
Tout ce que vous avez toujours souhaité savoir sur Spark shuffle sans jamais oser le demander… La réponse dans cet article avec Abdelwahab Touil, notre expert big data.
Un shuffle est une opération qui consiste à déplacer des données depuis une machine (physique ou virtuelle) vers une autre machine, et ce pour qu’elle soit dans le même réseau local ou non. Chaque type de shuffle a ses avantages et ses inconvénients. Dans cet article, nous tâcherons d’expliquer comment Spark traite les shuffles.
Introduction à la notion de shuffle
Prenons l’exemple de l’exécution d’un map reduce. Après la phase map et avant la phase reduce, les opérations passent par une étape intermédiaire qui est le shuffle. En quelque sorte, cette étape permet de trier les résultats de la phase map avant de les passer à la phase reduce.
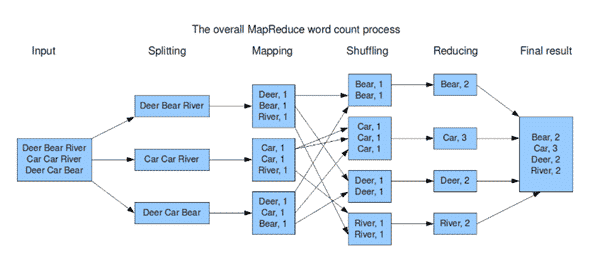
[1] : Exemple d’un map reduce
Plus spécifiquement, un shuffle dans Apache Spark peut se traduire lors d’un échange de données entre workers. Or une des problématiques de performance dans des traitements parallélisés repose sur le shuffle, d’où la nécessité de bien comprendre comment Spark fonctionne afin d’écrire des programmes qui le limitent au maximum.
Pourquoi le shuffle peut-il affecter la performance d’exécution d’un programme ? La réponse est simple : un shuffle va redistribuer la donnée sur les workers. L’idée est la même que lorsque l’on mélange des données avant de les trier. Il va donc déplacer les données, impliquant alors des coûts liés à la sérialisation / désérialisation pour le transfert de la donnée dans les réseaux, mais aussi à la compression – pour réduire la bande passante réseau – et aussi au I/O disque.
De plus, il va falloir recréer des partitions (pour les nœuds qui reçoivent la donnée). Or, calculer des partitions a pour conséquence d’effectuer un tri, ce qui représente une opération coûteuse.
Apache Spark exécute un traitement étape par étape. Une étape pour rappel est construite par un DAG (Diagram ascyclic graph). En deux mots, le DAG est un graphique indiquant la séquence d’opérations effectuées sur les RDD cibles.
Action et transformation en Spark
Apache Spark introduit ce qu’on appelle la Lazy Evaluation, qui rend l’exécution des traitements rapide et, de ce fait, divise les opérations à exécuter en deux groupes : les transformations et les actions. Les traitements Spark ne sont exécutés que lorsqu’une action est appelée.
Une transformation est une fonction qui prend un RDD / DF et retourne un autre RDD / DF.
Une action est une opération Spark qui renvoie un élément autre qu’un RDD / DF. Elle déclenche l’évaluation des partitions. Par exemple, retourner des données au driver (avec des opérations comme un count ou collecter) ou écrire des données sur un système de stockage externe. Les actions déclenchent le scheduler qui construit le DAG basé sur les dépendances entre les transformations RDD.
En d’autres termes, Spark évalue une action en parcourant vers l’arrière le DAG pour identifier les opérations à exécuter à partir de l’action appelée, en général les transformations appliquées avant cette action.
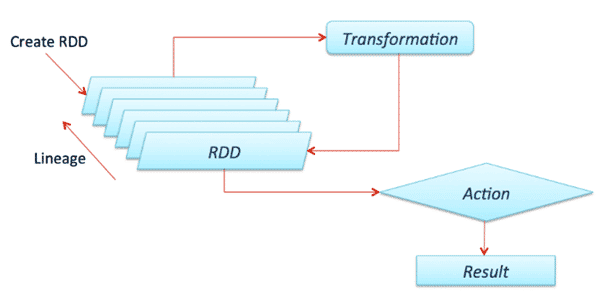
[2] : Action et transformation dans Spark
Narrow et wide
Pour comprendre comment Spark lance les traitements sur les RDD / DF, il faut comprendre un point important sur les transformations : il existe les transformations avec une narrow dépendance et avec une wide dépendance. Spark évalue les transformations différemment en fonction des deux types. Les performances d’un job Spark par conséquent ne sont pas les mêmes.
