
Aujourd’hui, on entend beaucoup parler des technologies Big Data : les chefs de projets en parlent et souhaitent expérimenter l’apport de ces technologies en termes de scalabilité, les commerciaux parlent de missions Big Data et de DataLab chez les clients, les RH cherchent des experts Big Data et des développeurs Hadoop qu’ils n’arrivent pas facilement à trouver.
Un nombre très important de frameworks Big Data a vu le jour ces dernières années et l’écosystème Big Data est en pleine effervescence. Cependant, compte tenu du manque de maturité de son écosystème, plusieurs frameworks disparaissent à cause de leur complexité ou non adéquation avec les nouveaux besoins.
Nous allons, à travers cet article, introduire Apache Hive, un framework Big Data pour l’analyse des données. Son utilité : proposer une abstraction en dessus de MapReduce pour faciliter l’analyse de gros volumes de données. Ses atouts : de nombreux projets en production, une communauté active et un rythme de release assurant la compatibilité avec les nouvelles versions de Hadoop.
C’est quoi, le Big Data ?
Le Big Data, ce n’est pas uniquement une question de volume de données. Il est lié aux trois V : Volume, Vélocité et Variété.
La vélocité se réfère à la vitesse avec laquelle de nouvelles données sont créées. La variété, quant à elle, se réfère aux types de données générées. Cependant, on considère que le seuil à partir duquel on « fait du BigData » est celui à partir duquel les approches classiques ne sont plus utilisables à coût raisonnable. En pratique, on juge qu’à partir de 10 To de données, on est dans le Big Data. Ce seuil varie aussi en fonction de la complexité des données.
Aujourd’hui, l’enjeu est devenu d’exploiter plus de données, plus vite, qu’elles soient déjà connues, ou issues de nouvelles sources à combiner aux existantes pour leur donner un contexte plus riche. C’est dans ce cadre qu’est apparu Hadoop, en proposant une solution innovante pour stocker et analyser de gros volumes de données de façon scalable, tout en maîtrisant son budget.
Hadoop, c’est quoi ?
Hadoop est un framework libre et open source pour le développement d’applications scalables distribuées. Il permet le traitement distribué de gros volumes de données sur un cluster de plusieurs centaines (ou milliers) de machines standards qu’on appelle commodity hardware. Il se base sur :
- HDFS (Hadoop Distributed File System) pour la partie stockage de données,
- MapReduce, qui est un modèle de programmation (avec une implémentation associée) inventé par Google pour le traitement parallèle et distribué des données sur un cluster.
En général, plus le modèle de données se complexifie, plus l’écriture d’un job MapReduce qui les manipule devient fastidieuse. Si nous prenons le simple exemple du Word count que nous trouvons sur la documentation officielle de Hadoop, l’implémentation Java7 fait une centaine de lignes environ avec :
- 15 lignes pour le mapper,
- 12 lignes pour le reducer,
- 35 lignes pour le setup ainsi que les méthodes utilitaires pour le parsing des données en entrées,
- 30 lignes pour le main.
Oui, tout ça pour un Word Count avec MapReduce !
Afin de faciliter l’analyse de données stockées dans HDFS sans passer par la complexité de MapReduce, certains frameworks comme Pig, Hive sont apparus. Ils proposent des langages de haut niveau pour lancer des requêtes ad-hoc sur HDFS.
Quel framework pour analyser son Big Data ?
Pig est bien adapté aux données non structurées, dont la structure change rapidement (appelées également “Moving Data”). Il est très proche du monde de l’ETL (Extract Transform Load) où des données non structurées sont reformatées et leur structure est définie a posteriori.
L’avantage de Hive est de définir une structure sur une variété de formats de données facilitant ainsi la possibilité de les requêter. Il est donc bien adapté à un contexte d’analyse de données. Hive propose aussi une fonction de stockage distribué et permet d’accéder à des fichiers stockés dans HDFS (ou dans d’autres systèmes comme Apache HBase).
En terme de langage, Hive propose HiveQL, un langage déclaratif, similaire à SQL alors que Pig propose Pig Latin, un langage de flux de données orienté pour un mode “exploration” de gros volumes de données.
C’est quoi, HIVE ?
Apache Hive est un datawarehouse pour Hadoop. Il a été créé par Facebook pour devenir par la suite un projet Apache open source. Il ne s’agit pas d’une base de données relationnelle ni d’un datawarehouse classique.
Si Hive n’est pas une base de données ni un datawarehouse, qu’est-ce donc alors ?
