
Et si nos prochains dirigeants étaient élus par un bot ? Si on n’en est pas encore là, l’influence des technologies dans les élections est de plus en plus prégnante, big data, IA et machine learning en tête.
Mais jusqu’où leur influence peut-elle aller justement ?

Pas le temps de lire l’article ?
Retrouvez le format « Draw my expertise » pour tout savoir sur le pouvoir du big data dans les élections présidentielles en 6 min !
Depuis quelques années déjà, le big data occupe une place de choix dans les stratégies d’entreprise… mais aussi électorales. Et les élections américaines de cette dernière décennie l’illustrent parfaitement, à commencer par celle qui a vu Donald Trump, pourtant outsider face à Hillary Clinton, l’emporter. Dans cet article, nous allons expliquer pourquoi et démontrer l’importance des données dans les campagnes électorales.
Le duel entre Barack Obama et Mitt Romney lors des élections présidentielles américaine de 20212 s’est terminé par un résultat très clair, une large victoire pour Barack Obama. Ce résultat n’est pas seulement dû aux compétences rhétoriques du candidat ou encore aux programmes politiques des candidats adverses, le big data a joué un rôle majeur dans la victoire de l’ancien président américain.
Dans un monde de plus en plus digital, la data analysis ou analyse des données en français représente un avantage majeur dont disposent la plupart des organisations et des mouvements politiques pour planifier leurs stratégies électorales. Le big data constitue ainsi un puissant outil qui est utilisé à la fois pour exploiter et récolter des données dans le but de mobiliser et recueillir le plus grand nombre d’électeurs possible.
Après Obama, de nombreux hommes politiques ont également utilisé le big data pour optimiser leurs campagnes électorales. Celle de Donald J. Trump en est le parfait exemple. Sa campagne a été de nombreuses fois qualifiées de « machine à données » alimentée par l’intelligence artificielle. Grâce à cette stratégie, Donald J. Trump a réuni et séduit un grand nombre d’électeurs du camp adverse, démontrant ainsi le pouvoir des données et des systèmes d’analyse.
Aujourd’hui, les données changent la façon dont les politiciens mènent les campagnes électorales. Pendant des décennies, les sondages ont été la principale source de données, guidant les politiciens dans la prise de décisions avant le début de chaque campagne électorale.
Le big data et le machine learning
De nos jours, les données sont si importantes qu’elles ont dépassé le pétrole en tant que ressource la plus précieuse au monde. Elles deviennent la base sur laquelle tout repose. Durant leurs campagnes, les partis politiques apprennent à comprendre et à traiter les données aux niveaux régional, national et international, non pas parce qu’elles le veulent, mais parce qu’elles le doivent. C’est à partir de ces données que tout se crée.
Pour comprendre comment l’analyse et le traitement des données ont changé la politique, il est important d’abord, de bien comprendre ce que représente le big data et comment son interaction avec le machine learning peut avoir un impact sur les décisions prises par les mouvements politiques.
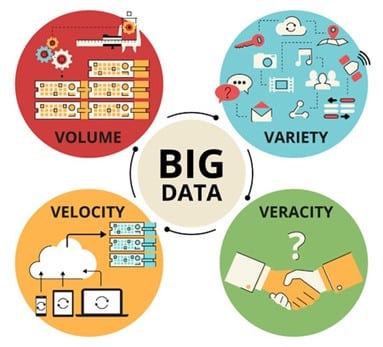
Le principe des 4 V
Selon Doug Laney, analyste au sein du cabinet Gartner, le big data peut se définir selon le principe des 4V :
- Volume : il s’agit de très grandes quantités de données que les logiciels de traitement des données classiques sont incapables de traiter ;
- Variété : le big data collecte, traite et analyse des données distinctes comme par exemple du texte, des images ou encore des vidéos. Ces données ne sont pas toujours structurées. Ainsi, les programmes big data facilitent la catégorisation des données et l’analyse des informations reçues ;
- Vélocité : il s’agit de la vitesse à laquelle ces quantités de données sont générées, collectées et analysées ;
- Véracité : ce dernier point fait référence à la qualité des données, à leur précision ainsi qu’à leur fiabilité.
