
La performance CI/CD est aujourd’hui un enjeu clé pour les organisations qui souhaitent accélérer leurs cycles de livraison tout en maintenant un haut niveau de qualité. Les pipelines CI/CD constituent la colonne vertébrale des chaînes DevOps : elles automatisent l’intégration du code, l’exécution des tests et le déploiement des applications, afin de réduire les délais de mise en production et d’améliorer la fiabilité des livraisons.
En théorie, un pipeline CI/CD performante permet aux équipes de développement de travailler plus vite, un avec moins de frictions et une meilleure visibilité sur l’état de la production logicielle. En pratique, de nombreux facteurs peuvent dégrader cette performance : temps d’attente excessifs liés à la saturation des runners, durées d’exécution trop longues, pipelines fragiles, manque de standardisation ou absence d’indicateurs permettant de piloter efficacement la chaîne CI/CD. Ces dysfonctionnements ont un impact direct sur la vélocité des équipes, la productivité globale et la satisfaction des développeurs.
Améliorer la performance CI/CD ne consiste pas uniquement à optimiser quelques jobs ou à ajouter ponctuellement des ressources. Cela implique une démarche structurée de pilotage, combinant l’écoute des équipes, l’analyse objective des données (lead time, temps d’attente, temps d’exécution) et la mise en place de leviers techniques et organisationnels adaptés. À travers un cas client anonymisé issu d’un audit, cet article présente une approche concrète pour analyser la performance des pipelines CI/CD, objectiver les points de friction et identifier des actions mesurables permettant d’améliorer durablement la vélocité et l’alignement des équipes.
Performance CI/CD : piloter la vélocité des pipelines
Les pipelines CI/CD constituent aujourd’hui un pilier fondamental des chaînes de production logicielle. En automatisant l’intégration du code, les tests et le déploiement, ces outils permettent d’accélérer la livraison continue tout en maintenant un haut niveau de qualité. Cependant, dans de nombreuses organisations, ces pipelines deviennent progressivement sources de friction : temps d’exécution excessifs, files d’attente importantes ou échecs récurrents.
Une approche structurée d’analyse et d’optimisation des performances s’avère donc essentielle. Cet article présente, à travers un cas client anonymisé, une démarche pragmatique pour mesurer, analyser et améliorer la vélocité des pipelines, tant sur le plan technique qu’organisationnel.
Sommaire
- Définition du CI/CD et différence CI vs CD
- Contexte et problématique client
- Démarche d’audit et méthodologie
- Voix des équipes et constats qualitatifs
- Analyse quantitative et objectivation des performances
- Leviers d’amélioration et simulation des gains
- Enseignements clés et conclusion
- FAQ – CI/CD
1 Définition du CI/CD et différence CI vs CD
Le CI/CD constitue un processus de développement automatisé qui forme l’épine dorsale des opérations DevOps modernes. Cette approche garantit une automatisation et une surveillance continues tout au long du cycle de vie des applications, permettant aux équipes de livrer plus fréquemment avec un meilleur niveau de qualité.
Qu’est-ce que l’intégration continue ? (CI)
L’intégration continue (CI) désigne la pratique qui consiste à automatiser l’intégration des modifications de code dans un référentiel partagé de manière régulière. Chaque intégration déclenche une série de tests automatisés qui vérifient la qualité du code et identifient rapidement les problèmes potentiels. Cette méthode permet de détecter et corriger les bugs plus tôt dans le processus de développement, réduisant ainsi les coûts et les délais de correction.
Qu’est-ce que le déploiement continu ?
Le déploiement continu (CD) représente la phase finale du pipeline CI/CD. Il existe deux variantes principales :
- La livraison continue : automatise la publication du code validé dans un référentiel, mais conserve une validation manuelle avant le déploiement en production
- Le déploiement continu : automatise l’intégralité du processus jusqu’à la mise en production, sans intervention humaine
Cette approche permet aux équipes de déployer de nouvelles fonctionnalités rapidement et en toute confiance, accélérant ainsi le cycle de vie du développement logiciel.
