
AWS Glue est un service de préparation et d’intégration des données entièrement géré et sans serveur, conçu pour simplifier et automatiser les tâches liées à l’extraction, à la transformation et au chargement (ETL) des données.
Dans cet article, nous allons détailler plus en profondeur les fonctionnalités ETL d’AWS Glue. L’occasion de découvrir comment créer un job dans AWS Glue, à la fois avec Python et avec Spark, de voir comment monitorer l’exécution des jobs et d’appréhender la manière dont il est possible d’orchestrer un workflow dont les jobs seront exécutés en séquentiel.
Mieux comprendre le concept de Big Data
Le Big Data, terme omniprésent dans les domaines de la technologie et des affaires, fait référence à la gestion et à l’analyse de vastes ensembles de données complexes. Cette pratique révolutionnaire est devenue essentielle dans presque toutes les industries, offrant des perspectives inédites et des opportunités de croissance considérables.
Le concept de Big Data englobe bien plus que le volume de données. Il englobe également leur variété, comprenant des données structurées, non structurées et semi-structurées, ainsi que leur vélocité, représentant la rapidité à laquelle de nouvelles données sont générées et traitées. Ces trois éléments représentent les fameux 3V du Big Data.
En explorant plus en profondeur, nous découvrons que le Big Data va au-delà de la simple collecte de données. Il s’agit d’une discipline qui vise à extraire des informations significatives à partir de ces vastes ensembles de données, offrant des insights précieux pour une prise de décision stratégique et pour l’innovation.
Le traitement des données massives repose sur les fondements du calcul distribué, rendu possible par des technologies telles que MapReduce. Cette approche permet de répartir les données sur plusieurs unités de traitement, exécutant ainsi des opérations de manière simultanée, puis fusionnant les résultats pour obtenir une seule sortie consolidée.
En somme, MapReduce offre la capacité de traiter de larges volumes de données de manière efficace en exploitant la puissance de calcul distribué pour des analyses parallèles et une agrégation finale des résultats :
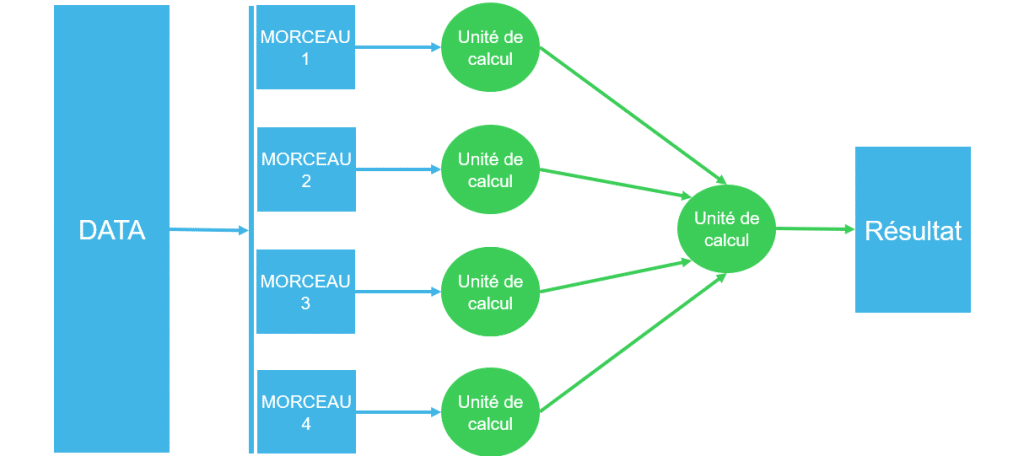
Cette convergence de facteurs pose des défis uniques aux systèmes traditionnels de gestion des données. Historiquement, la mise en œuvre de ces approches de calcul distribué a exigé des efforts considérables. Ainsi, les ingénieurs et les architectes de données sont confrontés à la nécessité de prendre des décisions cruciales concernant le nombre, le type et la capacité mémoire des unités de calcul. Objectif : mettre en place le cluster qui servira d’environnement d’exécution.
Il convient néanmoins de souligner qu’une fois le cluster créé, et en fonction de plusieurs facteurs tels que le mode de déploiement (cloud public ou privé) et le service, la modification de sa configuration peut s’avérer compliquée.
