
Après notre précédent article dédié au concept et au fonctionnement des RAG, nous vous proposons dans ce 2ème article de notre série d’entrer dans le monde merveilleux du RAG avancé et de découvrir une recette pour dynamiser les performances du RAG.
Les RAG (Retrieval Augmented Generation) permettent d’enrichir les modèles de langage en leur apportant des informations supplémentaires avant que ces derniers ne génèrent leurs réponses. La version la plus connue du RAG est sa version naïve qui repose sur l’idée que les questions posées par les utilisateurs utilisent des expressions sémantiques proches des réponses attendues.
Cependant, les chercheurs du domaine n’ont pas pu se contenter de cette version fade à leur goût. On peut alors imaginer mille et une techniques pour pimenter les performances du RAG.
Quelles sont les limites de la version naïve du rag ?
Limite de la recherche sémantique
La version naïve, bien que plutôt performante, rencontre des difficultés à traiter certaines requêtes. C’est le cas pour les requêtes qui attendent une réponse éloignée sémantiquement. En effet, sur une requête type « Fais-moi un résumé de tes trois documents les plus courts », il n’est absolument pas pertinent de chercher des passages textuels sémantiquement similaires à la requête.
Sur un exemple comme celui-ci, le RAG naïf va récupérer des chunks avec des idées proches des mots « résumé » et « document » alors qu’on aimerait avoir les chunks des trois documents les plus courts. Même si les modèles actuels n’effectueront pas la tâche bêtement en effectuant juste un résumé de ces chunks, ils n’auront pas les bonnes informations pour traiter convenablement la requête.
Impact de la longueur des requêtes
La version naïve a également du mal à fournir des résultats concluants lorsque les requêtes sont trop longues. Cela vient du fait qu’une requête longue introduit des mots dissociés du sens de la réponse attendue. Par conséquent, l’embedding de la requête va avoir du mal à créer un vecteur pertinent et proche des chunks qu’il faudrait normalement récupérer.
Impact du nombre de documents
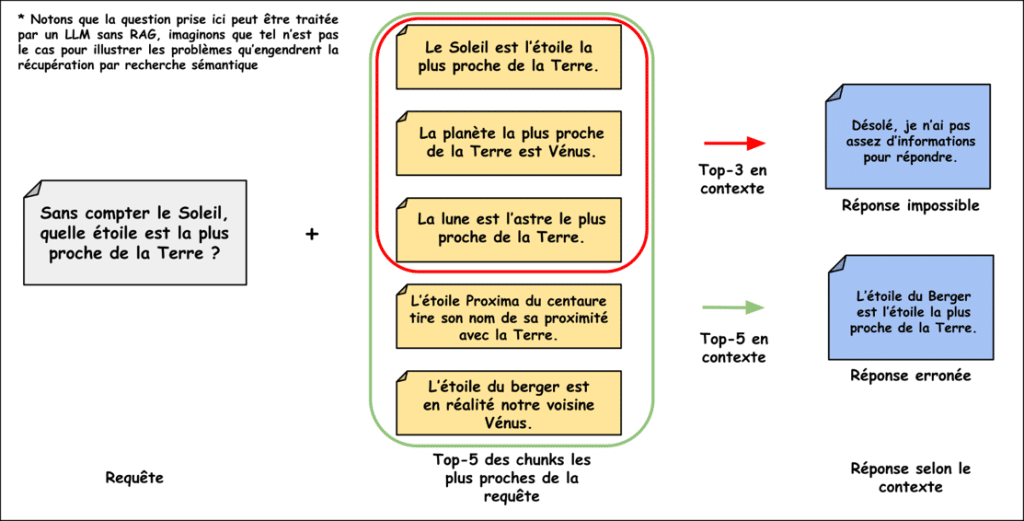
Lorsque le nombre de documents devient important, la version naïve trouve une fois de plus ses limites. En effet, plus il y a de documents dans la base de données, plus il y a des chunks sémantiquement proches, ce qui pose un problème lors de la phase de récupération. Par exemple, si l’information recherchée se trouve dans un seul chunk, deux risques sont encourus :
- Le premier est de sous-informer le LLM en lui donnant en contexte le top-k des chunks les plus proches de la requête alors que l’information n’est pas contenue dans un de ces k chunks.