CI vs CD : points clés
| Aspect | Intégration Continue (CI) | Déploiement Continu (CD) |
| Objectif principal | Vérifier que les modifications de code sont compatibles | Livrer le code validé aux utilisateurs |
| Processus | Compilation, tests unitaires et d’intégration | Déploiement automatisé vers divers environnements |
| Fréquence | Plusieurs fois par jour | Après validation de l’intégration continue |
| Résultat | Code testé et validé | de plusieurs fois par jour à moins d’une fois par an selon les organisations |
Cette combinaison CI/CD permet d’améliorer significativement la vélocité des équipes tout en maintenant la qualité dans le processus de déploiement.
2 Contexte et problématique client
Notre client, possède une organisation disposant de trois équipes de développement, il fait face à des défis de vélocité dans sa chaîne de production logicielle. Chaque équipe travaille sur des pipelines distincts au sein d’une architecture qui présente des signes d’inefficacité. Dans le cadre de sa stratégie d’amélioration continue, cette entreprise souhaite optimiser ses pratiques DevOps pour accroître sa productivité et réduire l’instabilité de ses déploiements.
Un audit complet (360°) a été commandé pour établir une trajectoire d’évolution claire sur les prochains mois, incluant l’analyse des outils, de l’architecture et des processus actuels. Notre intervention se concentre spécifiquement sur l’analyse de la vélocité des ressources (runners) utilisées par la chaîne DevOps, élément critique pour la compétitivité de l’organisation.
La demande client : « En tant que CTO, je souhaite auditer la chaîne CI/CD afin de gagner en vélocité. »
3 Démarche d’audit et méthodologie
Comment auditer la chaîne CI/CD de manière efficace ? Notre méthodologie repose sur une analyse bidimensionnelle permettant d’objectiver les performances réelles des pipelines et leur impact sur les équipes.
Approche d’intégration continue
Notre démarche s’articule autour de deux axes principaux d’investigation :
- La voix des développeurs pour comprendre les facteurs d’impact sur la satisfaction et identifier les sources de friction
- L’analyse quantitative des flux de travail CI/CD, mesurant précisément les temps d’exécution des pipelines et leur impact sur les temps d’attente
L’automatisation et l’optimisation des pipelines constituent des leviers essentiels pour améliorer la vélocité globale, mais nécessitent d’abord une mesure objective des performances actuelles.
Lead Time (temps total perçu par le développeur) = temps d’attente (queue time) + temps d’exécution (cycle time)
Pour un job : somme du temps d’attente et du temps d’exécution du job
Pour un pipeline : somme des Lead Time de ses jobs = somme des moyennes des temps d’attente + somme des moyennes des temps d’exécution
Nous analysons ces métriques en retirant les valeurs extrêmes pour obtenir une vision représentative de l’expérience utilisateur quotidienne. Certains graphiques présentent des moyennes sur 7 jours afin d’améliorer la lisibilité et d’identifier les tendances significatives.
4 Voix des équipes et constats qualitatifs
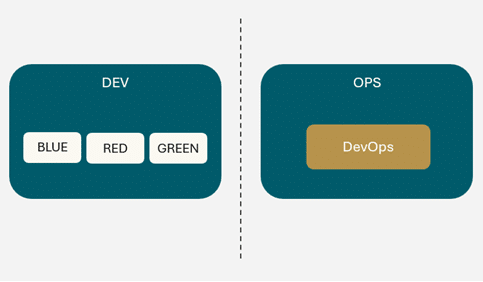
Représentation de la répartition des équipes du client
Afin d’accélérer les échanges et la synergie, les équipes de développement et d’exploitation doivent collaborer au plus près, idéalement dans la même « squad ». Ce modèle de collaboration favorise la fluidité des retours d’information. Chez ce client, les rôles DevOps sont intégrés aux équipes Ops, mais la collaboration reste insuffisante, impactant l’amélioration globale de la chaîne.
Les équipes de développement signalent des lenteurs sur la majorité des pipelines sans pouvoir les objectiver, faute de données consolidées. Quelques problèmes de stabilité sont également rapportés, bien que globalement maîtrisés.
Équipe 1 – BLUE Team
Récemment intégrée à l’environnement GitLab, cette équipe constate d’importantes lenteurs malgré des pipelines stables. Elle exprime une forte attente de réduction des temps d’exécution pour améliorer productivité et satisfaction.
Équipe 2 – RED Team
Globalement satisfaite des temps d’exécution, cette équipe observe néanmoins des lenteurs occasionnelles et souhaite une meilleure maîtrise de ces variations pour stabiliser l’expérience de ses développeurs et l’évolution de leur métier.