Il s’agit d’un système qui maintient des métadonnées décrivant les données stockées dans HDFS. Il utilise une base de données relationnelle appelée metastore (Derby par défaut) pour assurer la persistance des métadonnées. Ainsi, une table dans Hive est composée essentiellement :
- D’un schéma stocké dans le metastore,
- De données stockées dans HDFS.
Avec les données du metastore, Hive permet de manipuler les données comme si elles étaient persistées dans des tables (au sens d’un système de gestion de base de données classique) et de les interroger avec son langage HiveQL.
Hive permet de convertir les requêtes HiveQL en jobs MapReduce ou Tez (à partir de la version 0.13 de Hive, une requête HiveQL peut être traduite en un job exécutable sur Apache Tez, qui est un framework d’exécution sur Hadoop pouvant remplacer MapReduce).
Ainsi, des profils familiers avec SQL (analystes, data scientists, etc.) n’ayant pas un background de développeur pourront écrire leurs requêtes HiveQL pour exploiter les données stockées dans HDFS sans se soucier de la partie programmatique de jobs.
D’un point de vue syntaxe, Hive supporte les clauses SQL standards (cf. Fig 1) ainsi que les commandes de définition de structure (DDL – cf. Fig 2).
INSERT INTO SELECT FROM … JOIN …. ON WHERE GROUP BY HAVING ORDER BY LIMIT
Figure 1 : Clauses SQL standards supportées par HiveQL
CREATE / ALTER / DROP TABLE / DATABASE
Figure 2 : Exemple de commandes de définition de structure avec HiveQL
D’un point de vue performance, Hive n’est certainement pas conçu dans une vision d’amélioration des performances d’exécution des jobs. En effet, les requêtes HiveQL (et donc job MapReduce ou Tez derrière) ne sont pas exécutées en temps réel et peuvent prendre quelques minutes ou quelques heures pour être exécutées. Ainsi, l’avantage principal de Hive reste sa capacité d’abstraction par rapport à MapReduce.
Architecture de HIVE
Pour illustrer le fonctionnement de Hive et son architecture, nous allons décortiquer l’exécution d’une requête Hive. En effet, l’interaction Hive/Hadoop s’effectue selon les trois étapes suivantes :
- Envoi de la requête HiveQL : en utilisant un client Hive (le client shell, un client JDBC/ODBC ou une interface web), la requête est envoyée au serveur Hive,
- Planification de la requête : la requête est reçue par le driver (pilote). Elle est compilée, optimisée et planifiée comme un job,
- Exécution du job : le job est exécuté sur le cluster Hadoop.
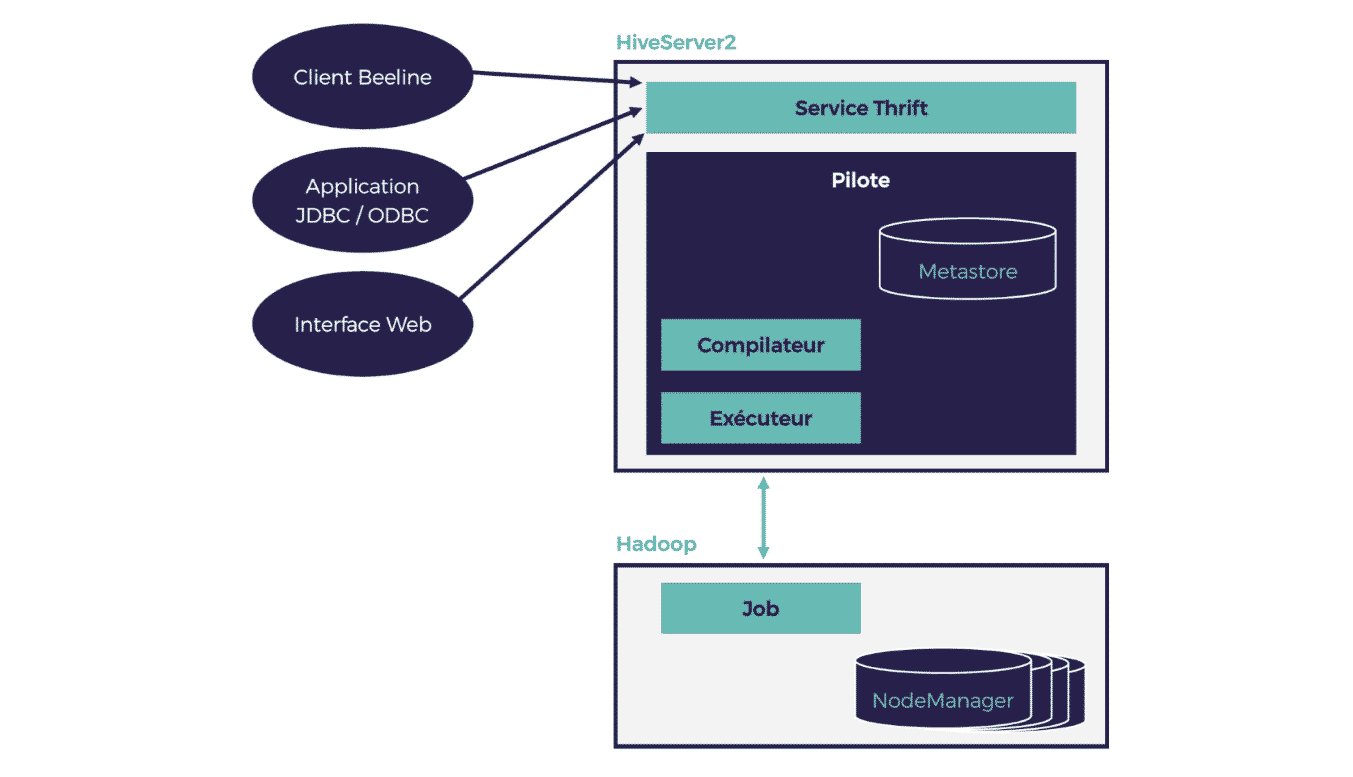
Figure 3 : Architecture de Hive
Partie (1) : la partie client
Il est possible de soumettre des requêtes au serveur Hive de différentes manières. En utilisant :
- Le client Hive CLI (Hive Commande Line Interface) qui permet d’entrer des commandes directement depuis le shell hive ou d’exécuter un ensemble de commandes Hive écrites dans un fichier texte. Ce client n’est pas compatible avec la nouvelle version de Hive (HiveServer2) et a été remplacé par Beeline qui est le nouveau client en mode ligne de commande de Hive. Il communique avec HiveServer2 via thrift,
- Le client JDBC/ODBC,
- Le client web.
Partie (2) : la partie serveur