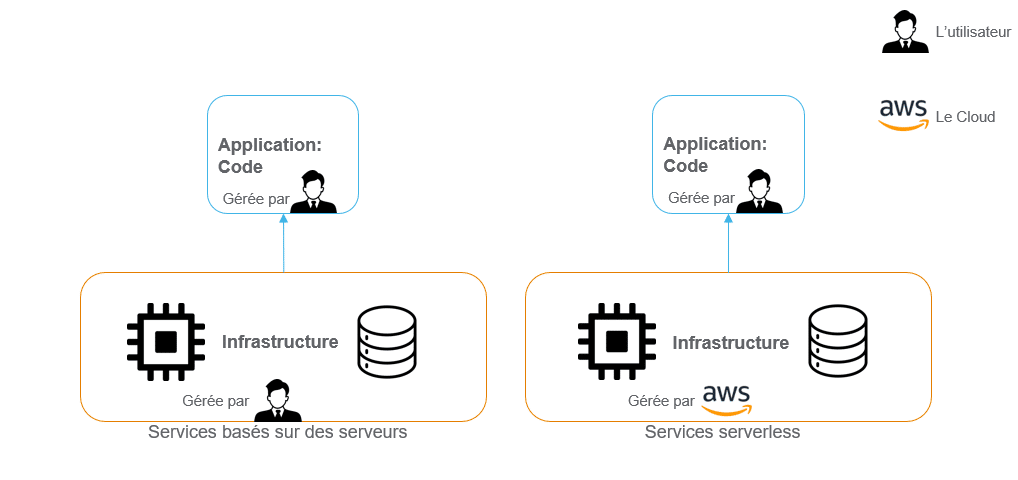
Server vs Serverless
Un serveur est un ordinateur qui fournit des services ou des ressources à d’autres ordinateurs, connu pour sa capacité à stocker, gérer et traiter des données. Avec l’avènement du cloud, la location de serveurs est devenue populaire. L’avantage pour les entreprises est de disposer de ressources informatiques à la demande, sans avoir à investir dans une infrastructure physique coûteuse.
Des services basés sur des serveurs tels qu’EC2 (Elastic Compute Cloud) et EMR (Elastic MapReduce) sont alors apparus, offrant aux utilisateurs la possibilité de louer des capacités de calcul et de traitement de données selon leurs besoins. Plus récemment, les services serverless (sans serveur) comme AWS Lambda ont émergé. Leur atout : ils permettent aux développeurs d’exécuter du code sans se soucier de la gestion des serveurs sous-jacents, offrant ainsi une approche plus flexible et évitant la gestion directe des serveurs.
Malgré les qualités des services basés sur des serveurs – parmi lesquelles, le contrôle complet sur l’infrastructure, l’adaptation aux besoins spécifiques – et leur adéquation idéale avec les charges de travail prévisibles et stables, les services serverless offrent beaucoup plus d’avantages. Par conséquent, ils ont attiré de nombreux utilisateurs du cloud à commencer leur migration vers ce type de service.
Nombre de services serverless :
- Offrent une scalabilité automatique lors des pics de charge de travail inattendus ;
- Simplifient la gestion de l’infrastructure, permettant aux équipes de se concentrer sur le développement d’application sans se soucier de la gestion et de la maintenance de l’infrastructure ;
- Et dans le cas des services de calcul, le client ne paye que pour le temps d’exécution réel du code, ce qui réduit les coûts d’utilisation du cloud.
AWS Glue, c’est quoi ?
AWS Glue offre des fonctionnalités de catalogage des données en identifiant les schémas et les transformations nécessaires pour les données, ce qui facilite la découverte et l’utilisation de ces données par d’autres services AWS. Grâce à sa capacité de Crawlers, Glue peut automatiquement découvrir et cataloguer les métadonnées de diverses sources de données, facilitant ainsi la gestion des flux de données.
Il prend également en charge plusieurs langages de programmation pour l’écriture des transformations, offrant une réelle flexibilité aux développeurs. De plus, AWS Glue est intégré à d’autres services AWS tels que S3, Redshift et RDS, ce qui facilite l’intégration et l’analyse des données à travers l’écosystème AWS. Enfin, il offre des fonctionnalités de surveillance, de journalisation et d’orchestration pour garantir la fiabilité des flux de données et automatiser le traitement.