De son côté, le machine learning peut se définir comme étant une technique de programmation informatique qui utilise des probabilités statistiques pour donner aux ordinateurs la capacité d’apprendre par eux-mêmes sans programmation explicite.
Quel est alors le lien entre ces deux notions qui font partie intégrante de notre quotidien ?
Il faut savoir que sans le big data, le machine learning et l’intelligence artificielle (IA) n’auraient pas vu le jour. Pour la simple et bonne raison que les données sont encore une fois la base de tout. Elles représentent le support nécessaire pour permettre à l’IA d’apprendre, de comprendre et de raisonner comme l’humain. Plus un programme de machine learning stocke des données, plus il apprend et plus il devient précis.
Le système de suggestion de Netflix est un excellent cas d’école pour comprendre à quel point le big data et le machine learning se complètent pour améliorer l’expérience client. Les algorithmes développés par la multinationale sont capables de traiter une très grande quantité de données, par exemple :
- Le genre d’émissions et de films que vous avez regardés ;
- Les acteurs et les réalisateurs que vous avez regardés ;
- Les émissions et les films que les personnes ayant des goûts similaires aux vôtres regardent.
Ces données sont stockées puis analysées pour que Netflix puisse vous suggérer des émissions et des films à regarder en fonction de vos goûts personnels.
À première vue, vous pourriez penser que cela n’a rien à voir avec la politique, mais la même idée s’applique quel que soit le sujet, à partir du moment où des données sont utilisées. Imaginez par exemple qu’une mairie ait accès à des données de trafic en temps réel : celles-ci peuvent être analysées à l’aide d’algorithmes de machine learning et ainsi fournir des suggestions en temps réel quant au meilleur moment pour fermer des routes ou modifier des itinéraires de circulation.
Les données, nouveau trésor des partis politiques
Les données sont la connaissance, la connaissance est le pouvoir, et c’est l’une des raisons pour lesquelles les données ont changé notre façon de penser et de faire de la politique. Pour comprendre à quel point les données sont importantes, en particulier lorsqu’il s’agit d’élections présidentielles, parlons du scandale de Cambridge Analytica. Il s’agit d’une société britannique spécialisée dans le profilage psychographique. Leur objectif est de récupérer le maximum de données sur les réseaux sociaux afin de tenter de prédire les comportements électoraux.
En 2015, le chercheur Aleksandr Kogan avait utilisé l’application This is your digital life pour dresser un portrait psychologique d’un utilisateur de Facebook après avoir analysé ses données personnelles à partir d’un questionnaire.
Cependant, l’application collectait non seulement les données personnelles de la personne effectuant le test mais aussi l’ensemble de ses amis Facebook. Donc, supposons que seules 270 000 personnes ont participé au test, avec un tel système, les données de plus de 50 millions de personnes ont pu également être collectées.
Aleksandr Kogan a ensuite envoyé la totalité de ces informations à Cambridge Analytica pour que l’entreprise les analyse et peaufine son expertise en marketing politique. Par conséquent, elle n’a pas respecté les conditions d’utilisation du réseau social.
Les données ou leur interprétation peuvent favoriser ou empêcher la montée d’un candidat à la présidence. Si celles-ci peuvent permettre d’élire un candidat, elles peuvent également l’aider à faire de meilleurs choix. Dans le paragraphe précédent, nous avons illustré l’exemple du machine learning pour fluidifier le trafic et améliorer la sécurité routière. Imaginez maintenant ce concept appliqué dans le domaine politique.
Par exemple, les analyses réalisées à partir des données collectées peuvent être utilisées par le ministre de la Santé pour optimiser la manière d’allouer les fonds. Elles peuvent être utilisées par les ministres des Affaires étrangères pour simuler des accords commerciaux complexes ou pour prévoir les effets à long terme d’un environnement économique incertain, à l’image de la décision du Royaume-Uni de quitter l’Union européenne. Elles peuvent également être utilisées pour alerter les dirigeants de la montée d’une potentielle épidémie ou d’autres phénomènes naturels à l’aide de données démographiques.