Équipe 3 – GREEN Team
Cette équipe QA utilise les pipelines pour l’automatisation des tests. Elle fait face à des lenteurs récurrentes dans l’exécution et exprime une attente forte quant à leur réduction pour optimiser ses bonnes pratiques de test.
Les équipes Ops/DevOps
Les équipes Ops et DevOps affichent une confiance élevée dans leurs runners et ont déjà engagé plusieurs actions d’amélioration. Toutefois, elles peinent à valoriser ces gains, l’image initiale perçue restant ancrée chez les développeurs.
Aparté – Notre accélérateur
Face aux difficultés rencontrées lors de nos missions (récupération des données, traitement, analyse fragmentée), nous avons développé un outil d’analyse de la chaîne DevOps. Il collecte les données via API et les consolide pour objectiver performances et recommandations.
Dans cet article, nous nous concentrons sur un exemple basé sur GitLab. Nous connectons notre accélérateur à l’environnement client pour mesurer les performances actuelles et les gains progressifs.
5 Analyse quantitative et objectivation des performances
Dans les graphiques présentés ci-dessous, le temps d’attente peut être traduit en Queue time et le temps d’exécution en Cycle time.
Tests de performance dans les pipelines : lecture des métriques
L’objectivation des performances par des tableaux de bord de surveillance permet d’identifier précisément les goulots d’étranglement dans la chaîne CI/CD. Notre analyse se concentre sur trois métriques essentielles : le Lead Time (temps total perçu), le temps d’exécution (Cycle Time) et le temps d’attente (Queue Time) par runner.
| Runner | Pipelines | Lead Time moyen | % Temps d’attente | Taux de succès |
| BLUE | 1 622 | 2 422 s (40 min) | 54% | 90,8% |
| RED 1 | ~3 000 | 1 020 s (17 min) | 7,7% | – |
| RED 2 | ~750 | 720 s (12 min) | 0,6% | – |
| GREEN 1,2,8 | ~3 000 chacun | 100 s (1 min 40) | ~4% | – |
| GREEN 3 | 3 500 | 150 s (2 min 30) | 10,7% | – |
Vélocité des pipelines par runner
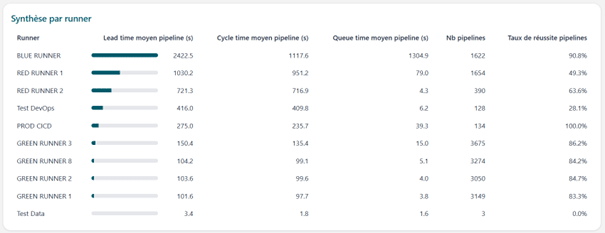
Lead time, temps de traitement et queue moyenne par runner pour les pipelines sur 9 mois
Team BLUE – Runner BLUE
BLUE est le runner où les pipelines sont les plus chronophages. Un développeur utilisant ce runner doit patienter en moyenne 40 minutes pour l’exécution complète d’un pipeline, dont 54% correspondent uniquement au temps d’attente avant l’exécution réelle.
L’analyse de distribution révèle que plus de 37% des pipelines dépassent 40 minutes d’exécution totale, tandis que moins de 10% s’exécutent en moins de 15 minutes. Cette répartition confirme le caractère systémique des lenteurs observées.
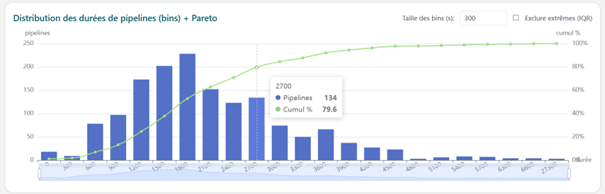
Nombre de pipelines selon leur durée (par paquet de durée de 300 secondes)
La moyenne glissante sur 7 jours montre une dégradation progressive du Lead Time, passant d’environ 1 400 secondes fin 2024 à 2 400 secondes fin août 2025. Cette augmentation de 71% se décompose en une hausse de 70% du temps d’exécution (1 000 à 1 700 secondes) et de 40% du temps d’attente (500 à 700 secondes).
