
Définir le terme « Intelligence Artificielle » amène irrémédiablement à un problème plus grand, celui de la définition de l’intelligence elle-même. Si la logique et la raison semblent avoir des places prédominantes au sein de cette définition, celle de la créativité reste quant à elle à établir. En effet, comment font les IA pour générer des images ?
Les chercheurs en intelligence artificielle n’ont pas attendu les conclusions philosophiques du sujet pour développer des modèles d’IA capables d’être créatifs. Dans cet article, je vais tâcher de vous donner un aperçu de cette créativité algorithmique à travers l’exemple de la génération d’image.

Comment créer une IA qui génère des images ?
Dans cette 1re partie, je vous expliquer comment les ordinateurs apprennent et voient.
L’apprentissage supervisé
L’apprentissage machine ou machine learning repose sur une idée simple. À partir d’un ensemble de données, on veut être capable :
- Soit de comprendre les liens et les structures de nos données ;
- Soit de prédire des choses, connues pour nos données, sur d’autres données relativement proches.
Notre problème de génération d’images appartient à la deuxième catégorie. En effet, générer une image à partir d’une description textuelle, c’est prédire l’image la plus probable associée à la description. Cette tâche de prédiction à partir de données connues appartient au champ de « l’apprentissage supervisé ».
Pour bien comprendre ce concept d’apprentissage supervisé, faisons un détour par une tâche un peu différente que la génération d’image, celle de la classification d’images, et prenons le cas spécifique suivant : « Attribuer à une photo, l’animal qu’elle représente ».
Pour réaliser cette tâche, on va utiliser un modèle qu’on peut visualiser comme une machine, avec des boutons, qui prend en entrée une photo et retourne en sortie un nom d’animal. Le fait de tourner les boutons modifie le comportement de la machine. Il existe donc une configuration optimale des boutons – boutons qu’on appellera par la suite des paramètres – qui permet au modèle de performer du mieux qu’il peut sur la tâche confiée.
Envie de comprendre le fonctionnement de l’IA ?
👉Découvrez notre article « Comment expliquer le fonctionnement de l’intelligence artificielle simplement ? »

Pour trouver cette configuration optimale, on suit une procédure très simple :
1) On collecte un grand nombre de photos, qu’on étiquette avec l’animal représenté.
2) On fixe les paramètres du modèle sur une configuration initiale :
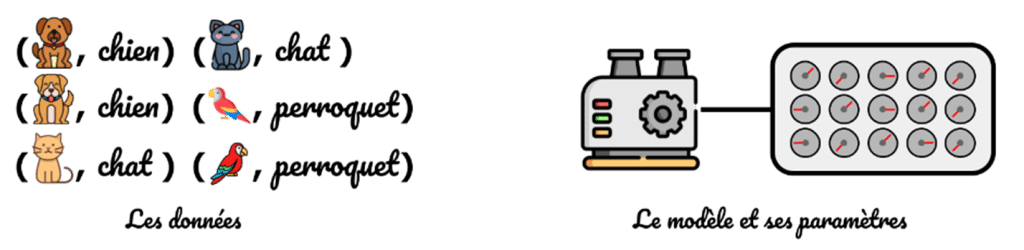
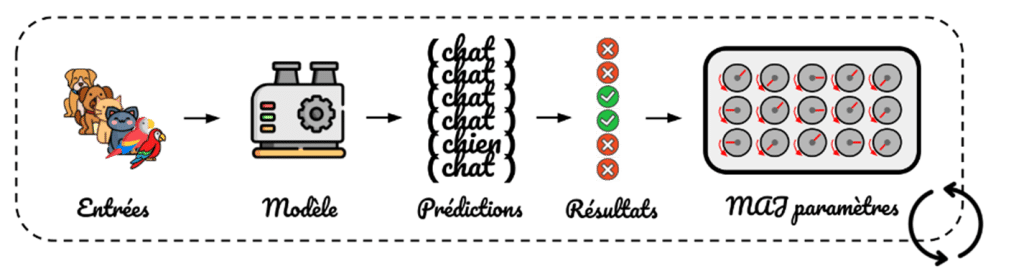
3) On donne nos photos au modèle pour qu’il prédise quel est l’animal représenté.
4) On regarde si les sorties prédites par notre modèle sont proches des étiquettes associées aux photos.
