
Pour le salon Big Data 2017, j’ai décidé cette année d’assister aux conférences payantes, en espérant y voir plus de choses techniques. Bien m’en a pris, ce sont celles qui m’ont le plus intéressé. J’y ai découvert un tout jeune top projet Apache, Apache Beam, un modèle de programmation qui permet aux développeurs de créer des pipelines de traitement de la donnée sans se soucier du moteur d’exécution.
Pour bien saisir l’intérêt d’Apache Beam (pour Batch & Streaming), il faut comprendre ce qui a conduit à sa création début 2016. Avec MapReduce (Google) lancé en 2004, de nombreux outils ont été développés afin de donner aux utilisateurs plus de contrôle sur leurs données. Ce panorama d’outils va de l’ingestion des données à leur stockage en passant par leur traitement, que ce soit en mode batch ou streaming. Seulement, le nombre toujours plus important d’outils apporte son lot de spécificités, de façon de coder, de façon de représenter ces « pipelines » de traitement de la donnée.
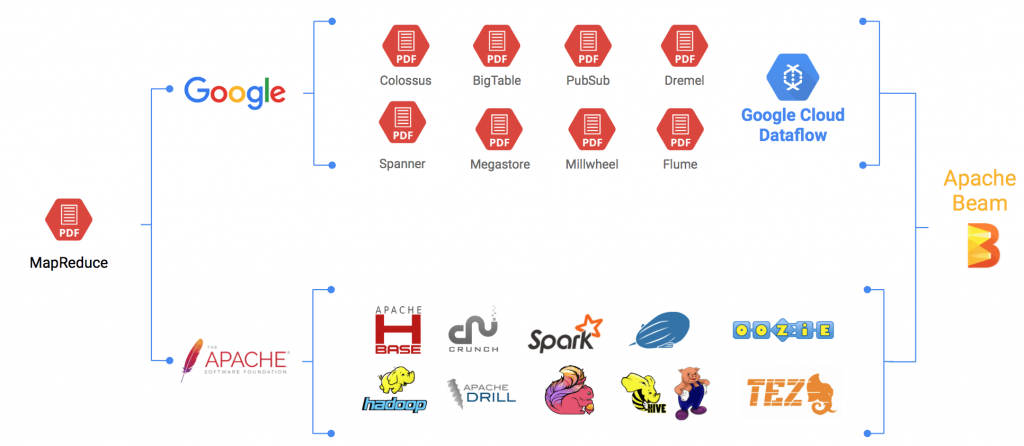
Les plateformes Google et Apache pour le traitement des données
Apache Beam, propose d’unifier tous ces outils. Il n’a donc clairement pas vocation à être un outil « Big Data » supplémentaire mais à se placer « au-dessus » des autres pour fournir un modèle de programmation agnostique afin de créer des pipelines de traitement de la donnée sans se soucier du moteur d’exécution sous-jacent choisi (Spark, Flink, Apex ou même le Google Cloud Dataflow).
Apache Beam c’est donc : un modèle de programmation unifié que ce soit pour les traitements batch ou streaming, une portabilité des pipelines (un pipeline créé peut-être lancée sur Spark, Flink, Apex ou Dataflow), et enfin un environnement en constante évolution permettant l’ajout de nouvelles API (pour l’instant uniquement Java et Python) ou de de nouveaux connecteurs (Hadoop, Hbase, Kafka, TextFile, …).
Un exemple d’utilisation
Un exemple simple et qui parle à tout le monde serait un pipeline de type ETL (pour Extract-Transform-Load). En effet, il est très simple d’assimiler ces principes aux technologies proposées par Apache Beam.

Exemple de traitement ETL possible avec Apache Beam
Dans le schéma présenté ci-dessus, c’est à l’étape de transformation qu’Apache Beam montre toute sa flexibilité, ce qui offre plusieurs avantages, parmi lesquels :
- gain de temps considérable si l’on décide de changer de moteur d’exécution puisque pas de ré-implémentation à prévoir,
- possibilité de comparer très simplement les performances de différents moteurs d’exécution pour un pipeline donné.
Des concepts simples…
Concrètement, Apache Beam repose sur trois concepts essentiels, Pipeline, PCollection et PTransform.
Pipeline encapsule toutes les étapes des traitements à réaliser. Cela inclut la lecture des données, leur transformation mais aussi leur écriture en sortie.
PCollection représente une collection de données potentiellement distribuée. Son concept peut aisément être rapproché des RDD en Spark pour ceux qui en sont familiers. C’est à ce niveau-là que sera abstrait le côté batch du côté streaming, passant intuitivement de l’un à l’autre selon que la source des données lues soit un fichier, une base de données ou bien une file de messages.
Enfin, PTransform représente tout simplement une fonction prenant en entrée une ou plusieurs PCollection et retournant une PCollection qui sera utilisée pour l’étape suivante du Pipeline. On peut rapprocher ce principe des Transformer Spark, à ceci près que ces derniers ne traitent qu’une collection (Dataframe) à la fois.

Exemple d’un pipeline simple avec Beam : lecture, transformation puis écriture
… mais limités ?
Après la phase d’euphorie du néophyte qui découvre une technologie en apparence prometteuse, vient la phase où l’on se demande si ce qu’on essaye de nous vendre n’est pas en réalité une chimère. En effet, si de prime abord la solution paraît simple et bien pensée, dans la pratique, elle n’est pas exemptes de limites.
Premièrement, Apache Beam est relativement jeune (passage en « top project » Apache le 10 janvier 2017). Il ne fournit donc pas encore un catalogue étendu de fonctionnalités par rapport à celles que proposent les moteurs d’exécution qu’il est censé abstraire. Il s’agit là d’un critère décisif pour son adoption. A titre personnel, je travaille actuellement dans un DataLab sur des questions de Machine Learning et je ne pourrais pas l’utiliser car les fonctionnalités dont j’ai besoin ne sont pas encore disponibles. Je me dois donc de rester sur du Spark (ou autre).
Deuxièmement, quid de l’optimisation ? Prenons l’exemple de Spark. Lors de traitements, la façon dont le développeur décide d’enchaîner ses transformations, de mettre en cache ou non ses données, comment il les partitionne, joue un rôle déterminant dans la performance finale de son pipeline. Dès lors, avec une API haut niveau (puisque devant répondre à chaque outil) comme celle que propose Beam, comment faire pour favoriser un tel niveau de tuning ? Par exemple, j’ai bien trouvé dans l’API d’Apache Beam un moyen de partitionner les données. En revanche, aucun moyen de les mettre en cache (ou en tout cas, ça n’est pas à la liberté du développeur).
Par ailleurs que fait-on des spécificités de chaque technologie ? Apache Beam prônant un modèle unifié, il ne semble alors pas logique d’avoir accès à des fonctionnalités n’étant présentes que dans tel ou tel outil. Que reste-t-il comme possibilités ? Effacer les différences entre les outils ? C’est le fondement même de leur existence, proposer une alternative. La question reste à creuser.
Une question de temps ?
En définitive, Apache Beam semble être un projet prometteur (un de plus !), avec des idées intéressantes et une communauté en croissance. C’est l’apanage des nouveaux projets de souffrir de quelques limites. Il faudra encore de longs mois avant d’avoir une vision plus large des fonctionnalités offertes et de constater si Apache Beam est capable de lever les hypothèses soulevées plus haut.

Pas encore de commentaires