Appelé HiveServer2 qui succède à HiveServer (devenu deprecated à partir de la version 1.0.0). Il s’agit du conteneur du moteur d’exécution de Hive et appelé couramment pilote (ou driver). Il se compose du metastore, du compilateur et de l’exécuteur.
HiveServer2 assure deux nouvelles fonctionnalités : la gestion de l’authentification client et la gestion des requêtes concurrentes. Pour chaque connexion client, HiveServer2 crée un nouveau contexte d’exécution (connexion + session). La nouvelle interface RPC de HiveServer2 permet au serveur d’associer le contexte d’exécution Hive avec le thread qui sert la requête client. Cette interface implémente un service thrift pour communiquer avec les clients et exécuter leurs requêtes.
Partie (3) : Hadoop
Correspond à l’exécution du job sur le cluster Hadoop.
Tables, partitions et requêtes dans Hive
Tables et chargement des données dans Hive
Une table dans Hive permet d’associer une structure à des données non structurées dans HDFS. La création d’une table dans Hive est similaire à la création d’une table dans un RDBMS et s’effectue avec la commande CREATE TABLE.
Il existe dans Hive deux types de tables :
1) Managed table,
2) External table.
Hive Managed table et External table
Dans Hive, une Managed table est similaire à une table au sens RDBMS. La différence entre une Managed table et une External table est la gestion des données lorsque la table est supprimée.
En effet, la suppression d’une Managed table entraîne la suppression des métadonnées ainsi que les données dans HDFS (pour notre exemple, les données sont stockées dans HDFS par défaut sous /apps/hive/warehouse/product). En revanche, la suppression d’une External table entraîne uniquement la suppression des métadonnées. C’est bien pratique, une External table est un moyen de protéger les données contre les commandes drop accidentelles.
hive > CREATE TABLE product ( productId INT, productName STRING, productCategory STRING, valuationDate TIMESTAMP, validTillDate TIMESTAMP) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ ;
Figure 4 : Commande HiveQL pour la création d’une managed table product ayant 5 colonnes (productId, productName, productCategory, valuationDate, validTillDate)
Hive permet aussi de spécifier l’emplacement de stockage de données dans HDFS et ne pas se limiter à l’emplacement de stockage par défaut. Ceci est possible en ajoutant la clause LOCATION lors de la création table (cf. Fig 5).
hive > CREATE EXTERNAL TABLE product-ext ( productId INT, productName STRING, productCategory STRING, valuationDate TIMESTAMP, validTillDate TIMESTAMP) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ LOCATION ‘/user/BigDataLab/Hive_part1/products’ ;
Figure 5 : Commande HiveQL pour la création d’une external table product-ext avec spécification de l’emplacement de stockage de donnés dans HDFS
Chargement des données dans une table Hive
Un des points forts de Hive réside en sa capacité d’associer des métadonnées aux données. La source de ces données peut être le système de fichiers ou HDFS. Pour cela, il faut utiliser la commande LOAD DATA. Comment ce chargement s’effectue ?