5) On modifie les paramètres pour améliorer les résultats observés.
6) On recommence les étapes 3, 4 et 5 jusqu’à avoir de bons paramètres :
7) On peut utiliser notre modèle sur des photos jamais vues lors de l’entraînement :
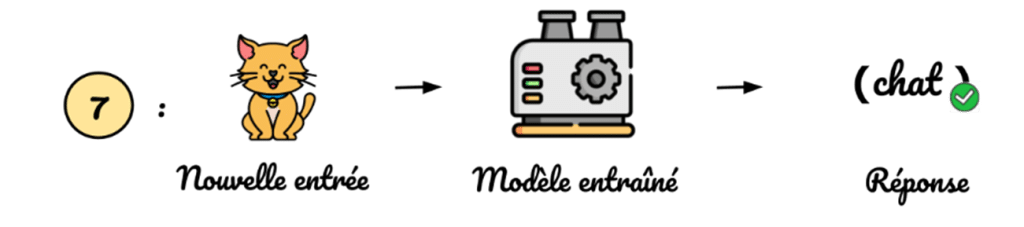
Voilà donc ce qu’est l’apprentissage supervisé : on montre à l’ordinateur des exemples concrets de ce qu’on attend pour une tâche donnée pour qu’il puisse réitérer cette tâche sur des données similaires.
C’est ce qu’on va essayer de mettre en place pour obtenir un modèle capable de générer des images.
![[Livre Blanc] Intelligence artificielle : guide d’une IA décomplexée pour votre entreprise](https://meritis.fr/wp-content/uploads/2022/08/diapositive4.jpg)
Le saviez-vous ? 85 % des projets d’intelligence artificielle échouent, et ce alors que plus de 7 entreprises sur 10 sont engagées dans des projets IA ?
👉 Découvrez les clés du passage à l’échelle de votre projet d’Intelligence Artificielle
Téléchargez notre guide pour répondre à vos questions :
- Par où commencer ?
- Quels prérequis mettre en place pour passer en production ?
- Quel algorithme utiliser ?
- Comment implémenter son modèle ?
Générateur d’image IA : la représentation numérique des images
Trouver les bons paramètres pour un modèle donné nécessite de faire des calculs et donc de manipuler des chiffres. En effet, les modèles d’aujourd’hui possèdent des milliards de paramètres pouvant prendre n’importe quelle valeur continue. Il est donc inconcevable de tirer aléatoirement ces paramètres jusqu’à trouver une configuration acceptable.
De plus, un ordinateur n’est capable de manipuler que des chiffres. Pour entraîner un modèle capable de générer des images à partir d’un texte, il faut donc trouver une astuce pour représenter les images et les textes comme des suites de chiffres.
N’importe quelle image peut être découpée comme une grille dans laquelle chaque case – appelée pixel – représente une couleur. Plus les pixels sont petits et nombreux, et plus l’image apparaîtra réaliste. Le nombre de pixels utilisés pour représenter une image est appelé «résolution de l’image».
L’idée pour représenter une image est donc de stocker une grille. Cependant, une grille de couleurs n’est pas acceptable pour manipuler une image sur ordinateur. Il faut donc transformer ces couleurs en nombres.
La méthode la plus connue pour faire ceci, appelée « représentation RVB », est d’associer à une couleur trois nombres compris entre 0 et 255. Ils représentent respectivement l’intensité de rouge, de vert et de bleu de la couleur donnée. Par exemple : un rouge pur correspond au code RVB suivant : 255, 0, 0. De cette manière on peut représenter une image par trois grilles de nombres représentant les niveaux de rouge, de vert et de bleu de l’image.

Maintenant qu’on a une méthode pour représenter numériquement une image, il faut réussir à faire de même pour un texte. La méthode la plus intuitive – appelée méthode sparse – consiste à se restreindre à un ensemble de mots connus à l’avance – disons les 50 000 mots les plus utilisés de la langue française – puis d’associer chaque mot à sa position dans l’ensemble de départ.
Par exemple, le mot « rien » est le 74e mot le plus utilisé en français, on le représentera donc par le nombre 74. Cela permet de représenter une phrase comme une suite successive de nombres compris entre 1 et 50 000. Les méthodes actuelles reposent sur un concept appelé embedding. Mais comme ce n’est pas le sujet de cet article, restons sur la méthode décrite précédemment, l’essentiel étant de pouvoir associer des textes à des nombres.
