
Depuis un demi-siècle, les données ont progressivement pris une place centrale dans notre quotidien, devenant le moteur de l’innovation, de la prise de décision et de l’économie moderne. Mais comment ces données sont-elles gérées, stockées et exploitées ? L’histoire de l’évolution des architectures Data nous révèle bien plus qu’un simple progrès technologique : elle reflète une transformation profonde de notre manière de concevoir et d’interagir avec l’information.

Des premières bases de données des années 1970 aux systèmes massifs et interconnectés d’aujourd’hui, chaque décennie a été marquée par des avancées majeures. Ces avancées ont permis non seulement de répondre aux défis techniques de leur époque, mais aussi d’accompagner les besoins croissants des entreprises.
Cet article propose de retracer ces 50 dernières années pour découvrir comment les architectures Data se sont adaptées pour répondre à ces besoins.
Qu’est-ce que l’architecture data ?
Ce glossaire Data vous permettra de comprendre les termes essentiels liés aux architectures Data :
- Architecture centralisée : toutes les données sont stockées dans un seul système.
- Architecture décentralisée : les données sont réparties dans plusieurs systèmes interconnectés.
- Data warehouse (DW) : bases de données relationnelles dédiées à l’analytique.
- Data lake : espace de stockage massif.
- Modern data warehouse (MDW) : solution cloud de data warehouse, permettant des analyses sur des grosses volumétries de données.
- Data fabric : infrastructure intelligente et connectée qui simplifie l’accès, l’intégration et la gestion des données, quel que soit leur emplacement, pour en faciliter l’utilisation et la prise de décision.
- Data lakehouse : système central, permettant aussi bien un stockage massif que l’exploitation des données comme des analyses, de la prédiction ou de la mise à disposition de données pour d’autres applications. Un data lakehouse combine les avantages d’un data warehouse et d’un data lake.
- Data mesh : concept basé sur la décentralisation des données. Chaque équipe gère ses propres données comme un produit pour les rendre facilement partageables et utilisables dans toute l’organisation.
- Gouvernance de données : ensemble de pratiques pour assurer la qualité, la sécurité et l’usage des données.
- Système transactionnel (OLTP) : ensemble d’applications pour gérer des opérations courantes et fréquentes comme les achats, les paiements et les réservations.
- Système analytique (OLAP) : logiciel conçu pour analyser de grandes quantités de données afin d’aider à prendre des décisions stratégiques.
Envie d’en savoir plus sur la gouvernance des données ?
👉 Découvrez notre article « C’est quoi la gouvernance des données en entreprise ? »

Qu’entend-on par architecture de données ?
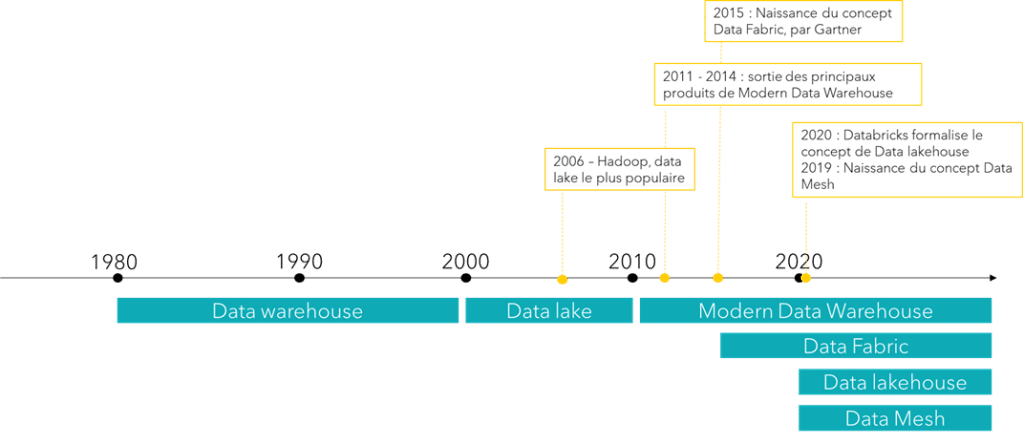
Retour sur l’évolution Data depuis ces 50 dernières années. Les bases de données relationnelles ont été le pilier du stockage des données pendant plusieurs décennies. L’un des premiers systèmes relationnels commercialisés a été développé par Oracle Corporation, fondée en 1977 par Larry Ellison, Bob Miner et Ed Oates. En 1979, Oracle a lancé Oracle V2, la première base de données relationnelle disponible sur le marché, inspirée des travaux d’Edgar F. Codd sur le modèle relationnel.
Analyse descriptive, Batch processing, Datalake, Deep learning, IoT…Envoie d’un glossaire complet sur le Big DATA ?
👉 Découvrez notre glossaire « Big Data : le lexique à connaître »