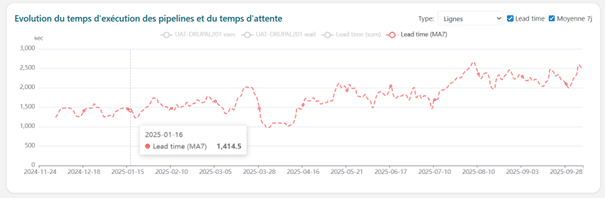
Évolution de la moyenne sur 7 jours des Lead Time des pipelines
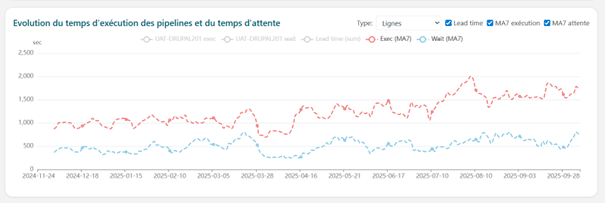
Team RED – Runner RED 1 et Runner RED 2
Les runners RED 1 et RED 2 présentent respectivement des durées moyennes d’exécution de 17 et 12 minutes. Pour RED 1, seulement 7,7% du temps total correspond à de l’attente, la majeure partie du Lead Time provenant du temps d’exécution.
Un écart significatif apparaît entre ces deux runners : le temps d’attente moyen de RED 1 est vingt fois supérieur à celui de RED 2 (79 secondes contre 4 secondes) pour un volume de pipelines quatre fois plus important.
Team GREEN – Runner GREEN 1, 2, 3 et 8
Les runners GREEN 1, 2 et 8 affichent un temps moyen d’exécution de 100 secondes, avec environ 3 000 pipelines chacun sur la période étudiée.
GREEN 3 se démarque avec près de 3 500 pipelines et un temps moyen de 150 secondes, soit 50% de plus que les autres runners de la même famille. Son temps d’attente est également 3 à 4 fois supérieur (16 secondes contre environ 4 secondes), suggérant un déséquilibre dans la répartition des charges.
6 Leviers d’amélioration et simulation des gains
L’optimisation d’une chaîne CI/CD nécessite une approche structurée combinant leviers organisationnels et techniques. Cette démarche permet d’obtenir des gains mesurables en termes de vélocité et d’efficacité du processus de déploiement.
Leviers organisationnels d’amélioration
- Définition et suivi de SLA/SLO : stabilise les performances, aligne les équipes et priorise les actions
- Objectifs d’amélioration continue : dynamise l’optimisation, mesure les gains réels et anticipe les risques
- Partage des données : favorise la transparence, l’appropriation des améliorations et réduit les ressentis non objectivés
Leviers techniques et outils d’optimisation
Les leviers techniques d’optimisation incluent la conteneurisation des runners (meilleure maîtrise lors des pics de charge), la parallélisation des jobs, l’ajout de runners supplémentaires (réduit le queue time), la réallocation des pipelines et l’optimisation des jobs lents.
Pour améliorer la performance de vos pipelines, plusieurs outils CI/CD peuvent être déployés selon votre environnement :
- GitLab Runners : idéal pour les environnements GitLab avec possibilité de conteneurisation
- Jenkins : solution hautement personnalisable pour environnements complexes
- GitHub Actions : intégration native pour les projets hébergés sur GitHub
- CircleCI : offre une mise à l’échelle automatique des ressources
- Azure DevOps : solution complète pour l’écosystème Microsoft
- Spacelift : spécialisé pour l’infrastructure as code (IaC)
Focus sur les SLA
Afin de réaliser un suivi professionnel et managérial, une bonne pratique est de définir des SLA, les suivre et prendre action lorsqu’elles sont dépassées.
Exemple de SLA pour un type de pipeline :
- Le taux de succès des pipelines est supérieur à 98%
- Le temps de traitement est inférieur à 150 secondes dans 98% des cas
- Le temps d’attente est inférieur à 10 secondes dans 85% des cas
Dans le cas présent, nous fixons les contrats suivants :
- BLUE RUNNER – temps d’attente et temps de traitement très longs ne correspondant pas aux attentes. Objectif : Lead Time ≤ 30 minutes en moyenne au lieu de 44 minutes actuellement
- RED 1 – temps d’attente et temps traitement longs. Objectif : Lead Time ≤ 10 minutes en moyenne au lieu de 17 minutes actuellement
- RED 2 – temps d’attente très bon et temps traitement longs. Objectif : Lead Time ≤ 10 minutes en moyenne au lieu de 13 minutes actuellement
- GREEN 3 – Lead Time plus lent que les autres. Objectif : Lead Time ≤ 2 minutes en moyenne au lieu de 2 minutes 30 actuellement
Simulation de l’ajout de runners pour BLUE
En reprenant l’historique des données, nous pouvons obtenir une estimation des gains en termes de temps d’attente pour le runner BLUE via l’ajout de runners.