AWS Glue s’intègre aussi nativement avec CloudWatch, il envoie automatiquement les logs et les métriques ce qui permet de faciliter le monitoring et le troubleshooting des erreurs, en plus de mettre en place des alarmes pour informer les utilisateurs des événements prédéfinis (dépassement d’un seuil pour le paiement, échec d’exécution d’un job, etc.).
En vous connectant à votre compte AWS, vous accédez à la page d’accueil. Tapez AWS Glue dans la barre de recherche :
Puis sélectionnez AWS Glue :
Comment créer un Glue job ?
Un processus ETL (Extraction, Transformation, Load) consiste à extraire des données à partir de différentes sources, à les transformer pour les rendre compatibles avec le schéma de destination, puis à les charger dans une base de données ou un entrepôt de données.
Il s’agit d’une étape cruciale dans le traitement des données, permettant de nettoyer, normaliser et restructurer les données pour une analyse ultérieure.
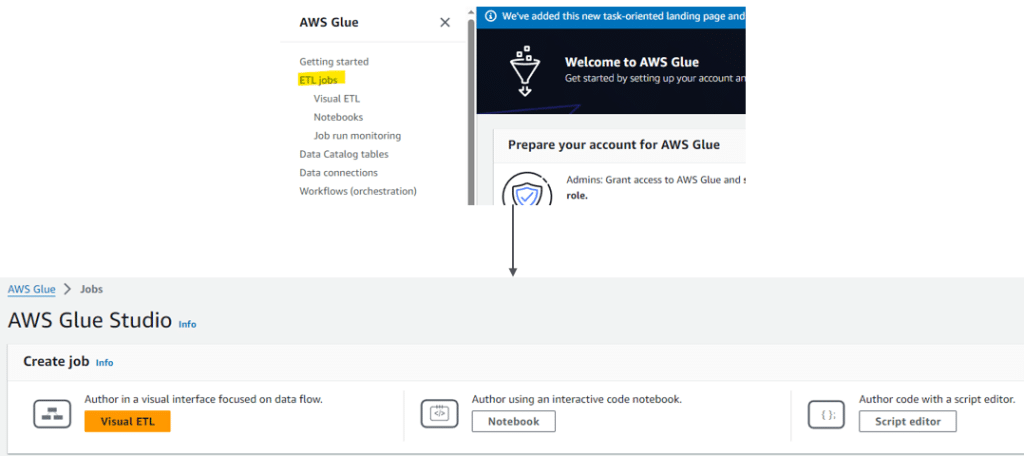
Glue offre une fonctionnalité ETL entièrement gérée par AWS. Pour créer un job, il suffit de cliquer sur ETL jobs puis sur :
- Visual ETL : pour créer son job à partir des fonctionnalités prédéfinies pour vous, et que vous pouvez glisser et déposer pour construire le graphe / schéma du job.
- Notebook : pour utiliser un notebook afin d’écrire le code de son job.
- Script Editor : pour écrire ou charger un fichier avec son propre code qui sera utilisé comme code source pour le job.
Glue job en Python avec Script editor
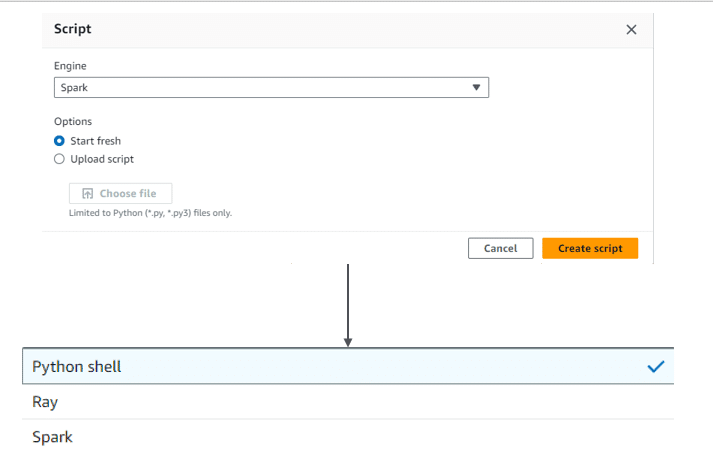
En cliquant sur Script editor, vous tombez sur la première fenêtre qui nous permet de configurer son job.