Le data warehouse
Le premier data warehouse relationnel utilisé en production a été le système Teradata, développé à l’université de Stanford par Jack E. Shemer, fondateur de la Teradata Corporation en 1979. Le développement des data warehouses relationnels est arrivé à la fin des années 1980.
Dans les années 1970 et 1980, les entreprises utilisaient des bases de données relationnelles pour des applications opérationnelles telles que la saisie des commandes et la gestion des stocks. Ces applications sont appelées systèmes transactionnels ou Online Transaction Processing (OLTP). Les systèmes OLTP peuvent créer, lire, mettre à jour et supprimer des données dans une base de données. Mais ces opérations nécessitent des temps de réponse rapides.
On peut imaginer exécuter des requêtes analytiques et générer des rapports sur une base de données relationnelles utilisée par une application opérationnelle. Mais cela consomme beaucoup de ressources et peut entrer en conflit avec d’autres opérations. Les data warehouses relationnels (ou DW), bases de données relationnelles dédiées à l’analytique, ont été inventés en partie pour résoudre ce problème. La séparation entre les systèmes opérationnel et analytique permet d’optimiser les performances de chacun de ces systèmes.
Le data lake
Le data lake est un concept plus récent, apparu dans les années 2000. Un data lake est simplement un espace de stockage. Les premiers data lake ont débuté avec Apache Hadoop Distributed File System (HDFS), d’abord sur des serveurs on premise puis dans le cloud.
Les data lakes ont été considérés comme la solution à tous les problèmes liés aux DW, notamment :
- Le coût élevé ;
- L’évolutivité limitée ;
- Les performances médiocres ;
- Les problématiques liés à la préparation des données ;
- Et à la prise en charge de certains formats.
Les data lakes pouvaient substituer en partie les data warehouses relationnels.
Le problème est que l’interrogation des données dans un data lake n’est pas si simple : elle nécessite des compétences spécifiques et des outils adaptés. Les entreprises ont découvert que cette solution était complexe et difficile à utiliser et qu’elle n’offrait pas les fonctionnalités clés d’un data warehouse telles que la prise en charge transactionnelle ou la forte structuration des données.
Mais le data lake n’a pas disparu pour autant. Il s’est transformé pour répondre à un objectif différent : le stockage massif des données.
Au début des années 2010, les entreprises devaient faire face à une augmentation exponentielle du volume, de la variété et de la vitesse des données. Face aux défis du Big Data, le DW n’était alors plus suffisant alors que le data lake était une bonne solution de stockage.
Les entreprises ont par conséquent commencé à combiner ces deux approches en construisant des architectures hybrides :
- D’un côté, un data lake pour stocker et explorer massivement les données ;
- Et de l’autre, un data warehouse pour l’analyse et la structuration des informations critiques.
Cette convergence a donné naissance au Modern Data Warehouse (ou MDW), un modèle alliant les capacités analytiques avancées du DW avec l’agilité et la scalabilité du data lake. Cette architecture s’est très vite imposée comme une réponse polyvalente aux enjeux des données pour devenir l’architecture la plus populaire.
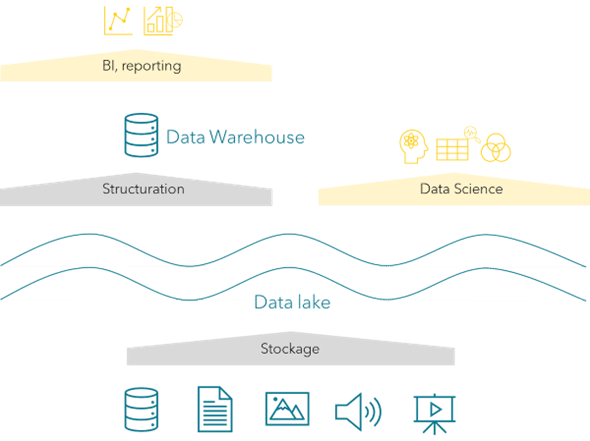
Le data lake stocke les données ; le DW structure les données pour les analyses BI.
Envie de découvrir un exemple complet de mise en place d’un Datalake ?
👉 Découvrez notre cas client sur la mise en place d’un Data Lake full Cloud dans un grand groupe énergétique.