Conceptuellement, la transformation en narrow dépendance est celle pour qui chaque partition d’un RDD fils a une dépendance simple et limitée de sa partition RDD parent.
On dit que la dépendance est de type narrow si les partitions peuvent être déterminées au moment de la création de la partition, quelles que soient les valeurs des enregistrements dans les partitions parentes, et si chaque parent a au plus une partition fils.
Plus précisément, si une partition peut dépendre soit d’un parent (ex : un map), soit d’un sous-ensemble unique des partitions parentes qui est connu au moment de la création (ex : coalesce).
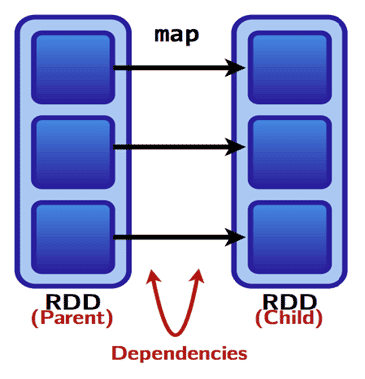
[2] : Transformation avec une narrow dépendance
La wide transformation déplace les données d’une manière particulière entres les workers, par exemple, en fonction de la valeur des clés. Elle crée alors un shuffle comme l’exemple de tri. Les données sont partitionnées afin que celles qui partagent la même clé soient dans la même partition. Les transformations wide incluent les tris, ReduceByKey, groupByKey, jointures et tout ce qui appelle la fonction repartiton.
Dans certains cas, quand les données sont bien partitionnées entre les workers, la wide transformation ne génère pas de shuffle.
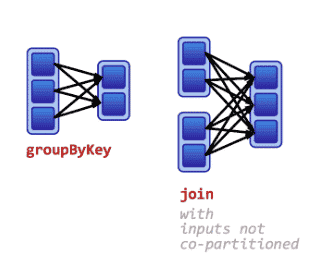
[2] : Transformation avec une Wide dépendance
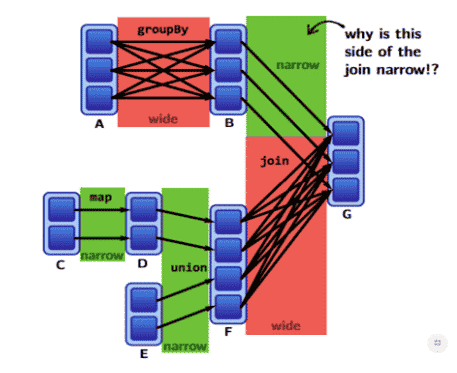
[2] : Exemple d’opération en Spark
Les opérations de type union, map, filter et certain join engendrent une transformation de type narrow. En revanche, les groupBy, repartiton, intersection, distinct et aussi le join engendrent une transformation de type wide. Le join génère une narrow dépendance si et seulement si les données sont bien partitionnées selon leurs clés. La fonction dependencies affiche les informations de dépendance entre les opérations du job Spark.
Le shuffle dans Spark
Avant d’évoquer le fonctionnement du shuffle dans Spark, il est important de connaître l’intérêt de deux paramètres :
- spark.shuffle.compress (True par défaut) : ce paramètre est utilisé en général pour compresser le résultat de la phase map,
- spark.shuffle.spill.compress ets quant à lui employé pour compresser les fichiers de résultat intermédiaire.
La compression par défaut est snappy.
De même, il existe 3 types de shuffle dans Spark : le hash, le sort et tungsten-sort. Cette valeur est mentionnée dans le paramètre spark.shuffle.manager parameter. Le “sort” est la valeur par défaut depuis la version de Spark 1.2.0.
Le hash shuffle
C’était l’option par défaut dans la version 1.2.0 de Spark (spark.shuffle.manager = hash). Ce type de shuffle présente beaucoup d’inconvénients liés au nombre de fichiers créés. Chaque mapper Spark va créer un fichier pour chaque reducer.
