
Si vous développez en Spark, vous avez sûrement déjà entendu parler des partitions. Ce n’est pas le cas ? Et pourtant, il est très probable que vous ayez eu à faire à elles, sans le savoir, lors d’une phase de debug, de l’écriture d’un algorithme ou de l’analyse d’un traitement sur la Web UI Spark. Découvrez ce concept et surtout pourquoi il est si important de l’avoir à l’esprit lorsque l’on fait “du Spark”.
Une partition, qu’est ce que c’est ?
Pour rappel, un RDD représente de la donnée “distribuée”, immuable, pouvant être traitée de façon parallèle. Une partition représente tout simplement une partie de la donnée d’un RDD.
Prenons un exemple :
val rdd = session.sparkContext.parallelize(0 to 9) print(rdd.getNumPartitions) // 4
Ici, dans mon cas, mon RDD est composé de 4 partitions par défaut.
Remarque:
Ce comportement vient du paramètre spark.default.parallelism qui définit qu’en mode local (que j’utilise pour écrire cet article) le nombre de partitions par défaut d’un RDD est égal au nombre de cœurs que possède la machine. Si j’avais été en mode cluster, ce RDD aurait eu un nombre de partitions égal au total des cores disponibles sur les executors du cluster.
On pourrait donc imaginer que les données sont réparties de la manière suivante (ce qui est d’ailleurs le cas après inspection des données sur ma machine) :

À savoir que chacune des partitions sera à la charge d’un executor lors des traitements.
Par exemple, en local, le driver qui sera aussi l’unique executor, aura à sa charge l’intégralité des partitions de mon RDD. Si j’étais en mode cluster, avec 4 executors, chacun aurait traité une partition.
Une des choses les plus importantes à retenir, c’est qu’il y a une correspondance exacte entre le nombre de partitions d’un RDD et le nombre de tasks qui seront créées lors de l’exécution des traitements sur vos données.
Par exemple :
val rdd = session.sparkContext.parallelize(0 to 9) // [0,1,2,3,4,5,6,7,8,9] rdd.map(_*2).sum //90
