
L’article précédent traitait du concept de partition en Spark et des méthodes permettant de re-partitionner ses données. Mais pour quoi faire ?
Si vous développez en Spark, vous vous êtes déjà rendu compte que certains de vos algorithmes, qui semblent pourtant si simples, prennent énormément de temps à s’exécuter, sans savoir pourquoi. Ce peut être dû à un problème de partitionnement.
Regardons ensemble les difficultés que vous pouvez rencontrer dans vos programmes ainsi que des techniques pour les résoudre.
Le cas basique : un nombre de partitions trop faible ou trop grand
On rappelle le premier problème pouvant survenir : un nombre de partitions trop faible ou trop grand pour les capacités de votre cluster (ou de votre machine).
Si vous n’avez pas lu l’article précédent traitant de ce point particulier, je vous invite vivement à le faire.
En résumé, dans la plupart des cas, afin d’exécuter correctement vos traitements, vous devriez avoir environ 3-4 partitions par core disponible.
Cela permet de ne pas sous-utiliser les ressources disponibles (moins d’une task par core donc des cores ne faisant rien) sans pour autant mettre trop de pression au niveau de la gestion des tasks (si vous avez des millions de partitions, votre application passera son temps à les gérer au lieu d’exécuter le traitement en lui-même).
Évidemment, ce ratio n’est pas gravé dans le marbre et rien ne vaut l’expérimentation, chaque cluster étant différent. Néanmoins, il s’agit déjà d’un bon début afin d’accélérer vos traitements.
Le cas du data skewing
Un problème assez récurrent et pas toujours facile à détecter, j’ai nommé, le data skewing !
Pour ceux qui n’ont jamais entendu ce terme, cela signifie que les données ne sont pas uniformément distribuées parmi les partitions.
Par exemple, analysons les partitions créées par le code suivant :
val rdd = session.sparkContext.parallelize(0 until 1000) rdd .mapPartitions(iterator => Array(iterator.length).iterator) .collect .foreach(println)
Ce code retourne le nombre d’éléments dans chaque partition. Sur ma machine, le code suivant produit 4 partitions possédant chacune 250 éléments. Jusqu’ici, rien d’anormal, Spark découpe chaque partition le plus équitablement possible lors du parallelize.
Exécutons maintenant la suite du code :
rdd .filter(_ (nb to 1000000))
Si on analyse maintenant le contenu des 4 partitions, on s’aperçoit qu’une partition contient 249969125 éléments alors que les trois autres sont vides.
Schématiquement, voici ce qu’il s’est passé :
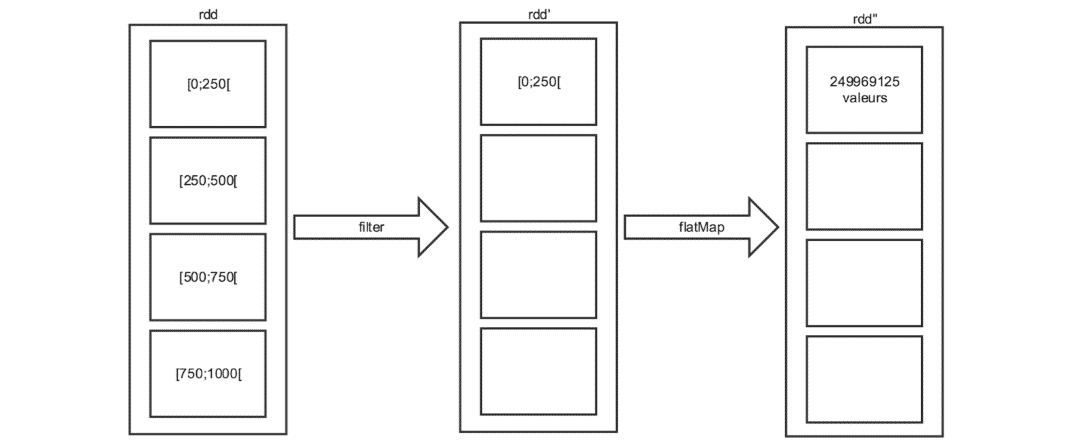
Ainsi, même si au début du programme les données étaient convenablement partitionnées, elles le sont désormais beaucoup moins. En effet, seules les données de la 1ère partition n’ont pas été filtrées. Il n’y a donc plus que des valeurs dans cette partition, ce qui est impossible à voir à la simple lecture du code.