Choisissez Python Shell et Start fresh. Si vous avez un script Python déjà écrit, vous pouvez le télécharger en cliquant sur Upload script :
Ensuite, un éditeur de texte s’ouvre vous permettant d’écrire un code Python normal :
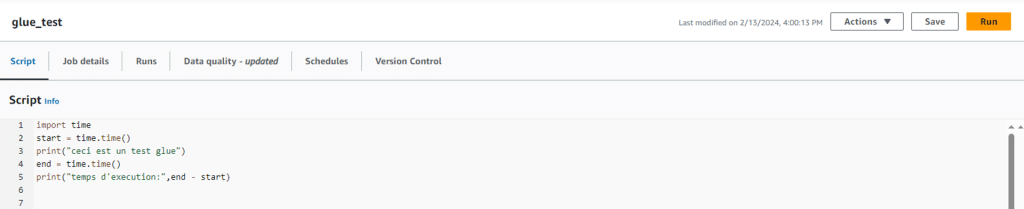
- glue_test : le nom de votre job
- Script : le code source
- Job details : des paramètres de configuration
- Save : enregistrer le code source de votre job
- Run : exécuter le job
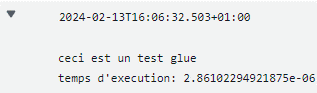
Après avoir écrit votre code, en cliquant sur Save puis Run, le job va commencer à s’exécuter :
Les paramètres les plus importants à renseigner dans l’onglet « job detail » sont :
- IAM roles : le rôle qui sera utilisé par le job pour exécuter ses tâches. Par exemple : si vous avez besoin d’accéder à S3, le rôle utilisé doit contenir cette permission.
- Data Processing Units : 1 DPU = 4vCPU et 16 Gb de mémoire, vous pouvez faire le choix entre 1 DPU et 1/16 DPU pour les jobs en Python.
- Script filename : le nom que vous voulez attribuer à votre script principal (se terminant par .py).
- Script path : le chemin de stockage du script principal (exemple s3://bucket-name/folder_name/).
- Job Timeout (minutes) : le temps maximal d’exécution d’un job (par défaut 2880 minutes = 48 heures).
Des paramètres supplémentaires peuvent être utiles à mettre en place :
- Libraries : Glue offre déjà la majorité des bibliothèques Python. Or, si vous avez besoin d’un module qui n’est pas inclus par défaut, ou que vous voulez construire votre propre module, vous pouvez le télécharger en S3 sous format Wheel et intégrer le chemin dans ce paramètre.
- Referenced files path : si vous souhaitez faire référence à d’autres fichiers Python (qui contiennent par exemple des fonctions que vous utilisez dans le script principal), vous pouvez mettre les chemin S3 de ces fichiers en les séparant par une virgule.
Glue job en Spark avec Visual ETL
? Découvrez comment optimiser vos jobs Apache Spark en maîtrisant les shuffles. Cet article d’Abdelwahab Touil vous dévoile les clés pour améliorer les performances de vos traitements Big Data. Ne manquez pas ces conseils essentiels pour des exécutions plus rapides et efficaces !
A retrouver ici : Comprendre comment Spark traite les shuffles
Si vous n’êtes pas très à l’aise avec l’écriture du code, ou si vous souhaitez mettre en place un ETL avec des fonctionnalités basiques et simples, utiliser Visual ETL vous offre plusieurs fonctionnalités prêtes à l’emploi. Il suffit de glisser la source des données, les transformations et la cible là où vous chargez les données.
Après avoir cliqué sur Visual ETL, on peut glisser les nœuds pour construire notre diagramme. D’abord, il est nécessaire de définir une source de données :
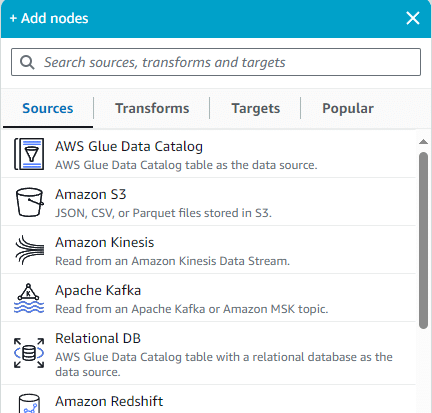
Dans ce cas, j’ai choisi AWS Glue Data Catalog. Ce metastore intégré dans Glue permet de requêter des données S3 en utilisant SQL, parmi d’autres fonctionnalités. Une fois le choix effectué, il faut alors spécifier la base de données et la table d’où les données sources seront extraites.