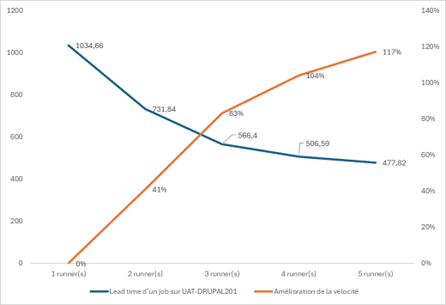
| 1 runner(s) | 2 runner(s) | 3 runner(s) | 4 runner(s) | 5 runner(s) | |
| Lead time d’un job sur BLUE | 1034s – 17 min | 732s – 12 min | 566s – 9,5 min | 507s – 8,5 min | 478s – 8 min |
| Amélioration de la vélocité | 0% | 41% | 83% | 104% | 117% |
Sur le graphique, le point d’inflexion optimal se situe à 3 runners, permettant 83% d’amélioration du Lead Time. BLUE peut réduire son temps moyen d’attente de 540 secondes (41%) avec 3 runners, pour passer d’un Lead Time du pipeline de 44 minutes à 36,5 minutes en moyenne.
Avec 2 runners, le Lead Time moyen d’un pipeline passerait à 39 minutes (soit 5 minutes de gain). En augmentant les capacités des runners, on peut également espérer gagner en durée sur les jobs longs.
Objectivation des gains réalisés
Il est possible d’identifier un gain tangible suite aux actions menées en prenant en compte le temps d’attente éliminé.
Exemple avec BLUE, qui a environ 2 100 pipelines par an en moyenne et un gain de temps d’exécution de 8,5 minutes grâce à l’ajout de 2 runners. Nous prenons pour hypothèse une journée de travail de 7,5h équivalent à 1 j.h.
Cela crée un gain d’environ 40 j.h. équivalent en temps d’attente par an, en plus de la frustration éliminée. Cela est bien évidemment à comparer avec le coût de l’ajout des runners.
Recommandations par équipe
BLUE
- Ajouter 2 runners pour réduire le temps d’attente moyen de plus de 5 minutes par job
- Augmenter la puissance des machines virtuelles afin de réduire les temps d’exécution
- Travailler les jobs spécifiques les plus lents afin de réduire leur impact
GREEN – Réallocation des tags
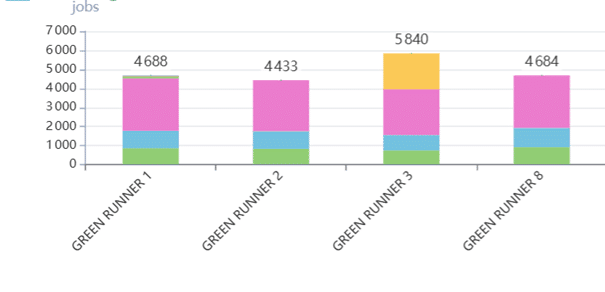
Nombre de job selon tag_list par runner
GREEN 3
- Lisser la charge en réallouant des tags aux autres runners GREEN – cela augmentera de manière minimale le temps d’exécution et d’attente des autres runners GREEN, tout en déchargeant fortement le runner GREEN 3
- S’assurer que les développeurs comprennent le ressenti de lenteurs et les raisons de ces variations
RED – Optimisation des jobs lents et augmentation de la puissance
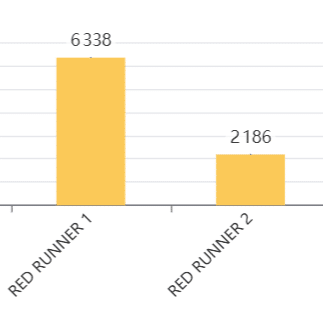
RED 1 & 2
- Le temps d’exécution est le plus impactant. Le temps d’attente du 1 peut être réduit en réallouant plus de pipelines au 2
- Augmenter la puissance des machines virtuelles afin de réduire le temps d’exécution (scaling vertical)
- Optimiser les jobs, ajouter du cache pour certains artefacts, faire des phases de pré-analyse en local par les développeurs
7 Enseignements clés et conclusion
Dans cet article, nous avons objectivé l’impact des performances CI/CD sur la vélocité des équipes DevOps. Notre démarche structurée, interviews qualitatives, mesures quantitatives via notre accélérateur, puis simulations de gains, a permis d’établir une stratégie d’optimisation basée sur des données concrètes plutôt que sur des ressentis.