- Le deuxième est de mal-informer le LLM en récupérant parmi ce top-k des chunks, des informations contradictoires, ce qui va détériorer la réponse finale.
L’absence de sémantique claire
Citons un dernier problème que rencontre le RAG naïf, c’est celui des noms propres. Le problème des noms propres est qu’ils n’ont pas vraiment de sémantique à proprement parler. Une recherche d’un RAG naïf à propos d’un nom propre a donc peu de chance d’aboutir. Par exemple, une fois vectorisé, le nageur français « Léon Marchand » se retrouvera beaucoup plus proche du mot « commerçant » que du mot « nageur ».
RAG avancé : Comment les techniques évoluent pour améliorer les réponses des modèles de langage ?
À cette étape, il est humain de douter de la pertinence du RAG devant le nombre de problèmes auxquels ce dernier est confronté. Pourtant, c’est ici que la plus belle partie commence. Si le concept de RAG naïf est gravé dans la roche, ce n’est pas le cas pour le concept de RAG lui-même qui, à l’heure actuelle, fait travailler les cerveaux de nombre de spécialistes de l’IA générative.
L’appellation de « RAG avancé », ou Advanced RAG, désigne tous les types de RAG dont la trame séquentielle est similaire au RAG naïf mais dans lesquels de nombreuses techniques sont mises en œuvre pour améliorer la qualité des résultats obtenus.

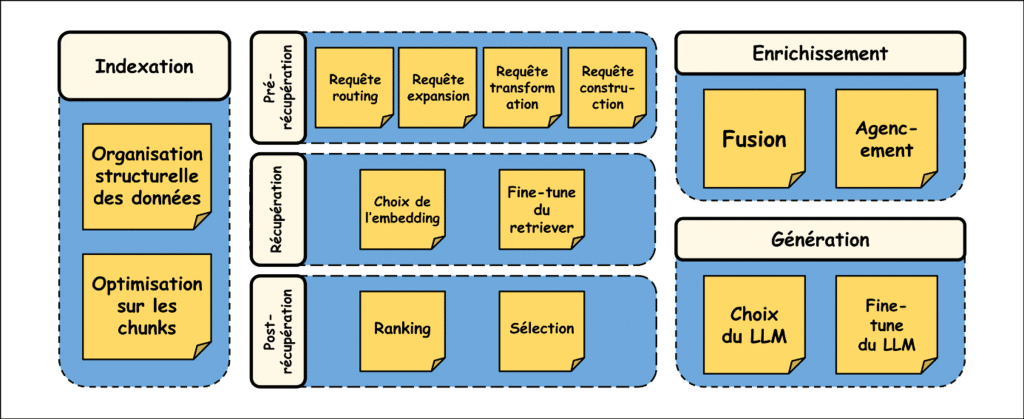
Optimisation de la phase d’indexation
Pour la phase d’indexation, l’idée maîtresse reste d’utiliser un vector store pour pouvoir comparer par la suite la requête avec les vecteurs stockés et récupérer les chunks pertinents. Il existe deux axes distincts pour améliorer cette partie :
- Mieux exploiter l’information provenant des chunks ;
- Et mieux organiser les informations.
Pour tirer profit des chunks de meilleure manière, une méthode couramment utilisée est appelée small-to-big. Elle consiste à découper les textes originaux en chunks très courts (small) mais à donner en contexte au LLM des chunks très longs (big).
Pour ce faire, lors de la découpe en chunks, on stocke également la position du chunk dans le texte, de telle sorte que s’il est choisi lors de la phase de récupération, il est possible de le compléter avec du texte situé juste avant et juste après pour recréer un chunk plus long et donc contenant plus d’informations.
L’intérêt de cette méthode est d’avoir des petits chunks porteurs de sens sur lesquels faire la comparaison avec la requête mais de conserver néanmoins un grand nombre d’informations en donnant des chunks plus longs au LLM.