Générer des images, deux idées différentes
Les réseaux génératifs adversariaux ou GANs
Les GANs – pour Generative Adversarial Network – ont émergé en juin 2014. Ce sont les premières méthodes développées à avoir donné des résultats satisfaisants pour la génération d’image. La méthode derrière les GANs est assez ludique et donc assez souvent vulgarisée. Je m’efforcerai alors d’être bref mais je ne peux que vous inviter à vous renseigner davantage de votre côté.
Les GANs ne reposent pas sur un seul modèle comme présenté dans la partie apprentissage supervisée, mais sur deux. Le premier modèle a pour but de générer une image d’un sujet précis et prendra le nom de « Générateur ». Le deuxième modèle, appelé « Discriminateur », a pour but de différencier une image réelle d’une image générée artificiellement.
Au départ, leur paramétrage étant aléatoire, les deux modèles sont très mauvais dans leur tâche respective. Le « Générateur » ne sait pas générer d’images cohérentes et le « Discriminateur » ne sait pas comment différencier les images générées des images réelles. L’idée est alors de faire affronter ces deux modèles pour les faire progresser, en suivant ces étapes :
- Le « Générateur » commence par générer des images aussi réalistes que son paramétrage actuel le lui permet.
- Les images générées sont mélangées avec les vraies images de chat.
- Le « Discriminateur » essaye de correctement catégoriser les images présentées – réelles ou générées.
- Les résultats du « Discriminateur » (proportion d’images correctement jugées) lui sont présentés pour qu’il ajuste ses paramètres et donc affine son expertise.
- Le « Générateur » reçoit ses résultats (proportion d’images générées qui ont outrepassé l’expertise du « Discriminateur ») pour, qu’à son tour, il améliore son paramétrage et donc sa capacité à générer des images réalistes.
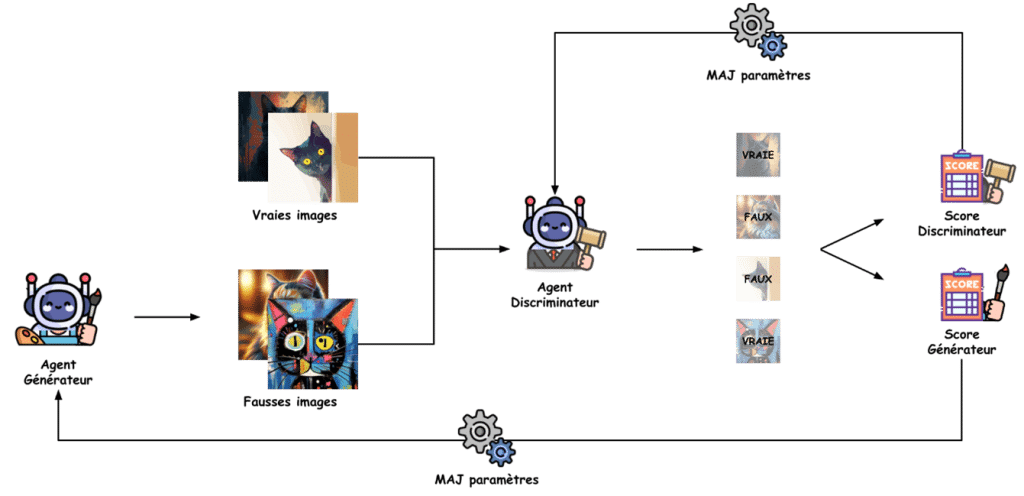
Les objectifs des deux modèles étant contraires, ils se tirent donc mutuellement vers le haut. Il faut alors itérer plusieurs fois ce petit jeu, jusqu’à obtenir un premier modèle très performant pour déceler les faux, mais surtout un deuxième modèle très doué pour usurper des photos réelles. Il suffit alors de récupérer ce modèle et le tour est joué.
On peut désormais générer des images de chats très réalistes ! Attention tout de même. Il est possible d’itérer cette boucle d’apprentissage sans pour autant réussir à obtenir un bon « Générateur » si la quantité et la qualité des images d’entraînement ne sont pas au rendez-vous. Ces deux critères font souvent la différence entre des bons et des mauvais modèles en data science.
