
Les fournisseurs de Cloud proposent une multitude d’interfaces afin de faciliter le paramétrage de leurs services. Clément vous propose de découvrir l’ordonnanceur de Google Cloud Platform afin de gérer vos tâches Spark.
Lorsque l’on utilise une plateforme Cloud, on s’attend à pouvoir effectuer tout un tas d’action “out of the box” pour nous simplifier la vie. C’est le cas par exemple du lancement des jobs, de leur ordonnancement, de la création de clusters ainsi que leur gestion, etc. Mais comme le suggère l’existence même de cet article, ça ne se fait pas forcément en un clic. Nous allons voir ici comment il est possible d’ordonnancer un job Spark sur Google Cloud Platform (GCP).
Commençons par la création d’un job. L’interface graphique de GCP nous permet de lancer des jobs Spark/Hadoop très facilement par le biais d’un formulaire à remplir, comme on peut le voir sur le screenshot ci-dessous.
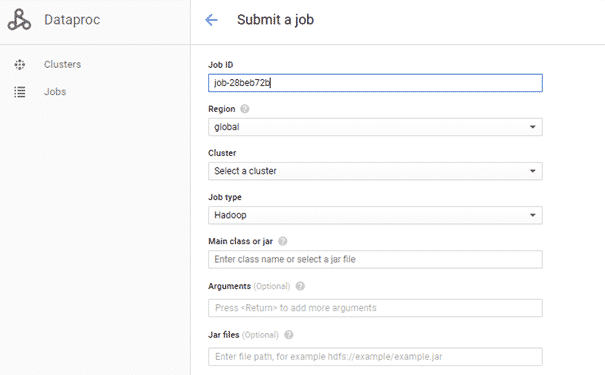
Comme vous pouvez le remarquer, il n’est nulle part question d’ordonnancement, la seule option étant le lancement en “one shot”. Un deuxième problème “caché” se pose : la gestion du cluster. Il serait appréciable que le cluster se lance automatiquement au début du job et “s’éteigne” tout seul dès lors que le job est terminé. Ces concepts n’existent malheureusement pas sur GCP : une fois créé, un cluster ne peut être que modifié ou supprimé. Cela nous oblige donc à avoir des clusters “up-and-running” non-stop, ce qui coûte de l’argent. Heureusement pour nous, il existe un moyen de contourner cela.
Le service cron d’App Engine
Quand on pense à de l’ordonnancement, cron revient souvent à l’esprit. C’est d’ailleurs un service proposé par Google à travers App Engine.
Remarque :
Dans cet article nous prenons le parti pris de déployer un web service permettant l’appel à un job Spark. Il est tout à fait possible de créer une machine sur compute engine (par exemple une f1-micro) et de scheduler le lancement d’un script avec le service cron unix.
Il y a beaucoup d’inconvénients avec cette technique, comme l’obligation de garder la machine constamment allumée, l’absence d’accès direct aux logs sur l’interface de GCP. Il n’y a également pas de moyen direct de lancer le job comme bon nous semble ou de gestion de la version du job à lancer, etc.
Pour toutes ces raisons, nous partons sur une technique certes plus complexe, mais source de nombreux avantages.
Pour rappel, App Engine vous permet de développer et déployer des services web très simplement.
L’idée est donc la suivante :
- Déployer un service web utilisant l’API de Google pour gérer votre cluster / lancer votre job
- Utiliser le service cron d’App Engine pour appeler votre service web quand vous le souhaitez (une fois par mois, tous les jours à 21h, etc.)
Nous utiliserons ici l’API Workflow templates (actuellement en beta) nous permettant de lancer un workflow qui créera un cluster, lancera notre job dessus et supprimera le cluster à la fin. Pas de surcoût grâce à cette solution, le cluster n’étant facturé que durant la durée du job.
La création de notre workflow
Pour notre exemple, nous allons prendre le wordcount PySpark.
Le workflow sera donc le suivant :
- Création du cluster
- Exécution du wordcount PySpark
- Suppression du cluster
Nous allons pour cela mettre deux fichiers sur le Google Cloud Storage :
- Un fichier texte quelconque
- Le code pyspark
Remarque :
Toutes les commandes suivantes seront à réaliser dans la console gcloud ou dans une console ayant accès aux commandes gcloud.
Nous pouvons désormais créer notre workflow-template comme suit :
gcloud beta dataproc workflow-templates create wordcount-workflow
Puis nous lui assignons un cluster créé au lancement du workflow.
gcloud beta dataproc workflow-templates set-managed-cluster wordcount-workflow
--master-machine-type n1-standard-4
--worker-machine-type n1-standard-4
--num-workers 2
--cluster-name wordcount-workflow-cluster
--zone europe-west2-b
Enfin, nous assignons le job à notre workflow.
gcloud beta dataproc workflow-templates add-job pyspark gs://mybucket/wordcount.py
--step-id wordcount
--workflow-template wordcount-workflow
-- gs://mybucket/file.txt
N’oubliez pas de changer les chemins selon votre bucket GCS. La dernière option est le path du fichier qui sera lu par le script WordCount.
Maintenant que notre worfklow est créé, nous pouvons le tester en lançant la commande
gcloud beta dataproc workflow-templates instantiate wordcount-workflow
Si l’on regarde maintenant dans les logs (Dataproc | Jobs), nous pouvons remarquer que le job a effectivement tourné sans soucis.