À partir de ces informations, nous pouvons nous poser plusieurs questions. La première concerne les différentes parties qui interviennent dans le processus de décision.
Qui utilise les données issues des campagnes présidentielles ?
Il s’agit principalement des spécialistes en matière de traitement des données. Travaillant souvent pour une entreprise externe ou engagés exclusivement pour leur expertise en data, ces spécialistes ont fait l’objet d’une grande couverture lors des campagnes électorales.
Parmi elles, nous retrouvons bien entendu l’entreprise Cambridge Analytica ou encore Blue State Digital et eXplain. Ces organismes sont spécialisés dans la publication stratégique grâce à l’analyse et à nl’exploration des données. Elles ont pour mission principale d’utiliser ces informations en vue de changer le comportement des individus.
Après avoir examiné qui utilise les données issues des campagnes, il est important de se demander quelles sont les différentes sources des données.
Quelles sont les différentes sources des données utilisées durant les campagnes présidentielles ?
Nous avons vu plus haut que pour réunir le plus grand nombre de votes, les politiques sollicitent de plus en plus de sociétés privées, spécialistes dans la récolte, le traitement et l’analyse de données.
En rassemblant les résultats des élections précédentes, les données de l’Insee et de Pôle Emploi, les listes électorales et même les données commerciales, ces entreprises ciblent les indécis pour tenter de les convaincre de glisser le « bon » bulletin dans l’urne et faire ainsi basculer la campagne.
Pour cibler ces « profils types », les équipes de campagne ont recours à des « data brokers ». Ce sont des entreprises qui achètent les données des consommateurs de toutes sortes et les revendent. Ces données leur permettent de connaître de manière très précise le profil de l’électeur, et surtout de le géolocaliser. Avoir en sa possession ce type d’information est une arme redoutable pour optimiser et réduire les coûts passés sur le terrain, en ciblant le territoire de campagne et en adaptant les messages et les actions à chaque quartier.
Comment le big date influence-t-il les votes des électeurs ?
Le fait de disposer de ces informations procure un avantage considérable aux partis politiques. À partir de là, nous pouvons nous demander si les géants du web, notamment Google, ne pourraient pas influer sur les résultats électoraux. Cette question a été posée et étudiée par de nombreux chercheurs.
Il faut bien sûr prendre en compte le poids actuel du moteur de recherche aux États-Unis (70%) et en Europe (de l’ordre de 90%). Ainsi, Google pourrait-il manipuler les résultats de son classement pour favoriser tel ou tel candidat ? Selon les chercheurs de la revue américaine Proceedings of the National Academy of Sciences, internet n’est pas le seul moyen d’information des électeurs indécis. Cependant, il n’empêche qu’en se fiant aux seuls résultats procurés par les algorithmes, la possibilité est bien réelle que ces nouveaux outils numériques puissent influencer, de manière directe ou indirecte, le choix des électeurs.
Comment les mouvements politiques utilisent les données ?
Dans cette partie, nous allons voir ce que les campagnes savent à partir des données récoltées sur les électeurs et comment elles s’en servent pour élaborer leurs stratégies.
L’objectif principal du stockage et du traitement des données est de mieux cibler les électeurs, mieux les atteindre et comprendre comment ces derniers peuvent réagir à certains messages. Pour cela, certaines étapes sont nécessaires :
Utilisation de la base de données nationale
Comme mentionné précédemment, les informations utilisées durant les campagnes présidentielles sont rassemblées à partir de nombreux fichiers, auxquels s’ajoutent des données achetées à des entreprises spécialisées et régulièrement mises à jour :
- Création de la base de données nationale
Les entreprises spécialisées dans la récolte de données combinent les fichiers des électeurs présents dans les différentes villes et municipalités pour créer une base de données nationale. Ils comprennent des informations classiques telles que les noms et prénoms, l’affiliation à un parti et les adresses.