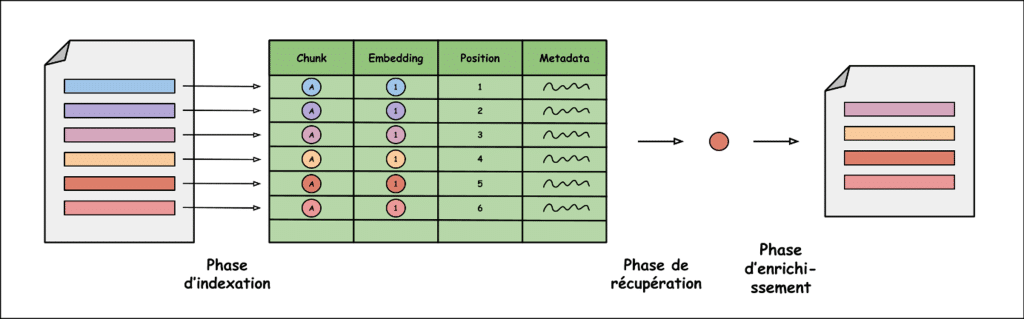
Une autre possibilité pour optimiser la phase d’indexation est d’ajouter dans la vector base des résumés des textes pour mieux gérer les requêtes plus globales qui nécessitent des informations peu précises mais sur de nombreux documents. Par exemple : « À l’aide de tes documents, parle-moi du développement durable ».
Associer à chaque chunk des metadata (document de provenance, thème abordé, auteur…) est une autre méthode utilisée pour optimiser l’indexage des chunks. Cela permettra de mettre en place des filtres lors de la phase de récupération.
Amélioration de la phase de récupération
Dans un RAG avancé, la phase de récupération est divisée en trois parties sobrement appelées pré-récupération, récupération et post-récupération.
Techniques de pré-récupération
Il existe quatre concepts principaux dans la partie « pré-récupération » qui consistent toutes à retravailler la requête envoyée par l’utilisateur :
1.
La « Transformation »
Le concept consiste à réécrire la requête – généralement grâce à un LLM – pour aligner sa sémantique avec celle de la réponse recherchée.
2.
« L’Expansion »
Le concept dans lequel un LLM est utilisé pour écrire des sous-requêtes.
3.
Le « Routing »
Le concept repose sur des systèmes de détection de mots clés pour filtrer les chunks selon leurs metadata.
4.
La « Construction »
Le concept qui est assez spécifique et dont le but est de réécrire la requête pour faire des recherches dans une base autre que la base vectorielle. Par exemple : « Transformer une requête écrite en langage naturelle, en une requête SQL ».
Optimisation des techniques de récupération
La phase de récupération est sensiblement la même que celle de la méthode naïve. Notons deux points. Le premier est le choix de représentation de nos chunks. En effet, il est possible d’utiliser l’embedding comme présenté plus haut où les vecteurs sont proches lorsque les chunks sont similaires en sens : on parle alors de vecteurs denses. Cependant, il est également possible d’utiliser des vecteurs dits « sparses » qui encodent les chunks comme des vecteurs de 0 et de 1, indiquant la présence de mots prédéfinis à l’avance.
Le deuxième point est la possibilité de « fine-tuner le retriever », c’est-à-dire la possibilité de réentraîner un modèle de récupération pour qu’au lieu de retourner toujours les chunks les plus proches, il puisse retourner les chunks les plus pertinents. « Fine-tuner » quelque chose en général est un process assez long et très dépendant des données utilisées.
Techniques de post-récupération
Une fois récupérés, les chunks sont soumis à deux processus différents : la sélection et le ranking. La sélection consiste à éliminer des chunks qui ont été récupérés mais qui n’apporteraient pas d’informations pertinentes pour répondre à la requête. Le ranking, quant à lui, permet de classer les chunks par ordre d’importance pour ajouter le plus d’informations pertinentes au LLM sans pour autant surcharger sa fenêtre de contexte.