Si on fait le calcul, on aura M*R fichiers (M : Nombre de mapper et R : Nombre de reducer). Dans un monde de big data – et si on essaie de faire des opérations analytics complexes –, vous imaginez le nombre de fichiers que cette méthode va créer et les problèmes engendrés (I/O, bande passante, fichier TMP…).
Ci-dessous : l’illustration du fonctionnement de ce 1er type de Spark shuffle :
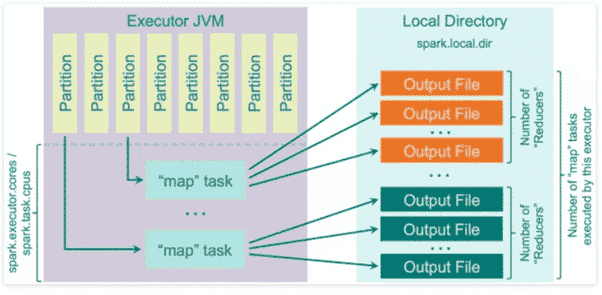
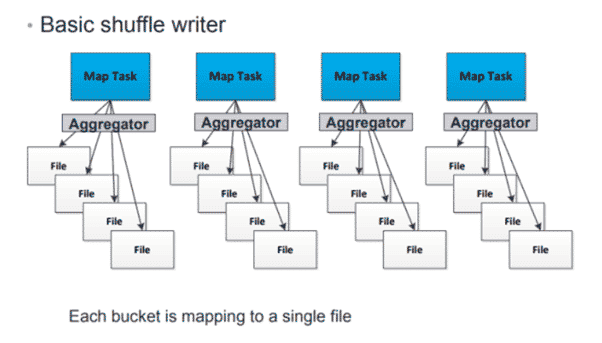
[3] : Le hash shuffle dans Apache Spark
Dans cet exemple, Spark génère un fichier par opération map qui sera traité par un reducer. Le nombre de fichiers générés peut rapidement s’avérer un problème d’optimisation lors de l’exécution du programme, d’où l’introduction du paramètre qui permet de regrouper ou de merger ces petits (pas toujours) fichiers en un seul consolideur.
Les développeurs de Spark ont implémenté un optimisateur pour ce type de shuffle avec le paramètre spark.shuffle.consolidateFiles = False par défaut. Changer la valeur de ce paramètre à True revient à consolider les résultats des mappeurs (fichiers créés par les mappers).
Je prends un exemple pour illustrer l’avantage d’utilisation du paramètre consolidateFiles avec ce type de shuffle. Imaginez que vous avez un cluster avec X exécuteurs. Dans chaque exécuteur, vous disposez de N coeur et chaque tâche Spark demande T nombre de Cpus (spark.task.cpus). Le nombre de fichiers créés pendant la phase shuffle sera égal à X*N/T*R.
Plus le nombre de cette formule est petit, plus le job spark sera performant. En revanche, attention à la taille de chaque fichier. Des fichiers volumineux induiront des performances médiocres et souvent des Oom (Out of memory). Mais cette solution a, entre autres, l’intelligence de traiter un groupe de fichiers map qui réduisent le temps de tri des résultats intermédiaires ainsi que le I/O.

[3] : Illustration du hash Spark shuffle après consolidation
Quand Spark exécute un shuffle et commence à écrire les fichiers maps, les données sont sérialisées et éventuellement compressées. Les opérations inverses sont effectuées dans la phase lecture des fichiers maps. Un des paramètres pour améliorer le temps de lecture est « spark.reducer.maxSizeInFlight » (48 Mo par défaut), qui détermine la taille de fichier attendu par chaque reducer des workers..
Augmenter la taille de ces fichiers voudrait dire que chaque reducer attendrait de chaque mapper un fichier plus gros (mais moins nombreux), ce qui améliorerait les performances. Mais cela augmenterait également l’utilisation de la mémoire par les reducers. Spark a donc abandonné ce type de shuffle avec la sortie de la version 2.