La réduction des temps d’attente constitue un levier majeur de création de valeur, transformant directement la frustration des développeurs en productivité mesurable. Notre intervention dépasse l’optimisation technique pour instaurer un véritable système de pilotage de la chaîne de production CI/CD, alignant les équipes autour d’objectifs communs.
Les échanges entre équipes s’appuient désormais sur des données objectivées, offrant une visibilité transverse sur les performances et permettant d’identifier proactivement les ralentissements avant qu’ils n’impactent la productivité. Cette approche améliore non seulement la vélocité opérationnelle, mais renforce également la collaboration entre les équipes de développement et d’exploitation.
Notre valeur ajoutée repose sur notre expérience, notre pragmatisme et notre accélérateur qui optimise la qualité de nos interventions, à distance comme sur site. Vous souhaitez en savoir plus ? Contactez-nous.
8 FAQ – CI/CD
Qu’est-ce qu’un pipeline d’intégration continue (CI/CD) ?
Un pipeline CI/CD est une chaîne automatisée qui orchestre l’intégration du code, les tests et le déploiement des applications. Il constitue l’épine dorsale des pratiques DevOps modernes en permettant aux équipes de fusionner régulièrement leurs modifications dans un dépôt central tout en garantissant la qualité via des tests automatisés.
Qu’est-ce que le principe CI/CD ?
Le principe CI/CD repose sur l’automatisation et la surveillance continues tout au long du cycle de vie des applications. Il comble l’écart entre développement et opérations en créant un processus de livraison logicielle simplifié qui favorise les déploiements fréquents, la détection précoce des problèmes et l’amélioration constante de la vélocité des équipes.
Quelle est la différence entre CI et CD ?
La CI (Intégration Continue) automatise l’intégration des modifications de code dans un référentiel partagé avec vérification par tests. Le CD a deux significations : la Livraison Continue qui prépare le code pour déploiement manuel, et le Déploiement Continu qui publie automatiquement les changements validés directement en production sans intervention humaine.
Quels sont les meilleurs outils de CI/CD ?
Actuellement, les outils CI/CD les plus performants incluent GitLab CI pour son environnement unifié, GitHub Actions pour son intégration native avec les dépôts, Jenkins pour sa flexibilité, et Argo CD pour les déploiements Kubernetes. Les solutions modernes privilégient l’automatisation pilotée par l’IA et les flux de travail GitOps pour optimiser la vélocité des pipelines.
Comment un pipeline CI/CD améliore-t-il la productivité ?
Un pipeline CI/CD améliore la productivité en automatisant les tâches répétitives et en réduisant les délais d’attente entre les phases de développement. Il permet aux équipes de se concentrer sur la création de valeur métier plutôt que sur des opérations manuelles, tout en favorisant la détection précoce des bugs et la réduction des temps de déploiement.
Comment surveiller la performance d’un pipeline CI/CD ?
La surveillance efficace d’un pipeline CI/CD s’appuie sur le suivi de métriques clés comme le temps d’exécution, le temps d’attente, la fréquence de déploiement et le taux d’échec. L’établissement de SLA (contrats de niveau de service) et l’utilisation de tableaux de bord permettent d’objectiver les performances, d’identifier les goulots d’étranglement et d’améliorer continuellement la vélocité.

Votre CI/CD est-elle un accélérateur… ou un frein à votre productivité ?
Navigacom, cabinet de conseil du groupe Meritis, accompagne les équipes IT dans l’optimisation de la performance CI/CD pour des déploiements plus rapides, plus fiables et plus sécurisés.
Audit, recommandations, accompagnement opérationnel : nos experts interviennent sur toute la chaîne pour maximiser l’impact business de votre delivery logiciel.
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.



Pas encore de commentaires