Ce code générera 4 tasks correspondantes à la fonction lambda (x2).
On peut d’ailleurs s’en assurer en allant voir la Web UI de Spark :

On a donc eu 4 tâches s’exécutant en parallèle et s’occupant chacune d’une partition (qui je le rappelle, correspondent aux données du RDD).
Mais que se serait-il passé si j’avais eu une dizaine de partitions au lieu de 4 ? Ou bien une seule ?
Ni trop, ni trop peu
Afin de comprendre l’importance que revêt ce nombre de partition, il faut comprendre comment fonctionnent les tasks.
Dans l’exemple vu plus haut, voilà ce qu’il s’est passé :
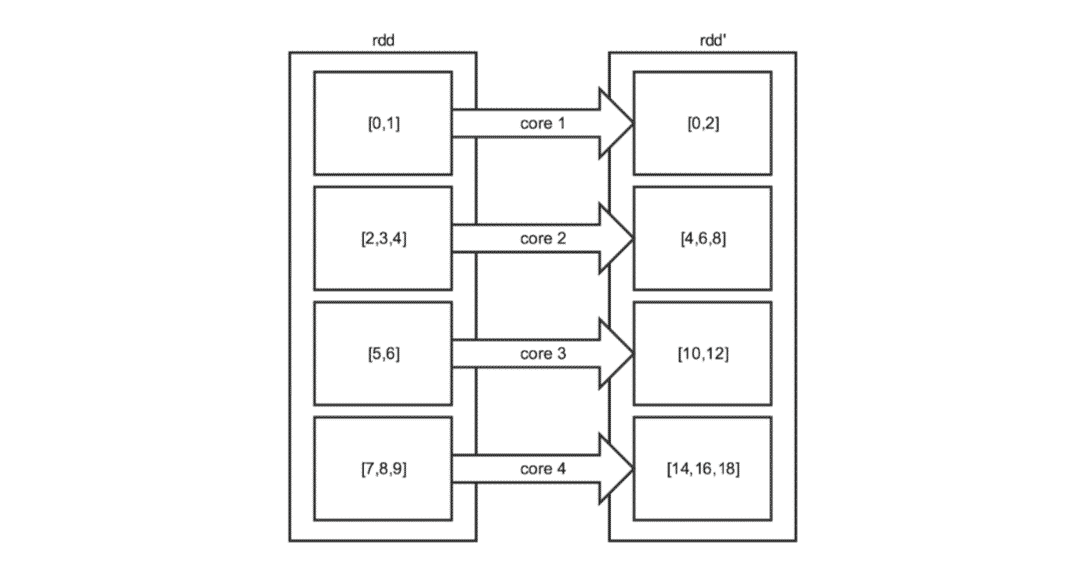
On peut s’apercevoir que, ayant 4 partitions et 4 cœurs, le traitement s’est correctement réparti, tandis que si l’on avait abaissé le nombre de partitions, par exemple à 1, le résultat aurait été :
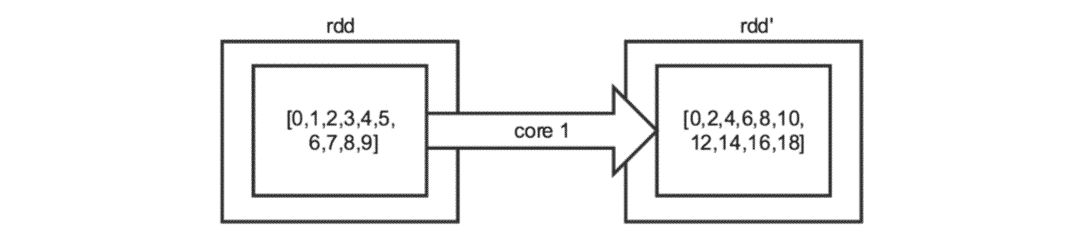
Ici, le nombre de partitions est bien loin d’être optimal car dans cette configuration, nous n’utilisons qu’un core sur les 4 disponibles. De plus, l’unique core utilisé doit traiter l’intégralité des données, ce qui pourrait amener à des problèmes de mémoire.
On pourrait donc se dire que plus il y a de partitions et plus le traitement serait efficace car parallélisé. Ce n’est que partiellement vrai.
Imaginons maintenant ce qui se pourrait se passer si nous avions 12 partitions (pour garder un multiple de nos cores) :
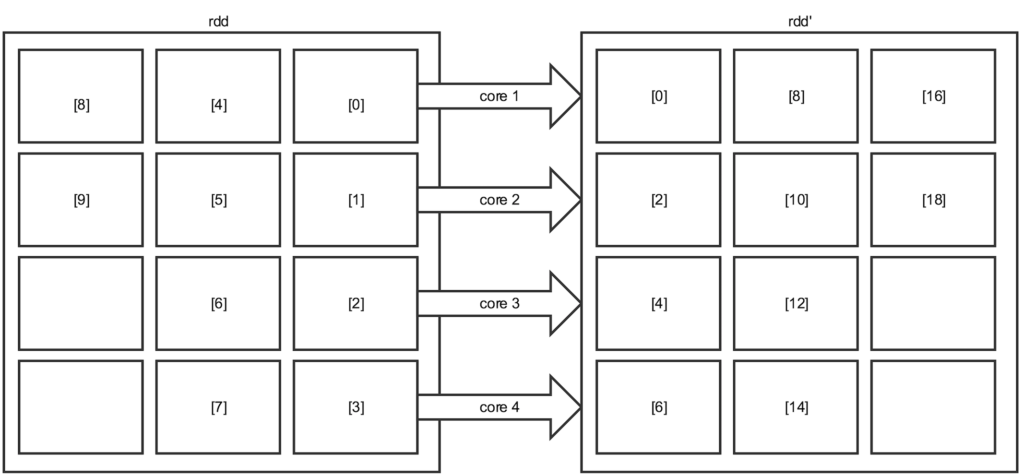
Avec 12 partitions, nous aurions une utilisation optimale de nos ressources. En effet, à partir de 4 partitions, on peut considérer que tous les cores sont utilisés.
Néanmoins, il faut garder à l’esprit qu’un core n’exécute qu’une task à la fois. Ici, nous n’avons pas réellement gagné en parallélisme. En revanche, nous avons gagné en overhead du fait du nombre de tasks plus élevé (gestion de ces tasks, sérialisation/désérialisation, etc.), et nous avons également des partitions vides, qui prennent aussi du temps de traitement !