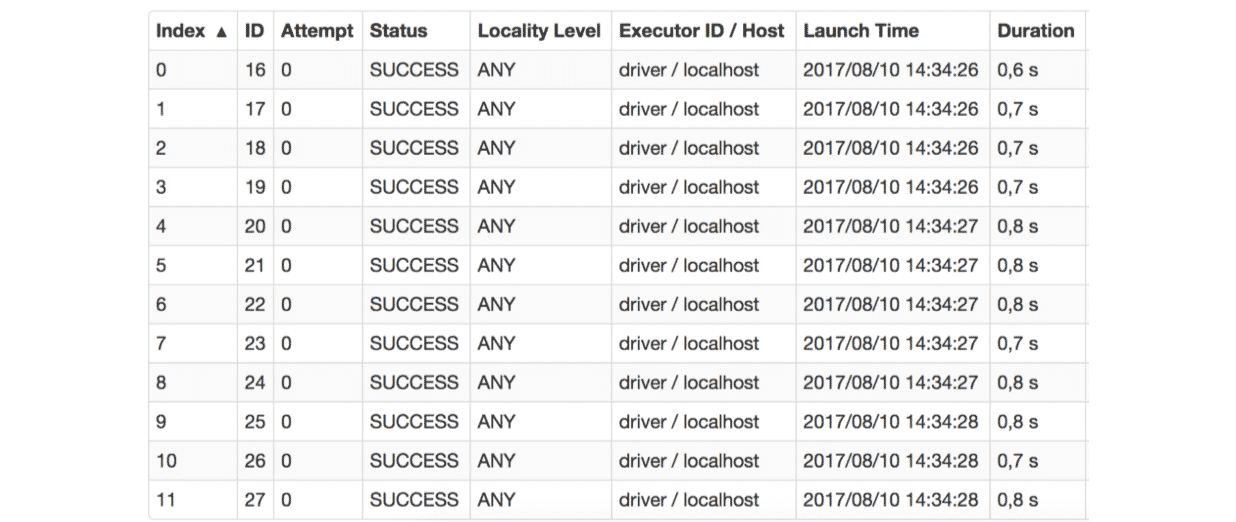
Exécutons maintenant un simple count sur ce rdd.
Voici les informations relatives à ce calcul, trouvées sur la Web UI de Spark.

La colonne qui nous intéresse ici est la colonne “Duration”. On voit, à quel point le calcul aura été mal parallélisé avec le calcul de la partition 0 prenant 275 fois plus de temps que le calcul de toutes les autres partitions réunies. C’est finalement logique, car toutes les données se trouvent dans la partition 0.
Changeons désormais le code comme suit :
rdd .filter(_ (nb to 1000000))
Voilà désormais comment se comporte l’exécution du count.
Ici, le calcul est très bien parallélisé, et n’a pris que quelques secondes à s’exécuter contre 22 précédemment. Imaginez le gain possible dans un contexte réel !
Comment cela s’explique-t-il ?
Ici, nous avons partitionné nos données au bon moment !
Schématiquement, voilà ce que nous avons fait :
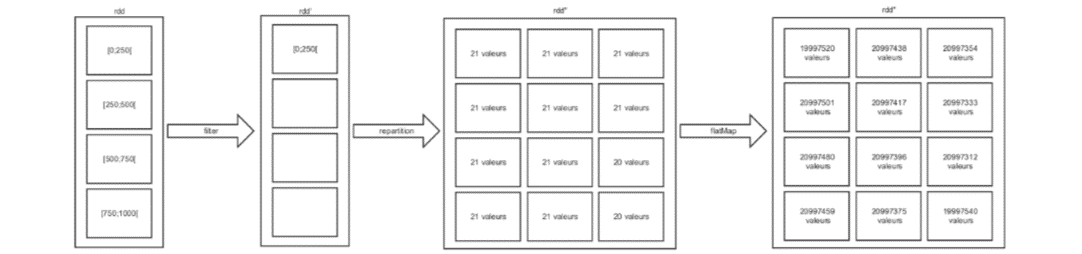
Ce qui nous a permis d’équilibrer le calcul, les partitions étant à peu près de nouveau équivalentes après le re-partitionnement.
Revenons au “bon moment”. Pourquoi n’avons-nous pas plutôt re-partitionné nos données après le flatMap ?
Re-partitioner les données équivaut à déclencher un shuffle ! Calculer des clés et “shuffle” 250 paires prend donc beaucoup moins de temps et de ressources que de calculer des clés et “shuffle” 249969125 paires ! Si nous avions re-partitionné après le flatMap, cela aurait pu prendre des dizaines de minutes, voire des heures.
Le cas des jointures et autres calculs basés sur des clés
Un autre problème peut survenir lors de l’utilisation régulière d’instructions se servant des clés de vos RDD, comme les jointures, agrégations et autres regroupements.
Prenons un exemple, celui d’un fichier contenant des informations qui concernent vos utilisateurs et des noms de fichiers qui contiennent des logs de pages produits qu’ils ont visitées.
val users = session.sparkContext.sequenceFile[Int, UserInfo]("hdfs://…")
val fileNames: List[String] = List("hdfs://...","hdfs://...","hdfs://...")