Les modèles de diffusion
Pourquoi développer un autre outil alors que les GANs ont l’air de très bien fonctionner en pratique ? Si vous regardez attentivement la méthodologie GAN, on a une bonne méthode pour générer un type précis d’image selon les images réelles données en entrée du modèle comme des chats, des chiens, des voitures… Mais ce qu’on désire réellement, c’est une méthode capable de générer des images variées.
Une approche développée après l’apparition des GANs est alors celle des modèles dits de diffusion. Le cadre mathématique derrière ces modèles est assez solide mais loin d’être nécessaire pour comprendre l’idée maîtresse de la méthode.
Vous voulez plonger dans les mathématiques derrière la méthode ?
👉 Découvrez le papier scientifique introduisant les modèles de diffusion appliqués aux images
Le but de la méthode va être de développer un modèle capable de « débruiter » une image. Le bruit d’une image est le terme employé pour qualifier la détérioration de la qualité de l’image. Plus le bruit est bas, plus l’image est proche de sa qualité originale et inversement.

La méthodologie appliquée pour les modèles de diffusion est donc d’entraîner un modèle à débruiter des images de plus en plus bruitées, jusqu’à l’entraîner à débruiter des images constituées uniquement de bruit pour que le modèle « invente » une image à partir d’une soupe de pixels aléatoires.
Pour réaliser cette prouesse, en accord avec le cadre décrit dans la section sur l’apprentissage supervisé, il est nécessaire d’avoir des données pour entraîner notre modèle. L’avantage des méthodes de diffusion repose sur le fait que, créer des images bruitées à partir d’images de bonne qualité est relativement facile. En effet, on fixe un seuil, puis, pour chaque pixel, on tire un nombre aléatoire entre 0 et 1 :
- Si ce nombre est plus grand que le seuil, on modifie la valeur du pixel correspondant ;
- Sinon, on le laisse tel quel.
Plus notre seuil est petit, plus la probabilité de corrompre un pixel est grand et donc, plus notre image devient bruitée. De cette manière, on peut créer des images exemples qui serviront à entraîner notre modèle. En pratique, le bruit n’est pas ajouté de cette manière mais l’idée reste proche.
En lui montrant beaucoup d’images variées associées avec différents niveaux de bruit, notre modèle va pouvoir ajuster ses paramètres pour débruiter les images selon n’importe quel niveau de bruit et ce, même avec 100% de bruit. Une fois son entraînement terminé, le modèle peut donc inventer de nouvelles images à partir d’un bruit tiré aléatoirement.
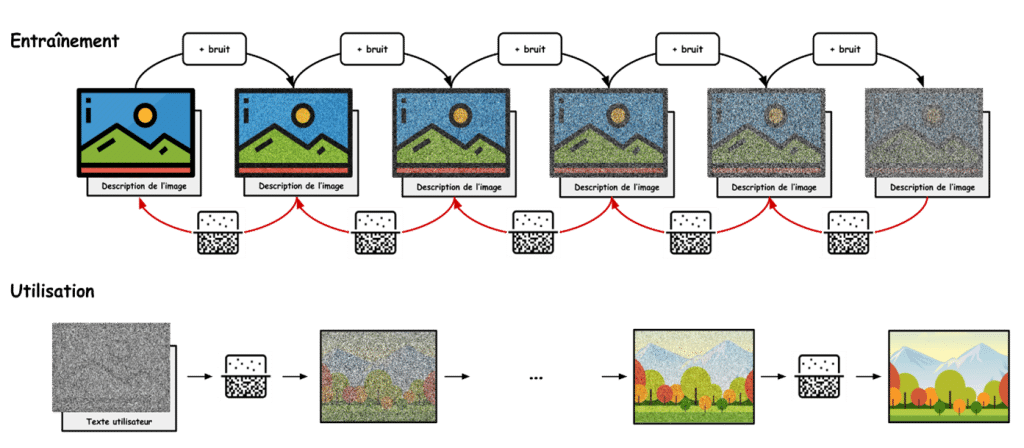
Il reste cependant un mystère à élucider. En effet, imaginons que je génère un bruit pur et que je demande à mon modèle entraîné de le débruiter. Il va en effet accomplir sa tâche, mais comment savoir si le résultat sera un chat en train de dormir ou une plante verte en parachute ? Il faut réussir à lier le texte à l’image.