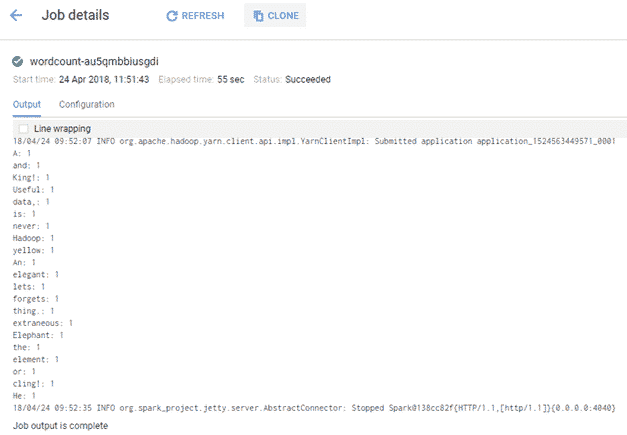
Ne reste plus qu’à ordonnancer le job sur App Engine.
Développement et déploiement du web service sur App Engine
Commençons déjà par développer notre service web permettant de faire l’appel au workflow dans un fichier main.py
import webapp2
import googleapiclient.discovery
class WordcountHandler(webapp2.RequestHandler):
def get(self):
dataproc = googleapiclient.discovery.build('dataproc', 'v1beta2')
operation = dataproc.projects().regions().workflowTemplates()
.instantiate(name="projects/[votre-id-projet]/regions/global/workflowTemplates/wordcount-workflow", body={})
.execute()
self.response.write('Job launched, OPERATION ID {}.'.format(operation["name"]))
app = webapp2.WSGIApplication([('/wordcount/run', WordcountHandler)], debug=True
Créons maintenant le fichier app.yaml permettant de déployer notre application sur App Engine
runtime: python27 api_version: 1 threadsafe: yes handlers: - url: /wordcount/.* script: main.app libraries: - name: webapp2 version: "2.5.2" - name: ssl version: latest
Vous remarquerez que notre main.py utilise le module googleapiclient. Ce module n’est pas fourni par App Engine, il va donc falloir exécuter les commandes suivantes :
mkdir lib sudo pip install -t lib/ --upgrade google-api-python-client
Elles créent un dossier lib et y installent les modules de l’API Python de Google.
Afin de les rendre accessible à notre programme il va falloir créer un fichier appengine_config.py contenant les lignes suivantes :
from google.appengine.ext import vendor
vendor.add('lib')
Nous avons donc désormais 3 fichiers et 1 dossier, respectivement :
- main.py décrivant le web service
- app.yaml contenant la configuration du service à déployer
- appengine_config.py permettant l’utilisation des librairies de l’API Python de Google
- lib/ le dossier contenant les librairies de l’API Python de Google
Nous pouvons désormais déployer le service en lançant la commande gcloud app deploy app.yaml.
On peut dès lors le retrouver en tant que service « default » sur l’interface graphique d’App Engine.

Si vous cliquez sur le nom du service, ici « default », et ajoutez /wordcount/run à l’URL, vous devriez avoir en retour l’opération ID du job lancé. Vous pouvez également retrouver votre job et le cluster créé pour son lancement dans “Dataproc | Jobs”.
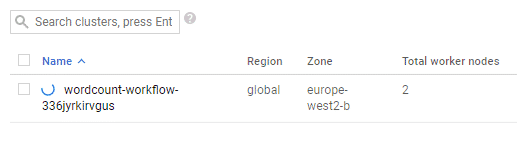
Une fois le job terminé, il ne devrait plus y avoir de clusters dans l’onglet « Clusters » de Dataproc.
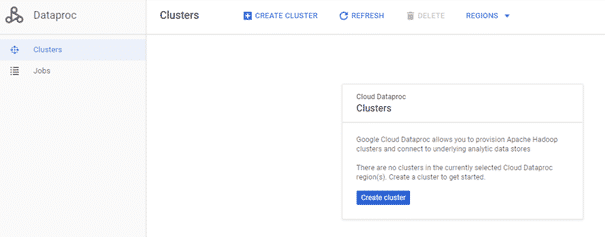
Ne reste maintenant qu’à ordonnancer notre job. Pour cela nous allons créer un fichier cron.yaml contenant les lignes suivantes.
cron: - description: wordcount job url: /wordcount/run schedule: every 10 minutes
Si vous exécutez la commande gcloud app deploy cron.yaml vous devriez retrouver le job cron sur App Engine, dans l’onglet « Task Queues | Cron Jobs »
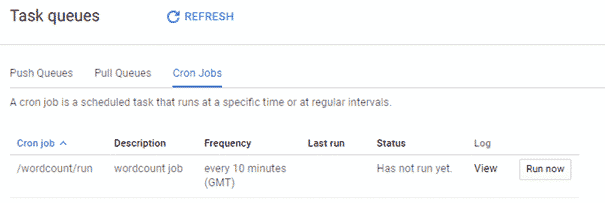
Après 10 minutes vous pourrez voir un cluster se créer, votre job se lancer et enfin le cluster être supprimé. Et voilà comment ordonnancer un job Spark sur GCP !



Pas encore de commentaires