Ensuite, on peut ajouter autant de transformations qu’on veut, qu’il s’agisse de transformations prédéfinies ou personnalisées :
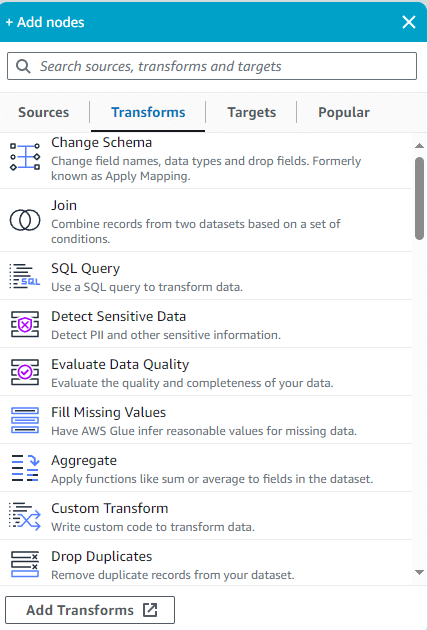
Finalement, on définit une cible (targets) où les données seront chargées pour finir le cycle ETL.
Voici un Glue job en Spark dessiné en utilisant Visual ETL. Cette méthode permet d’extraire les données depuis Glue Data Catalog à partir de fichiers CSV, de supprimer les valeurs nulles et d’écrire le résultat dans S3 sous format parquet :
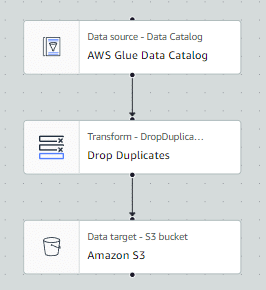
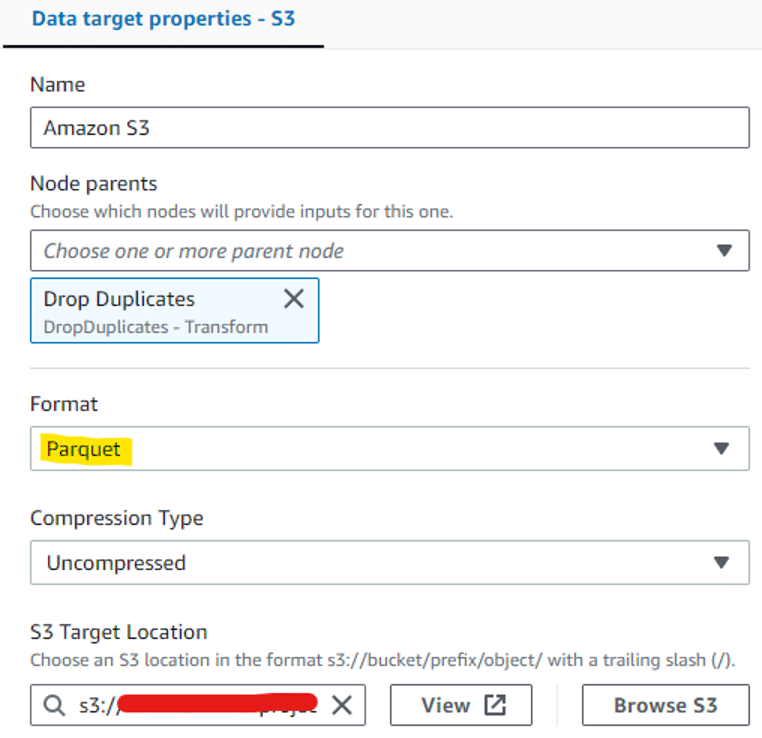
Il est également possible de voir le code correspondant en passant de l’onglet Visual à l’onglet Script :
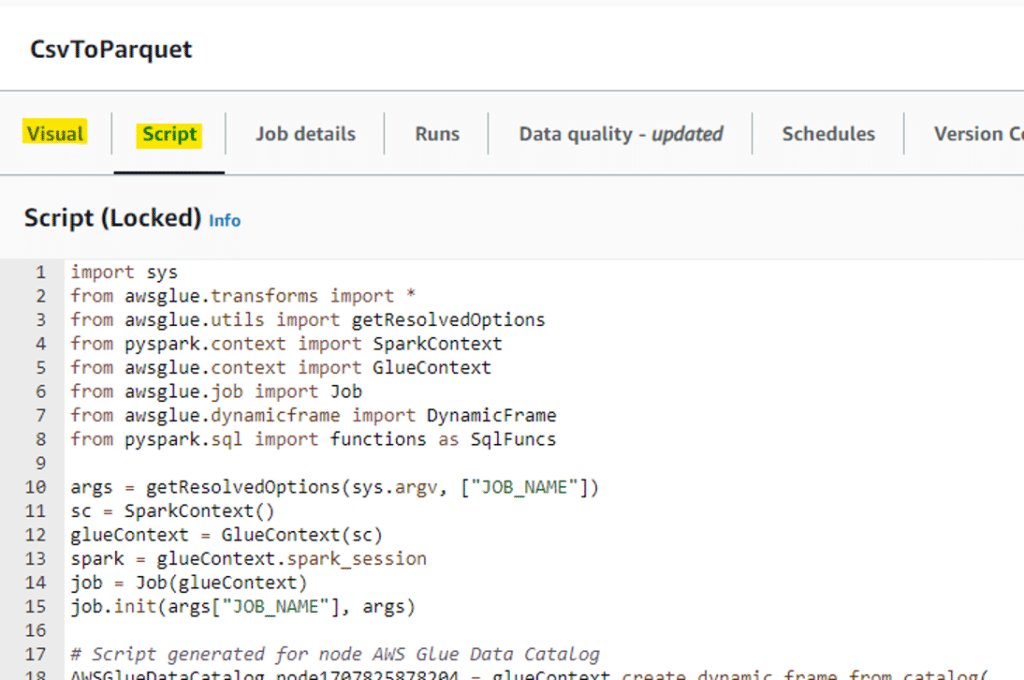
De la même façon, si vous souhaitez l’exécuter, vous devez sauvegarder les changements en cliquant sur « Save », puis sur « Run » pour le lancer.