Remarque :
Bien qu’un core n’exécute qu’une seule task à la fois, il est tout à fait possible d’allouer plusieurs cores par task, par exemple si vous souhaitez faire du multithreading. Dans ce cas, référez-vous au paramètre spark.task.cpus. Évidemment, si vous avez 6 cores et le paramètre spark.task.cpus à 2, vous n’aurez que 3 tasks en parallèle au maximum.
Il semblerait donc que le partitionnement par défaut soit le plus efficace dans notre cas et j’en imagine déjà certains froncer les sourcils, et pour cause !
La documentation Spark recommande environ 3 partitions par core disponible au traitement.
Dans notre cas, étant donné que ma machine possède 4 coeurs, la documentation aurait recommandé l’usage de 12 partitions.
Bien évidemment, mon exemple est loin de représenter un contexte réel. Utiliser 1, 4 ou 12 partitions n’aura aucun effet sur le temps de traitement.
Dès lors, comment comprendre cette recommandation ?
Prenons l’exemple suivant :
- 4 cores disponibles,
- Un traitement théorique f à appliquer sur les données.
Dans un environnement idéal, chaque partition prendrait un temps similaire à être traitée.
Or, dans la réalité, les traitements ressemblent le plus souvent à cela :
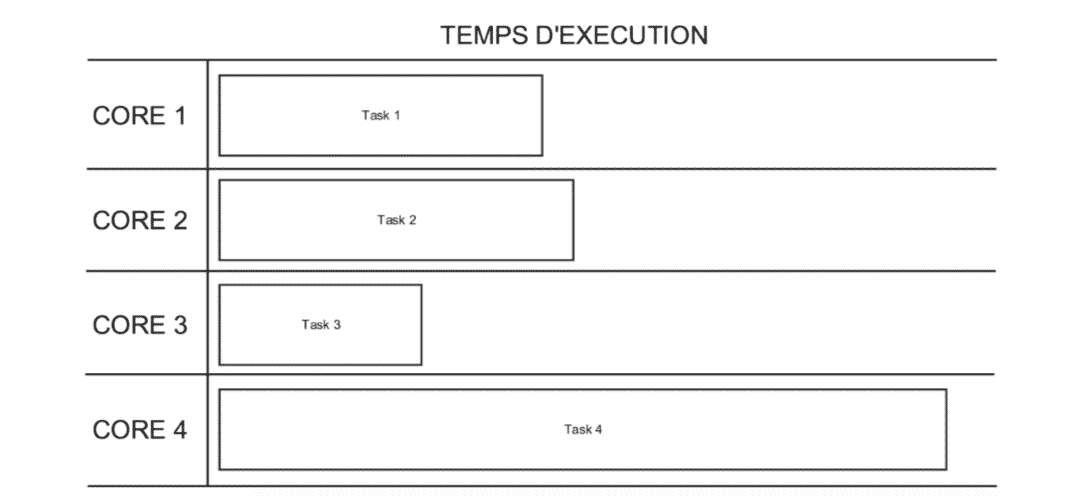
Ici, le calcul ne sera terminé que lorsque la task 4 aura fini d’être exécutée. On voit bien, en outre, que pendant ce temps-là, les autres cores ne travaillent plus. Le temps de calcul n’est donc pas correctement réparti entre les partitions.
Cela peut s’expliquer par plusieurs raisons, comme la différence de taille des partitions ou bien des cores plus lents que d’autres.
Afin de limiter cela, il est donc conseillé d’avoir environ 3 fois plus de partitions que de cores disponibles afin de mieux distribuer les tasks et de permettre aux cores plus rapides de traiter plus de tasks plutôt que de rester à ne rien faire, ce qui n’aurait pas été possible avec une tâche par core.