Souvenez-vous, dans la partie sur la représentation numérique des images, on a vu que les images – tout comme les textes – peuvent être décrites par des listes de nombres. C’est même de cette manière que votre ordinateur va être capable d’établir des calculs à partir de cette base. Pour entraîner notre modèle, on ne va donc pas se contenter de lui donner les images et leurs versions bruitées, mais également la représentation numérique d’une description de la photo.
De cette manière, au lieu de simplement donner une image de bruit à notre modèle une fois entraîné, on pourra également lui donner une description textuelle qui viendra orienter le résultat final. Comme deux images semblables ont également des descriptions semblables, le petit tour de passe-passe consistant simplement à assembler la liste de nombres représentant l’image avec celle représentant la description textuelle, fonctionne plutôt bien.
Envie de découvrir comment l’IA générative peut transformer vos usages ?
👉 Regardez le replay du meetup « Innover avec l’IA Générative pour Transformer vos Usages » !
![[Replay Meetup] Entrez dans l'ère de l'IA Generative, transformez vos usages](https://meritis.fr/wp-content/uploads/2024/07/replay-meetup-entrez-dans-lere-de-lia-generative-transformez-vos-usages-1024x576.jpg)
Aller plus loin au sujet de la génération d’images IA
Les auto-encodeurs variationnels
Si les principales idées des modèles de diffusion n’ont pas été trahies, les problèmes qu’ils engendrent ont en revanche étaient ellipsés, laissant place à un apaisant sentiment de facilité. En réalité, une des hypothèses mathématiques sur laquelle reposent les modèles de diffusion les contraint à débruiter les images de manière itérative, de tout petits pas en tout petits pas. En pratique, cela rend inexploitable ces modèles sur des images de taille raisonnable, le temps de débruitage croissant inexorablement.
La stratégie utilisée par les data engineers est alors la suivante :
- Entraîner le modèle à débruiter des petites images – typiquement 16 x 16 pixels ;
- Agrandir les petites images débruitées pour obtenir une taille raisonnable.
On imagine alors, suivant cette stratégie, qu’il faut développer une méthode pour rapetissir et agrandir des images de manière intelligente. Pour que cela fonctionne en pratique, on ne peut pas simplement utiliser un outil de redimensionnement d’image classique, ces derniers ne pouvant altérer la taille des images de manière aussi significative en produisant un résultat satisfaisant.
C’est ici qu’interviennent les VAE – ou Variational Auto Encoder pour les plus anglophones d’entre vous. Les VAE appartiennent à la famille des modèles entraînés par apprentissage supervisé. Cependant, ils sont totalement différents des modèles de diffusion utilisés pour le débruitage.
Un VAE est simplement entraîné à encoder des images – c’est-à-dire transformer la liste de nombres représentant une image en une liste plus petite – puis à décoder ces images – c’est-à-dire retrouver la grande liste de nombres à partir de la petite.
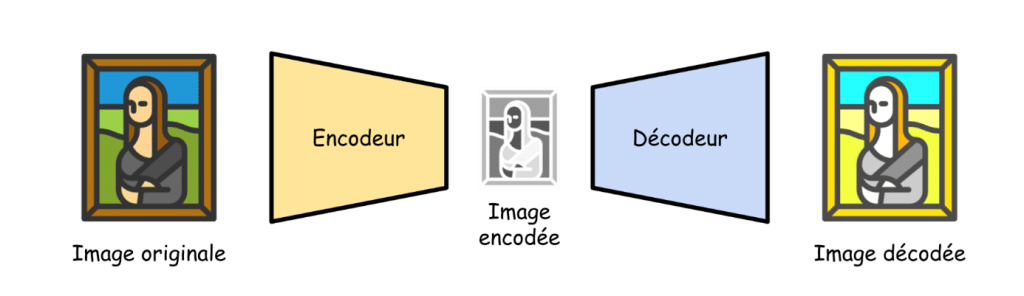
Comme l’entrée du modèle est également la sortie – en effet, on encode puis décode l’image dans le même pipeline – le modèle apprend en quelque sorte tout seul à bien encoder les images, d’où son nom d’auto-encodeur.