La data fabric
Les data fabrics ont commencé à apparaître vers 2016. On peut considérer cette architecture comme un « tissu » qui relie toutes les données d’une entreprise, peu importe où elles se trouvent. La data fabric organise et automatise le traitement des données pour les rendre facilement accessibles et compréhensibles. Cela permet de trouver rapidement des informations fiables sans se soucier de l’endroit où elles sont stockées.
Le data lakehouse
Les data lakehouses, contraction de data lake et data warehouse, sont apparus en 2020, popularisées par Databricks. Le concept du data lakehouse est de simplifier l’architecture pour n’avoir qu’un seul stockage, le data lake, répondant à tous les cas d’usage, aussi bien d’analytique BI que de data science. Le DW est supprimé. Mais alors, quelle différence avec l’approche « data lake » d’avant, qui n’avait pas fonctionné ?
Dans le data lakehouse, on introduit une couche logicielle de stockage transactionnel au-dessus du data lake. Ainsi, on peut garder un fonctionnement proche du data warehouse, avec tous ses avantages, tout en ayant qu’un seul stockage.
Le data mesh
Le terme data mesh est apparu pour la 1re fois en mai 2019, dans un blog posté par Zhamak Dehghani, fondatrice et CEO de Nextdata.
Toutes les architectures vues jusqu’à présent impliquent une centralisation des données. Cette approche pose néanmoins trois grands problèmes :
- La propriété de la donnée (ownership) ;
- La qualité des données ;
- Et la mise à l’échelle technique et organisationnelle.
L’objectif du data mesh est de résoudre ces problèmes. Dans un data mesh, les données sont gardées dans chaque domaine d’une entreprise. Chaque domaine dispose de son SI, et de son équipe IT et data. C’est une architecture totalement décentralisée.
Il est important de comprendre que le data mesh est davantage un concept qu’une technologie. La mise en place d’un data mesh implique un changement organisationnel et culturel très important.
Conclusion
L’évolution des architectures Data au cours des cinq dernières décennies a été remarquable. Chaque avancée dans les architectures de données a répondu à des besoins spécifiques de son époque :
- Centralisation et structuration dans les années 1980 ;
- Flexibilité et scalabilité dans les années 2000 ;
- Unification, décentralisation et support de l’intelligence artificielle dans les années 2020.
Ces évolutions montrent que l’innovation en matière d’architecture de données reste un levier clé pour les entreprises cherchant à tirer parti de leurs données.
Aujourd’hui, les architectures Data sont à un tournant. Alors que les volumes de données continuent de croître de manière exponentielle et que les attentes en matière de rapidité, de sécurité et de personnalisation augmentent, il est clair que l’avenir reposera sur une combinaison de scalabilité et de flexibilité. L’intégration de l’intelligence artificielle, des technologies de streaming en temps réel et des modèles de gouvernance décentralisés façonne déjà la prochaine génération d’écosystèmes Data.
L’histoire des architectures Data est donc celle d’une adaptation continue, où chaque innovation s’appuie sur les acquis du passé pour répondre aux défis de demain. Mais ce voyage est loin d’être terminé.
L’essentiel pour les entreprises sera de rester à l’écoute de ces évolutions et d’adopter une posture proactive pour transformer les données en véritable moteur de valeur. Après tout, dans l’univers des données, l’innovation n’a jamais de fin.
Désormais, il existe une multitude d’architecture, mais laquelle choisir ?
👉 Découvrez notre livre blanc « Quelle architecture data choisir pour votre entreprise ? »

Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.


Pas encore de commentaires