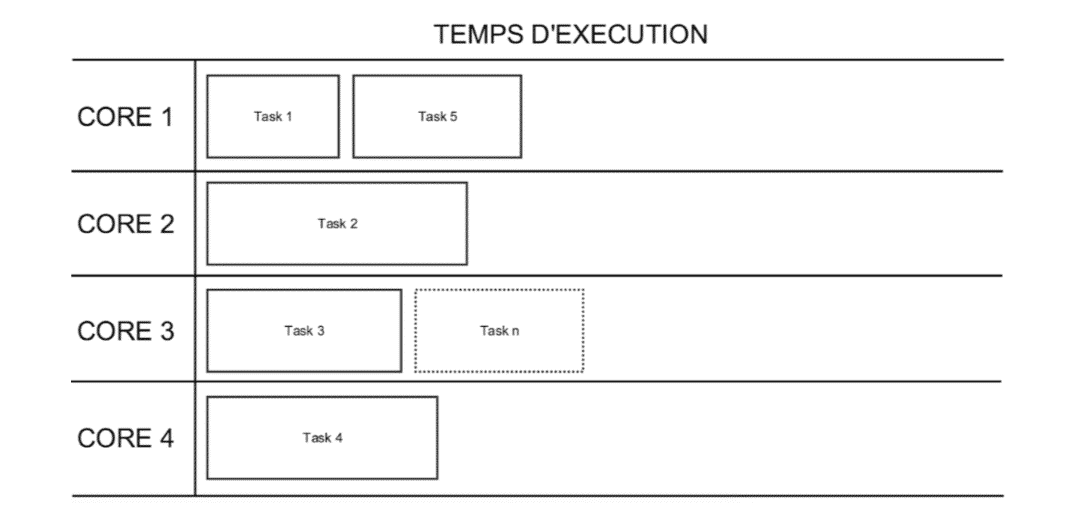
Ici, avec plus de tasks que de cores, dès qu’un core termine un traitement, il se verra attribuer une autre task restée en attente. Cela est représenté par la task n du schéma, attribuée au core 3 car étant le seul disponible.
Le ratio de 3 n’est évidemment pas gravé dans le marbre, l’idée étant juste de permettre une meilleure répartition des tâches tout en évitant d’en générer un trop grand nombre ce qui aurait pour résultat de surcharger la gestion de ces dernières.
Gérer le partitionnement de ses données
Après avoir vu ce qu’était une partition, voyons comment gérer nous même ce partitionnement.
Pour partitionner vos données, vous avez deux possibilités :
- Utiliser la stratégie par défaut en spécifiant un nombre de partitions,
- Utiliser un partitioner spécifique sur un RDD[(K,V)] (couple clé-valeur).
La stratégie de partitionnement par défaut
Si vous avez déjà parcouru la documentation, vous avez du tomber sur des méthodes telles que repartition ou coalesce vous permettant de partitionner à nouveau vos données.
Remarque :
Si vous souhaitez baisser votre nombre de partitions, préférer utiliser coalesce qui limite le data shuffling. Attention toutefois aux tailles des partitions résultantes qui peuvent être moins équilibrées qu’avec repartition, qui lui cause un full data shuffle.
Ces deux méthodes utilisent le partitioner par défaut de Spark, le HashPartitioner.
Son fonctionnement est simple : il attend un nombre de partitions désiré et chaque donnée se verra attribuer une partition en fonction du résultat du calcul suivant :
hash(clé) % nombre de partition
Prenons un exemple :
val rdd = session.sparkContext.parallelize(0 to 9) rdd.repartition(10)
Si vous avez bien suivi, vous devriez vous poser la question suivante :
“Comment est-ce possible ? Les valeurs n’ont pas de clé, on ne devrait pas pouvoir utiliser le HashPartitioner !”
Et c’est tout à fait correct ! Le fait est que la clé de chaque valeur sera générée lors de l’appel à repartition / coalesce.
Pour chaque partition existante, une première clé, marquée en gras sur le tableau ci-dessous, sera calculée aléatoirement puis sera incrémentée pour chaque valeur successive de la partition.
Ces clés seront ensuite utilisées pour partitionner à nouveau les données.
Prenons par exemple un RDD possédant 3 partitions. On souhaite le partitionner en 4 :

Le nouveau RDD serait donc :
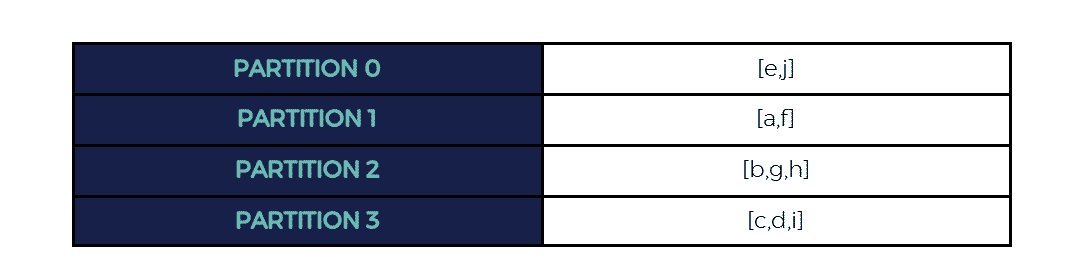
Utiliser ce type de partitionnement nous assure un RDD “équitablement” réparti car les clés sont générées de sorte à disperser au mieux les données.