- Nettoyage des données
Certaines données, comme l’adresse du domicile ou les coordonnées, peuvent être périmées ou manquantes. Les entreprises les mettent donc à jour quotidiennement.
- Création du profil de l’électeur
Pour mieux comprendre les électeurs potentiels, les entreprises ajoutent des données complémentaires comme le comportement d’achat et de consommation.
- Intégration des informations
Les données récoltées et transformées sont ensuite intégrées dans différents systèmes et/ou applications, afin que les partis puissent les analyser.
- Actualisation des données
Les données sont régulièrement mises à jour avec de nouvelles informations durant la période électorale.
Superposition de données
Les entreprises spécialisées en data peuvent compléter les informations précédemment citées avec d’autres beaucoup plus personnelles. Nous pouvons retrouver le patrimoine immobilier de l’électeur, les revenus estimés ou encore la religion.
Ces informations personnelles sont souvent récupérées via :
- Les adresses emails, grâce notamment aux dons, aux enquêtes et aux inscriptions réalisées sur différentes plateformes en ligne.
- Le numéro téléphone, lorsque le consommateur achète un produit sur un site internet.
- Les identifiants des appareils, grâce aux cookies, et adresses IP.
- Le parcours de l’utilisateur, comme la profession, l’intitulé du poste et le niveau d’études, qui peuvent être extraits de LinkedIn.
- Les préférences du consommateur : l’historique des achats peut en effet être utilisé pour prédire les préférences des consommateurs, par exemple si ces derniers possèdent un animal de compagnie ou une voiture électrique.
Toutes ces données sont des variables à intégrer dans le modèle que nous appelons « modèle de prédictions ».
Modèle de prédiction
Les modèles de prédiction sont très utiles et appréciés des mouvements politiques car ils leur permettent de faire de meilleurs choix et d’élaborer leurs stratégies en conséquence. De plus, ces modèles permettent de mieux cibler les électeurs en prédisant la probabilité que ces personnes :
- Soutiennent un candidat particulier ;
- Expriment une appartenance à une religion ;
- Possèdent une assurance médicale ;
- Sont pour ou contre un sujet sensible, comme le nucléaire, la pass sanitaire… ;
- Changent de parti politique.
À partir de ces informations, un candidat peut notamment mettre l’accent sur sa politique en matière de soin en se focalisant sur les personnes qui ont voté pour le parti adverse par le passé, mais qui s’inquiètent des coûts de santé dans les années à venir.
Comment les modèles de prédictions sont-ils construits ?
Ces modèles doivent suivre un certain nombre d’étapes pour être pertinents.
- Étape 1 : effectuer le choix de l’échantillon
Les entreprises spécialisées en data choisissent un échantillon donné à partir de leurs bases de données. Cet échantillon est composé de plusieurs milliers de personnes.
- Étape 2 : réaliser des enquêtes
Ces entreprises réalisent des enquêtes pour connaître l’opinion des citoyens et des citoyennes sur des questions précises et des sujets sensibles, et ajoutent leurs réponses sous forme de scores à leur ensemble de données.
Ensuite, l’échantillon interrogé est divisé en deux groupes : le groupe « apprentissage », et le groupe « de test » ou « de validation ».
- Étape 3 : construire un modèle
Les données du groupe « apprentissage » sont introduites dans l’algorithme pour construire un modèle qui prédit la probabilité d’une personne à avoir certaines opinions. La prédiction est représentée par un score numérique.
- Étape 4 : tester et répéter
Les spécialistes vont évaluer la cohérence du modèle en lui fournissant de nouvelles données de test et en comparant les scores prédits entre les différentes enquêtes.
Ils répètent ce processus X fois, en alimentant le modèle de nouvelles informations tout au long de la campagne. Les résultats issus de chaque test deviennent un outil d’aide à la décision.