Mais d’où vient le V de VAE alors ? Pour proscrire toute mathématique de cet article, disons simplement que ce qui différencie un VAE d’un simple auto-encodeur, c’est sa capacité à contraindre le modèle de ne pas simplement mémoriser une table de correspondance entre les grandes et les petites listes, et donc de préserver une certaine continuité. Dit plus simplement, on veut que deux images qui se ressemblent soient encodées par deux petites listes qui se ressemblent.
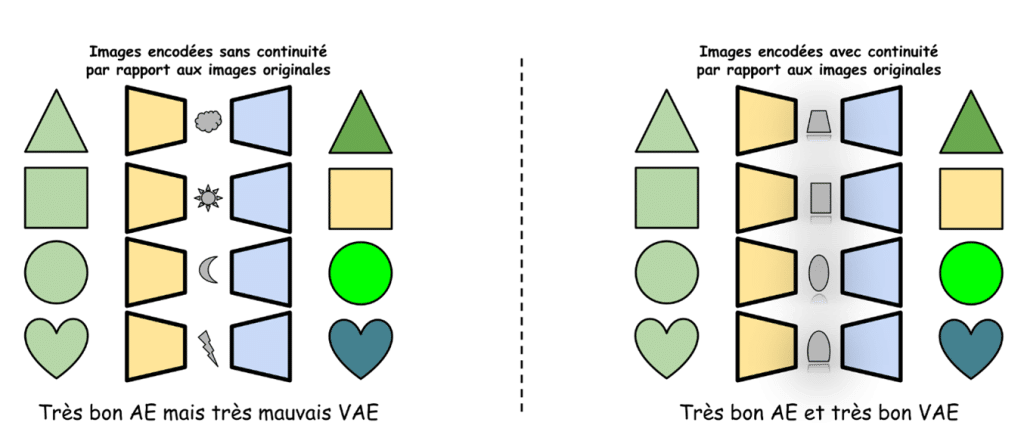
En utilisant un modèle de diffusion, on peut donc débruiter une petite image de bruit qui, une fois décodée par le décodeur d’un VAE, donnera une image de taille raisonnable. Et comme on utilise un VAE au lieu d’un simple AE, deux petites images proches une fois débruitées donneront deux images proches une fois décodées !
Et les GANs dans tout ça, on oublie ?
Si l’alliance modèles de diffusion-VAE fonctionne plutôt bien, la méthodologie souffre tout de même d’une perte d’informations au moment d’encoder l’image et continue de reposer sur le principe itératif de débruitage des modèles de diffusion.
Pourtant, on connaît une méthode qui ne souffre d’aucun de ces deux maux : celle des GANs. À l’heure actuelle, les modèles de génération utilisés sont une approche hybride entre les modèles de diffusion et les GANs qui sont appelés modèles ADD pour Adversarial Diffusion Distillation.
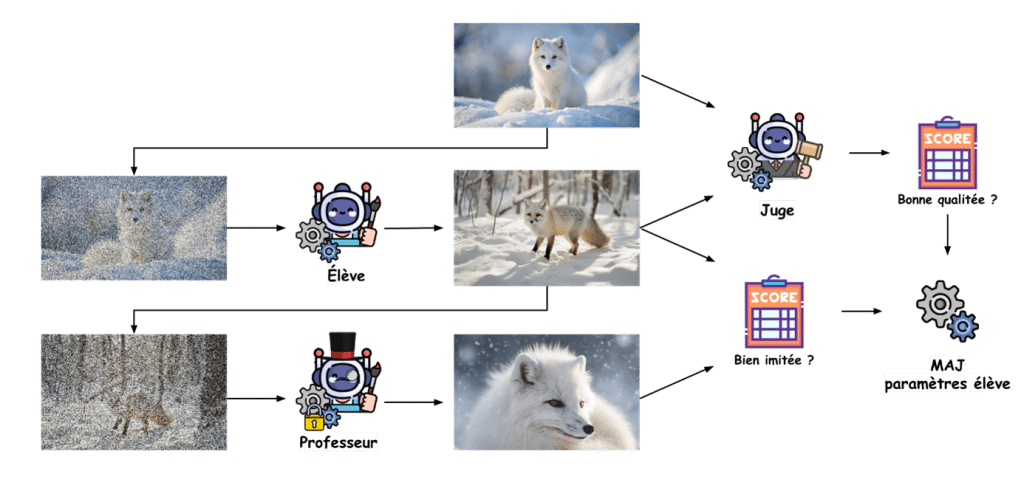
Pour entraîner ces modèles, rappelons-nous de ce que nous avions pour les GANs : un générateur et un discriminateur. Transformons un peu le jeu de rôle avec trois personnages au lieu de deux :
- L’élève ;
- Le professeur ;
- Et le juge.
