement of millisecond latency.

Vos commentaires
Thanks, Lingxiao Wang. This is an excellent article .
Looking forward to reading more from you.
Best Regards,
Salim