Dans job details, il est nécessaire de spécifier le type et le nombre de nœuds qui vont servir comme infrastructure pour exécuter le code selon les besoins :
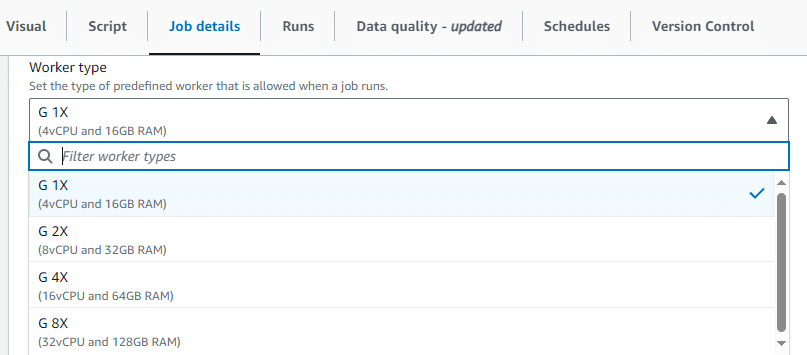

Ainsi, en quelques minutes, il est possible de déployer un ETL avec plusieurs transformations, en utilisant du Spark sans avoir à mettre en place une infrastructure qui supporte ce type de calcul lourd.
Monitoring des Glue jobs
AWS Glue offre un excellent niveau de surveillance pour les jobs Python Shell et Spark. Il s’intègre parfaitement avec Amazon CloudWatch, offrant la possibilité de visualiser les logs et les métriques pour suivre les performances des jobs.
? Découvrez les 5 vulnérabilités de sécurité les plus courantes en Python et comment les éviter. Injection SQL, shell, fuites de clés API… Apprenez à sécuriser votre code et à protéger vos données sensibles. Ne laissez pas une faille compromettre votre travail.