Les modèles ne suffisent pas
Tout au long des campagnes présidentielles, les candidats rassemblent bon nombre de données, plus précieuses les unes que les autres. Les partis politiques utilisent même les numéros de téléphone des personnes pour envoyer un grand nombre de messages afin de les inciter à voter.
Cependant, les informations recueillies ou même achetées n’ont pas le même poids que lorsque les candidats se rendent à un rassemblement ou parlent directement aux citoyens et aux citoyennes. C’est pourquoi, quel que soit le modèle, les rassemblements et la communication avec la population restent plus efficaces que n’importe quelle modélisation de données.
Conclusion
Les campagnes électorales basées sur les données ont commencé à se développer à partir de l’élection présidentielle américaine de Barack Obama en 2012. Aujourd’hui, l’utilisation du big data à l’aide du machine learning permet aux partis politiques d’analyser de grandes quantités de données et d’élaborer de meilleures stratégies afin d’attirer le plus grand nombre d’électeurs possible et, par conséquent, de gagner l’élection présidentielle.
Sources :
- https://www.lebigdata.fr/definition-big-data
- https://ia-data-analytics.fr/machine-learning/
- https://www.upgrad.com/blog/how-netflix-uses-machine-learning/
- https://www.newscientist.com/article/mg24833050-300-how-big-data-helped-elect-president-kennedy-during-the-cold-war/
- https://alphalyr.fr/lexploitation-des-donnees-personnelles-au-coeur-des-elections-presidentielles/
- https://www.cairn.info/revue-politiques-de-communication-2016-1-page-137.htm
- https://theconversation.com/data-driven-elections-and-the-key-questions-about-voter-surveillance-121164
- https://www.cio.com/article/221882/how-big-data-has-changed-politics.html
- https://scholar.harvard.edu/files/todd_rogers/files/political_campaigns_and_big_data_0.pdf
- https://policyreview.info/data-driven-elections
- https://www.lebigdata.fr/machine-learning-et-big-data#Machine_Learning_et_big_data_pourquoi_le_Machine_Learning_nest_rien_sans_big_data
- https://policyreview.info/articles/analysis/data-driven-political-campaigns-practice-understanding-and-regulating-diverse-data
- https://theconversation.com/comment-lusage-de-vos-donnees-peut-influencer-les-elections-140001
- https://www.francetvpro.fr/contenu-de-presse/28175745
- https://www.lejdd.fr/Politique/data-electorale-comment-les-candidats-ciblent-leurs-electeurs-4080757
- https://www.nextinpact.com/article/45279/datas-pourquoi-il-ny-a-pas-encore-campagne-electorale-2-0-en-france
- https://searchbusinessanalytics.techtarget.com/feature/Election-data-revolutionizes-the-running-of-campaigns
- https://www.cbsnews.com/news/election-campaigns-big-data-analytics/
- https://journals.openedition.org/communicationorganisation/6724
- https://www.routledge.com/big-data-Political-Campaigning-and-the-Law-Democracy-and-Privacy-in-the/Witzleb-Paterson-Richardson/p/book/9781032082554
- https://datascience.foundation/sciencewhitepaper/big-data-analytics-and-predicting-election-results
- https://seleritysas.com/blog/2020/10/22/big-data-analytics-and-its-role-in-elections/
- https://www.btelligent.com/en/blog/predictive-analytics-and-the-presidential-election/
- https://fr.wikipedia.org/wiki/Scandale_Facebook-Cambridge_Analytica
- https://www.lemonde.fr/pixels/article/2018/03/22/ce-qu-il-faut-savoir-sur-cambridge-analytica-la-societe-au-c-ur-du-scandale-facebook_5274804_4408996.html
- https://ici.radio-canada.ca/nouvelle/1090159/facebook-cambridge-analytica-donnees-personnelles-election-politique-campagne-marketing-politique
- https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3511428
- https://www.talend.com/fr/resources/what-is-machine-learning/
- https://www.latribune.fr/opinions/tribunes/de-l-influence-du-big-data-sur-les-elections-americaines-553346.html


Pas encore de commentaires