L’idée est de voir l’élève comme un générateur, le juge comme un discriminateur et le professeur comme un modèle sachant déjà générer des images variées, typiquement un modèle de diffusion. Le but est d’entraîner l’élève à duper le juge – comme dans les GANs – mais également à imiter le professeur – qui est un modèle de diffusion. De cette manière, à la fin du processus d’entraînement, notre modèle sera capable de débruiter en une seule étape une image d’une qualité suffisante pour duper un juge expert.
L’utilité de l’intelligence artificielle pour la génération d’image
Dans un monde où la philosophie d’une science pour la science devient de plus en plus désuète, la question vis-à-vis de la pertinence de ces modèles se pose. Laissez-moi alors vous présenter rapidement deux cas pratiques où la génération d’image se fait doucement une place.
La création d’image IA
Que ce soit sur les réseaux sociaux, dans la publicité ou dans les jeux vidéo, la demande en illustrations explosent. Les modèles de génération d’image sont de plus en plus utilisés pour créer efficacement ces illustrations. Des projets intégrant l’IA générative de cette manière ont déjà vu le jour : c’est notamment dans le cas de la campagne publicitaire « Real magic » lancée par Coca Cola en 2023 ou des affiches promotionnelles de la marque Undiz.
La visualisation de produits
L’expérience utilisateur étant une partie importante des secteurs de la mode et du luxe, certaines entreprises utilisent aujourd’hui les capacités de génération d’image des IA pour offrir à leurs clients des prévisualisations personnalisées et réalistes de leurs produits. C’est entre autres l’ambition affichée par L’Oréal avec le rachat de la start-up ModiFace en 2018.
Des modèles généralistes comme Dall-E ou MidJourney entraînés avec les méthodes présentées ne pourraient performer avec une qualité suffisante pour des cas d’usage aussi précis. Un travail d’expert est nécessaire en amont pour aligner les modèles avec le rendu souhaité.
La génération d’image, c’est fini ?
La méthode survolée dans la dernière section est réellement la plus avancée aujourd’hui et produit des résultats de très bonne qualité. Je ne peux que vous inviter à lire le papier scientifique introduisant cette méthode. Malgré son défaut, comme tout papier scientifique, d’être illisible par les personnes fâchées avec les mathématiques, il a tout de même l’avantage d’avoir de nombreuses illustrations de qualité.
Les défis d’aujourd’hui dans la génération d’images IA sont toujours bien réels mais s’orientent de plus en plus vers la génération de vidéos – suites d’images cohérentes entre elles – ou la génération d’objets 3D – compilations d’images sous différents angles de vue.
Pour découvrir et jouer avec ces modèles, n’hésitez pas à consulter le dépôt GitHub de Stable Diffusion qui présente du code open source et les liens vers les articles scientifiques des différentes méthodes implémentées.
Une illustration récente des progrès en génération picturale, mais utilisant des modèles un peu différents que ceux présentés, est le déploiement de Sora, le nouveau modèle de génération vidéo par OpenAI. Pour l’instant indisponible en Europe, le modèle a pu faire ses premières preuves aux États-Unis par exemple, où il est utilisable par le grand public avec un abonnement ChatGPT + ou ChatGPT Pro.
L’intelligence artificielle a transformé la manière dont nous abordons la création d’images, en mêlant apprentissage supervisé, modèles génératifs adversariaux (GANs) et méthodes de diffusion. Ces technologies, bien qu’encore perfectibles, offrent déjà des résultats impressionnants et des applications concrètes, notamment dans le domaine du contenu numérique et de la visualisation produit.
L’avenir de la génération d’images s’étend vers des horizons encore plus vastes, tels que les vidéos ou les objets 3D, ouvrant la voie à de nouvelles perspectives pour les industries créatives et technologiques. Ces avancées témoignent de l’importance cruciale de continuer à explorer et à affiner ces outils, tout en veillant à leur usage éthique et responsable.
Vous avez envie de toujours plus d’articles sur l’IA générative ?

Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.



Pas encore de commentaires