Lisez l’article maintenant !
L’accès aux logs peut s’effectuer de plusieurs manières. Après avoir exécuté le job, et en cliquant sur Run details :
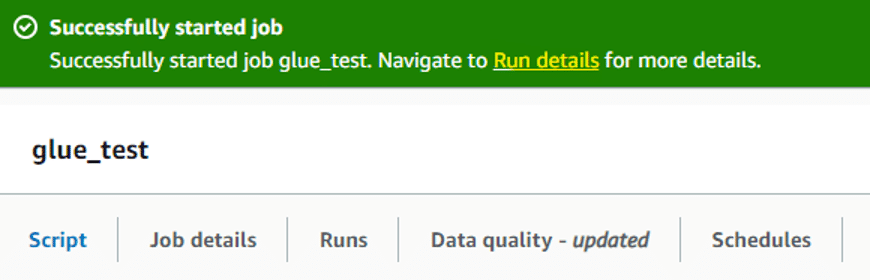
On trouve l’espace monitoring pour ce job spécifiquement, avec l’historique des anciennes exécutions :
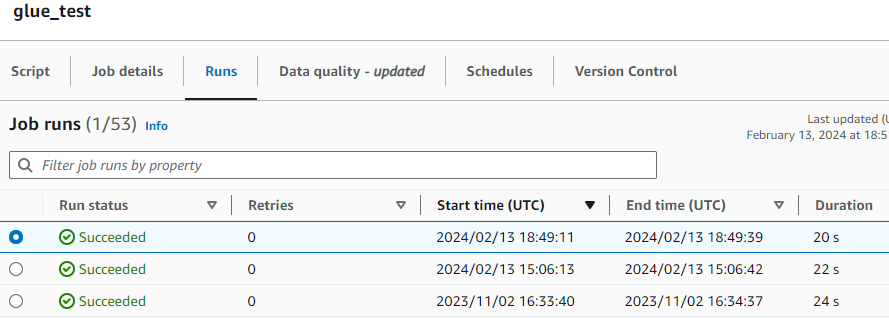
Il est possible ainsi d’accéder à la fois aux logs d’exécution et aux logs d’erreur en naviguant en bas et en cliquant sur l’une des deux options dans l’onglet run details :

On peut également surveiller l’historique complet de l’exécution de tous les jobs en accédant à la section « Job run monitoring » :
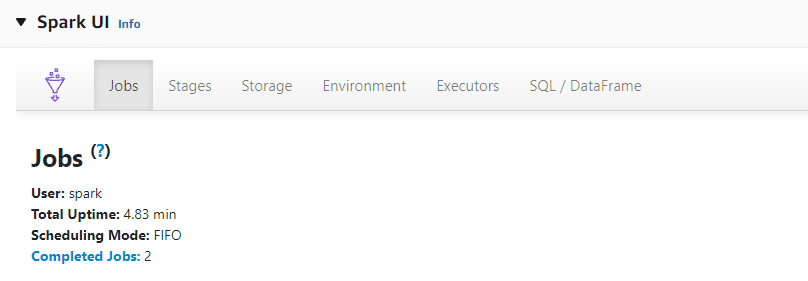
De plus, AWS Glue donne accès à l’interface utilisateur de Spark (Spark UI), offrant ainsi la possibilité de déboguer et d’optimiser les jobs Spark grâce à une visibilité détaillée sur les opérations et sur les ressources utilisées, et d’accéder aux logs d’exécution en temps réel :
Conclusion
En conclusion, le serverless offre une approche flexible et évolutive pour le déploiement d’applications, avec une gestion automatisée des ressources. AWS Glue se distingue par sa facilité d’utilisation et son intégration transparente avec les services AWS, simplifiant ainsi le traitement des données. Cependant, malgré ses avantages, AWS Glue reste loin d’être parfait et peut nécessiter des améliorations continues pour répondre aux besoins complexes de certains cas d’utilisation.

Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.
Références
- https://aws.amazon.com/fr/glue/
- https://aws.amazon.com/fr/glue/pricing/
- https://aws.amazon.com/fr/about-aws/whats-new/2023/11/aws-glue-serverless-spark-ui-observability-metrics/



Pas encore de commentaires