Réellement, les données ne sont pas chargées mais déplacées (comme s’il s’agit d’un mv sous Linux).
Pour une Managed table : les données sont déplacées dans un sous répertoire de /apps/hive/warehouse qui est le répertoire racine par défaut (cf. Fig 6). Le mot clé LOCAL signifie que le fichier d’entrée est dans le système de fichiers local. Si LOCAL est omis, il s’agit d’un fichier d’input dans HDFS.
Le mot clé OVERWRITE signifie que les données (si elles existent) dans la table product seront supprimées. Si OVERWRITE est omis, les données seront ajoutées (mode append) aux données existantes.
hive> LOAD DATA LOCAL INPATH '/tmp/product.txt' OVERWRITE INTO TABLE product ;
Figure 6 : Commande HiveQL pour charger les données depuis un fichier d’entrée dans le système de fichiers dans la table product avec écrasement des données existantes
Pour une External table : les données sont déplacées dans le répertoire spécifié dans la clause LOCATION de la définition de la table (cf. Fig 7). Pour cet exemple, le fichier d’entrée product-ext.txt sera déplacé dans /user/BigDataLab/Hive_part1/products puisqu’il s’agit de l’emplacement défini lors de la création de la table (cf. Fig 5).
hive> LOAD DATA INPATH '/user/training/product-ext.txt' INTO TABLE product-ext ;
Figure 7 : Commande HQL pour charger les données depuis HDFS dans la table product-ext
Gestion des partitions
Partitionner une table dans Hive implique une séparation des fichiers selon la colonne (ou les colonnes) définissant la clé de partition. Le partitionnement peut améliorer les performances des requêtes HiveQL puisque les fichiers dans HDFS sont déjà séparés en se basant sur la valeur de la colonne. Cette séparation peut réduire le nombre de mappers et réduire ainsi le nombre des opérations de shuffle/sort du job résultant. La définition d’une partition est similaire à sa définition en SQL :
CREATE TABLE product_partitioned ( productId INT, productName STRING, valuationDate TIMESTAMP, validTillDate TIMESTAMP) partitioned by (productType STRING) ;
Figure 8 : Commande HiveQL pour la création d’une table product partitionnée par le champ productType
Dans HDFS, nous aurons une structure de données en sous-répertoire par productType sous /apps/hive/warehouse/product_partitioned :
/apps/hive/warehouse/product_partitioned /productType=bond/ /productType=future/ /productType=forward/ /productType=option/
Figure 9 : Structure de données partitionnées dans HDFS
Conclusion
Nous avons introduit à travers cet article Apache Hive, son architecture et son langage de requête HiveQL qui est très similaire à SQL.
Ce framework apporte une grande facilité pour l’interrogation des données stockées dans HDFS en faisant une abstraction par rapport à MapReduce. Grâce à HiveQL, l’analyse des gros volumes de données devient aussi simple que le requêtage d’une base de données relationnelle avec SQL.
Les avantages de Hive par rapport aux autres frameworks d’analyse de données Big Data sont principalement : sa maturité, la communauté active qui l’utilise, ainsi que sa compatibilité avec les nouvelles versions de Hadoop.
Hive propose d’autres fonctionnalités plus avancées comme le tri et les jointures (plusieurs types de jointures comme le Shuffle Join, le Broadcast Join et le SMB Join sont définies dans Hive). Hive est aussi flexible grâce aux UDF (User Defined Function) qui sont des fonctions définies par l’utilisateur permettant d’étendre le langage et pouvant être ré-utilisées comme s’il s’agissait d’une bibliothèque externe.
Un second article sur le même sujet sera dédié à la présentation et l’utilisation des fonctionnalités avancées de Hive.

Vos commentaires
j’ai vraiment aimé cette brèf présentation d’apache hive. j’espère que la suite sera plus intéressante. merci
Article très intéressant Mr Sakka 🙂
merci beaucoup c’est vraiment intéressant votre bref présentation et bon courage