Le sort shuffle
Ce type de shuffle a été introduit dans le Framework à partir de la version 1.2.0. C’est le paramètre par défaut (spark.shuffle.manager = sort). L’algorithme ressemble à celui de MapReduce implémenté dans Hadoop. Avec le hash shuffle, comme nous l’avons vu précédemment, Spark crée un fichier séparé pour chaque tâche de reduce alors qu’avec le Sort, Spark crée un seul fichier trié par un id pour une tâche reduce.
Ceci va permettre de récupérer le bloc de données lié à un reduce « x » en obtenant simplement des informations sur la position du bloc de données associé dans le fichier.
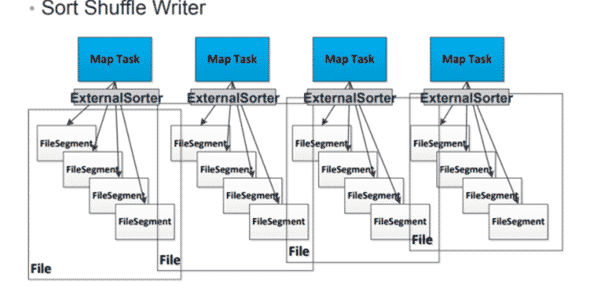
[3] : Le sort shuffle dans Apache Spark
Comment ça marche ? La phase map génère deux fichiers : des enregistrements (fichiers) et des index (un fichier index).
- Les reducers utilisent le fichier d’index pour voir où se situent les enregistrements dont ils ont besoin. Une fois qu’ils l’identifient, ils récupèrent les données et les parcourent pour construire la sortie attendue.
- L’algorithme exécute un tri sur les résultats de la phase map mais ne merge pas les données dans la phase reduce, ce qui va déclencher un autre tri si l’ordre des données est nécessaire dans le merge (order by dans le résultat final).
Information à connaître : le tri en phase reduce s’effectue avec l’algorithme TimSort (5) qui est un algorithme qui tire parti des entrées prétriées.
Spark utilise la structure AppendOnlyMap pour stocker les données de sortie des « maps » en mémoire. Si les données sont volumineuses, Spark exécute, sur les données stockées dans cet AppendOnlyMap, le TimSort pour écrire sur le disque.
Admettant que vous n’avez pas assez de Ram pour stocker le résultat de la phase map, les données devront être poussées sur le disque. Le paramètre spark.shuffle.spill permet de contrôler cela. Par défaut, il est à true. Si vous le modifiez et qu’il n’y a pas assez de RAM pour stocker les sortie « map », vous obtiendrez simplement une erreur OOM.
La quantité de mémoire nécessaire pour stocker le résultat des maps est =
Taille du Heap JVM * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction, avec valeurs par défaut = Taille du Heap JVM * 0,2 * 0,8.
Notez que si vous exécutez plusieurs threads au sein du même exécuteur (en définissant le paramètre spark.task.cpus > 1), la mémoire moyenne disponible pour stocker le résultat « map » pour chaque tâche sera =
Taille du Heap* spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus.
Pour chaque fichier créé durant la phase map, la fusion n’est effectuée que lorsque les données sont demandées par le reducer. Cette fusion s’effectue en temps réel, c’est-à-dire qu’elle n’effectue pas des écritures sur disque comme cela se produit dans Hadoop MapReduce, mais elle se fait dynamiquement durant l’exécution du programme en mémoire.
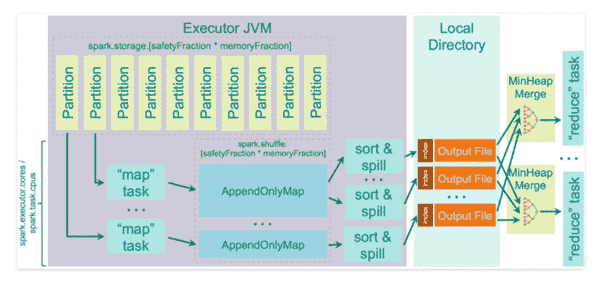
[4] : Le sort shuffle dans Apache Spark
Unsafe shuffle ou le Tungsten sort
Nouveau à partir de la version Spark 1.4.0+ et paramétrable via spark.shuffle.manager = tungsten-sort . Ce code fait partie du projet « Tungsten ». Voici les optimisations apportées avec ce shuffle :
- S’exécute sur des données binaires sérialisées sans avoir à les désérialiser. Il utilise des fonctions de copie de mémoire non sécurisées (sun.misc.Unsafe) pour copier directement les données, ce qui fonctionne très bien pour les données sérialisées car en fait ce n’est qu’un tableau d’octets.