Remarque :
La fonction de hash utilisée par Spark dépendra du langage (Scala, Python, etc.).
Utiliser un partitioner spécifique
Il existe des cas où la stratégie par défaut ne suffit pas. Par exemple, si l’on souhaite co-localiser les données possédant la même clé dans une même partition afin d’optimiser certains traitements. Il n’est pas possible d’utiliser la stratégie par défaut qui utiliserait des clés générées aléatoirement alors que nous souhaitons nous servir de nos propres clés.
Dans ce cas, la méthode partitionBy s’offre à nous (uniquement disponible sur les RDD[(K,V)] et nous permet de spécifier le partitioner à utiliser.
Ainsi, on peut très simplement utiliser le HashPartitioner sur nos propres clés :
val rdd = session
.sparkContext
.parallelize(Seq("a", "aa", "aaa", "aaaa", "b","bb","bbb","bbbb"))
.map(x => (x.length, x))
rdd.partitionBy(new HashPartitioner(4))
Ici, voilà ce que cela donnerait :
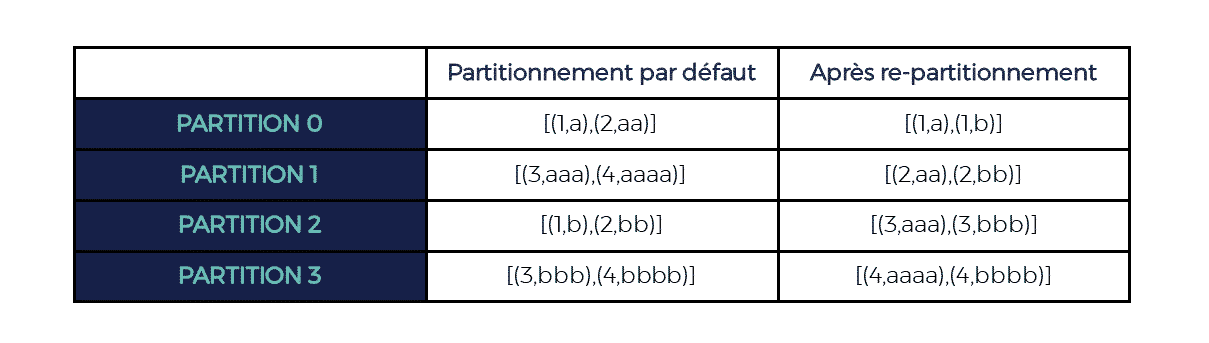
Néanmoins, il est très important d’avoir en tête comment le partitioner fonctionne afin d’éviter toute déconvenue.
Prenons par exemple les clés suivantes : 8, 96, 240, 400, 800. Si nous avions utilisé le même partitioner que précédemment, toutes les données auraient fini dans la même partition (le modulo du hash de chaque clé étant égal à 0).
Nous aurions donc 3 partitions vides sur les 4. Une optimisation pas vraiment optimale.
Dans ce cas précis, l’utilisation du RangePartitioner de Spark aurait été plus judicieuse. En effet, ce partitioner nous permet de regrouper des “ranges” de clés ensemble. Un RangePartitioner(4) nous aurait donné les partitions suivantes :

Cette stratégie de partitionnement peut se révéler très utile pour peu que vos clés soient ordonnables et équilibrées.
Enfin, si vous n’êtes satisfait ni par le HashPartitioner ni par le RangePartitioner, vous avez la possibilité d’implémenter un partitioner vous même. Il vous suffira pour cela d’étendre la classe Partitioner et d’implémenter deux méthodes :
- numPartitions : retourne le nombre de partitions du Partitioner,
- getPartition : retourne le numéro de partition pour une clé donnée.
class CustomPartitioner extends Partitioner {
override def numPartitions: Int = ???
override def getPartition(key: Any): Int = {
???
}
}
Ainsi donc, nous avons vu ce qu’était une partition dans le sens où Spark l’entend, mais aussi comment agir sur ce partitionnement. Le prochain article relatif au partitionnement s’attardera plus précisément sur les bonnes pratiques à adopter en fonction des cas d’usage.

Vos commentaires
Bravo!