Avec ces données, vous souhaitez pouvoir compter le nombre de fois où vos utilisateurs ont visité la page d’un produit qu’ils n’ont jamais acheté. Vous pourriez faire comme suit :
fileNames.foldLeft(0L) {
case (acc, file) => {
val logs = session.sparkContext.sequenceFile[Int, LogInfo](file)
val count = users
.join(logs)
.filter {
case (userID, (userInfo, logInfo)) => !userInfo.products.contains(logInfo.product)
}.count
acc + count
}
}
Ce code fonctionne tel qu’attendu, mais l’exécution est loin d’être efficace !
Ce code pose deux problèmes :
- Le join n’a aucune idée de comment les données sont partitionnées, il sera donc obligé de hash chacune des clés des deux RDD afin de regrouper sur le même nœud les valeurs de users et logs correspondant à la même clé avant d’effectuer la jointure
- Le shuffling de users sera exécuté autant de fois qu’il y a de fichiers de logs. C’est inutile, car le shuffling de users produira à chaque fois le même résultat.
Voici la marche à suivre pour résoudre ces deux problèmes :
val users = session.sparkContext
.sequenceFile[Int, UserInfo]("hdfs://…")
.partitionBy(new HashPartitioner(12)) //le nombre de partitions que vous souhaitez
.cache
Le HashPartitioner solutionne le premier problème. En effet, il permet d’indiquer à la méthode join comment users est partitionné et donc de ne shuffle que logs.
“Mais pourquoi ne pas partitionner aussi logs, de manière à éviter tout shuffling”, vous demandez-vous ?
Tout simplement, car vous auriez supprimé le shuffle au niveau du join pour le rajouter au moment du re-partitionnement. Le partitionBy n’est donc utile que si vous comptez utiliser votre RDD plusieurs fois, comme users.
La seconde partie de la solution est l’appel à la méthode cache. Sans cet appel, users aurait été re-partitionné par le HashPartitioner à chaque appel de join, nous serions revenus au point de départ, à savoir, un shuffle à chaque join.
Les pièges à éviter
Durant votre phase d’optimisation, vous pouvez tenter à votre tour de gérer manuellement le partitionnement de vos données. Afin de le faire dans les meilleures conditions, voici quelques points à garder en tête.
1) Le partitioner peut se perdre
Imaginons une variable rdd de type RDD[(K,V)], quel serait alors le retour de ce code ?
val partitioned = rdd.partitionBy(new HashPartitioner(12)) partitioned.partitioner == partitioned.map(x => x).partitioner
Le résultat serait false. En effet la méthode map fait perdre son partitioner à un RDD.
Ici, cela peut sembler étrange de perdre le partitioner alors que nous avons simplement utilisé la fonction identité dans le map. Néanmoins, c’est compréhensible si l’on regarde la signature de la méthode map :
def map[U: ClassTag](f: T => U): RDD[U]
Ici, la méthode n’a aucun moyen de s’assurer que les clés n’ont pas été modifiées puisque la fonction s’exécutera sur la paire [clé,valeur]. Le partitioner est donc perdu.
Heureusement, Spark met à disposition deux méthodes, respectivement mapValues et flatMapValues qui nous permettent de map sur nos valeurs tout en gardant le partitioner, puisque la clé est impossible à modifier.
Il est donc important d’avoir ce point en tête et de se renseigner sur les méthodes utilisées sous peine de perdre certaines optimisations ! Par exemple, si nous avions effectué un map après un partitionBy, aucune optimisation n’aurait pu être faite au niveau d’un join.
2) Repartitioner n’est pas toujours la solution
Malgré les gains possibles dans certains cas, le re-partitionnement de vos données ne vous assure en aucun cas un gain de performance.
Par exemple, le code suivant ne présente aucune plus-value :
val p = new HashPartitioner(12) val rdd = sc.parallelize(1 to 1000).keyBy(x => x).partitionBy(p) val rdd2 = sc.parallelize(1 to 1000).keyBy(x => x).partitionBy(p) rdd.join(rdd2)
Effectivement, comme vu plus haut dans l’article, le re-partitionnement des données cause un shuffle. Re-partitionner avant d’effectuer une seule opération “by key” (jointure, regroupement, ou autre) n’a donc aucun impact positif. Vous déplacez simplement le shuffle d’un endroit à un autre.
De façon similaire, re-partitionner pour rééquilibrer vos données peut parfois se révéler très coûteux et éclipser les gains potentiels sur l’opération que l’on essaye d’optimiser.
Dans l’exemple du data skewing, si nous avions re-partitionné après le flatMap, nous aurions pu perdre des heures en shuffling pour un gain de quelques secondes au niveau du count. Assurez-vous que lorsque vous re-partitionnez vos données, vous le faites à un stade où les données matérialisées sont minimales.
Pour conclure
Les solutions présentées plus haut sont plus à considérer comme des conseils et guidelines qui permettent d’analyser votre code et d’expérimenter durant votre phase d’optimisation. En aucun cas, il ne peut s’agir d’une solution out-of-the-box fonctionnant dans chaque cas. On ne saurait trop répéter que chaque cas est différent (volumétrie, données, ressources, traitements, etc.).

Pas encore de commentaires