- Utilise un cache efficace ShuffleExternalSorter qui trie des tableaux de pointeurs d’enregistrement compressés et des ID de partition. En utilisant seulement 8 octets par enregistrement dans le tableau de tri, il le rend efficace avec le cache du processeur.
- Comme les données ne sont pas désérialisées, l’enregistrement des données est effectué directement.
- Des optimisations de merge lors de l’enregistrement sont automatiquement appliquées lorsque la compression codec du shuffle supporte la concaténation des flux sérialisés. Ceci est actuellement pris en charge par le sérialiseur LZF de Spark si le paramètre “shuffle.unsafe.fastMergeEnabled” est activé.
L’autre optimisation repose sur l’introduction du stockage off-heap. Cette option de shuffle est utilisée lorsque ces conditions sont remplies :
- Le shuffle dépendance ne spécifie aucune agrégation. L’application de l’agrégation signifie la nécessité de stocker la valeur désérialisée pour pouvoir y agréger de nouvelles valeurs entrantes. De cette façon, vous perdez le principal avantage de ce shuffle avec ses opérations sur les données sérialisées.
- Le sérialiseur du shuffle prend en charge la relocalisation des valeurs sérialisées (ceci est actuellement pris en charge par KryoSerializer et le sérialiseur personnalisé de Spark SQL).
- Le shuffle produit moins de 16 777 216 partitions.
- Aucun enregistrement ne dépasse 128 Mo sous forme sérialisée.
Vous devez également comprendre que le tri avec ce shuffle n’est effectué que sur l’ID de la partition, ce qui veut dire que les optimisations de merge des données prétriées dans la phase reduce n’est plus possible. Le tri dans cette opération est effectué sur la base des valeurs de 8 octets. Chaque valeur code à la fois le lien vers l’élément de données sérialisé et le numéro de partition.
Voici comment nous obtenons une limitation des partitions en sortie de 1.6b.
Tout d’abord, pour chaque écriture de données, il trie le tableau de pointeurs décrit et génère un fichier de partition indexé, puis il fusionne ces fichiers de partition en un seul fichier de sortie indexé.
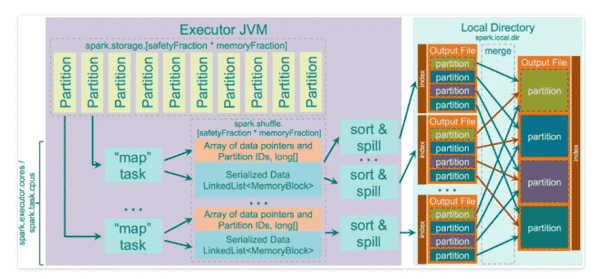
[4] : Le unsafe shuffle dans Apache Spark
Le shuffle externe
Disponible depuis la version Spark 1.2. Lorsque vous exécutez Spark avec YARN ou MESOS et que l’allocation dynamique des ressources est activée, ce type de shuffle peut être utilisée pour libérer les exécuteurs qui n’ont aucune tâche en cours d’exécution. Ce type de shuffle est également disponible en mode standalone.
Si le shuffle externe est activé, alors c’est le shuffle service qui reprend la gestion du shuffle et non plus les exécuteurs, ce qui décharge les exécuteurs et limite aussi les caches d’applications dans le cas où un exécuteur est perdu (les données ne vont pas être recalculées). Le shuffle externe doit être activé (configuration spark.shuffle.service.enabled sur true) et spark.dynamicAllocation.enabled sur true pour que l’allocation dynamique puisse avoir lieu.