Enrichissement et génération : étapes avancées
Pour un RAG avancé, la phase d’enrichissement n’est plus une simple concaténation des chunks récupérés. Tout d’abord, il existe une phase de fusion des différentes informations récupérées. Par exemple : si une expansion a été mise en place, il est nécessaire de fusionner les résultats des différentes sous-requêtes.
Vient ensuite une phase d’agencement qui a pour but de disposer toutes les informations issues de la fusion dans un prompt respectant les règles empiriques établies par les prompts ingénieurs les plus téméraires.
Finalement, la phase de génération reste la même que pour le naïf. Pourquoi ? Parce qu’un LLM réalise ce travail. À noter toutefois, qu’il est possible de fine-tuner un LLM pour le spécifier sur nos données et ainsi obtenir des réponses encore plus satisfaisantes, notamment à partir d’un dataset d’entraînement qui associe à un prompt donné la réponse attendue.
Les principaux problèmes liés au RAG avancé
La bonne utilisation des méthodes présentées dans les sections précédentes permet déjà de construire des systèmes RAG hautement robuste. Cependant, si la plupart des problèmes intrinsèques au RAG naïf ont été balayés par le RAG avancé, ce dernier est loin d’être un remède miracle et entraîne avec lui un nouveau florilège de problèmes.
Temps de latence
Les méthodes efficaces de réécriture de requêtes, d’extraction de mots clés ou de ranking des informations présentées plus haut, s’appuient généralement elles-aussi sur des LLM. Le problème d’un LLM repose sur sa lenteur. En effet, lorsque vous utilisez ChatGPT, la réponse apparaît petit à petit : token par token plus exactement. On dit alors que le modèle « streame ».
Mais finalement, entre l’apparition de la première lettre et de la dernière, un temps non-négligeable s’est écoulé. Le problème de nombreuses de ces méthodes de RAG avancé repose donc sur ce temps d’attente que l’utilisateur doit subir avant même de voir la première lettre apparaître à son écran. La raison est le simple fait qu’elles reposent sur des LLMs.
Nécessité d’entraînement
Comme présenté en introduction, le RAG est un outil puissant dans l’appropriation de chacun des modèles de langage. Il permet notamment d’utiliser des modèles pré-entraînés et donc de s’affranchir de la phase la plus coûteuse, en temps et en argent : celle d’entraînement.
Le problème des RAG avancés, c’est que leur performance est réellement sublimée lorsque le retriever et le générateur (LLM qui génère la réponse finale) sont fine-tunés, c’est-à-dire en quelque sorte réentraînés. On perd donc une grande partie de l’intérêt même du RAG.
Incapacité à synthétiser
Tout comme son petit frère naïf, le RAG avancé n’arrive pas vraiment à gérer les tâches de synthétisation. Ajouter les résumés de chaque texte dans une vector base peut améliorer les résultats.
Cependant, comment obtenir ces résumés de texte ? Deux solutions sont possibles à ce stade : les résumer à la main, ou espérer ne pas dépasser la fenêtre de contexte d’un LLM et lui donner tous les chunks pour qu’il résume le document.
Le RAG a-t-il atteint ses limites ?
Après avoir lu cet article, un sentiment d’insatisfaction doit normalement s’installer dans votre esprit. Malgré toutes les méthodes utilisées pour peaufiner notre RAG, ce dernier a encore son lot de problèmes et on ne voit pas bien comment étoffer d’avantage le RAG avancé.
A-t-on alors atteint l’irrémédiable limite du RAG avec ces RAG dit avancés ? Peut-être… Ce qui est sûr en revanche, c’est que ce n’est pas le parti pris par Microsoft.
L’ensemble des problèmes évoqués dans la section précédente, en particulier la dernière, a conduit les ingénieurs de Microsoft à imaginer une toute nouvelle approche du RAG appelée GraphRAG. À cette fin, ils se sont appuyés sur une technique d’indexation des données connues depuis longtemps : les graphes de connaissances.
Pour continuer votre plongée dans le vaste océan des RAG et découvrir l’ingéniosité de la méthode dite « GraphRAG », je vous invite à être patient car la suite arrive très prochainement.
Découvrez la suite de cette série !

Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.




Pas encore de commentaires