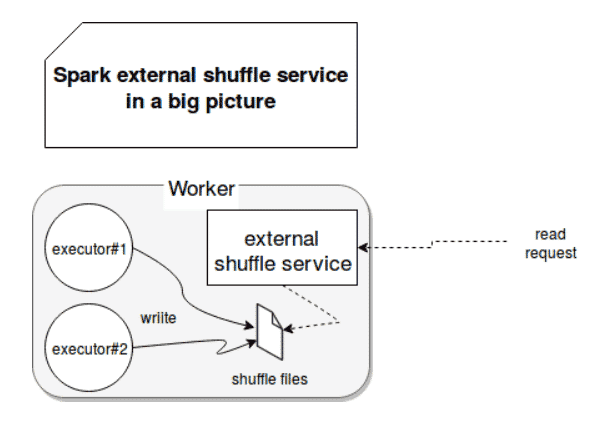
[6] : Shuffle externe dans Apache Spark
Conclusion
Chaque type de shuffle a ses avantages et ses inconvénients. Pour le hash shuffle, l’avantage principal repose sur sa rapidité : pas de risque de surcharge de la mémoire et pas non plus de surcharge de I/O (pas de tri – lecture et écriture une fois). En revanche, lorsque les partitions des données sont volumineuses, les performances sont dégradées.
Le sort shuffle ne génère pas beaucoup de fichiers à la phase map et réduit aussi le nombre d’opérations I/O. Mais il implique de passer du temps à trier les données sauf si vous utilisez des disques de type SSD (qui réduisent la latence). Le unsafe shuffle apporte beaucoup d’optimisations mais manque quand même de stabilité, ne permet pas le tri off-heap ni le tri de données dans la phase map.
Dans tous les cas, vous devez écrire vos traitements Spark de telle sorte à limiter le maximum de transferts de données entre les workers pour réduire le shuffle de façon optimale. Vous pouvez aussi tunner la gestion des shuffles avec ces paramètres (à ajouter lors du lancement du job avec Spark submit ou dans le fichier de configuration spark) :
- spark.shuffle.file.buffer : si vous disposez d’une mémoire suffisante, vous pouvez doubler la valeur par défaut, ce qui permet de réduire le temps de I/O.
- · Spark.reducer.maxSizeInFlight : ce paramètre est utilisé pour définir la taille du buffer du shuffle. Augmentez la taille (ex : 96 m) si vous disposez d’assez de mémoire sur votre cluster, ce qui réduira le trafic réseau.
- · Spark.shuffle.io.maxRetries : représente le nombre maximal de tentatives pouvant être réessayées pour la lecture des données générées par un shuffle. Si vous avez des task qui produisent un shuffle gourmand en temps d’exécution, il faudrait augmenter la valeur (ex : 30 ou 40). Cela garantit une certaine stabilité à vos job Spark.
- · Spark.shuffle.io.retryWait : ce paramètre complète le précédent et définit le temps d’attente entre les tentatives de relecture shuffle. Augmentez la valeur pour plus de stabilité du job.
- Spark.shuffle.memoryFraction : ce paramètre représente la taille en mémoire affectée au shuffle pour les opérations d’agrégations. La valeur par défaut est de 20 %. Augmenter ce paramètre est recommandé si vous disposez d’assez de ram. Cela permet de réduire l’écriture sur disque dans des opérations d’agrégation. Assurez-vous que le paramètre spark.memory.useLegacyMode est à True.
- · Spark.shuffle.consolidateFiles : ces paramètres vus dans l’article.
- · spark.shuffle.registration.timeout : délais d’expiration en millisecondes pour l’inscription au shuffle externe.
Pour finir, je vous invite aussi à essayer les paramètres spark.default.parallelism et spark.network.timeout, et la fonction coalese / repartition pour plus d’optimisation et une meilleure répartition des données sur les workers. Dans nombre de cas, cela favorise l’amélioration des performances des jobs en réduisant le shuffle.
Références
2: https://github.com/rohgar/scala-spark-4/wiki/Wide-vs-Narrow-Dependencies
3 : https://web.archive.org/web/20201201014628/https://blog.imaginea.com/spark-shuffle-tuning/
4 : https://slideplayer.com/slide/9851801/
5 : https://fr.wikipedia.org/wiki/Timsort
6 : https://www.waitingforcode.com/apache-spark/external-shuffle-service-apache-spark/read
https://spark.apache.org/docs/latest/configuration.html#shuffle-behavior

Pas encore de commentaires