Dans cet article nous verrons comment les Streams nous permettent d’effectuer des traitements sur des collections d’une manière simple et performante.
Dans cet article nous verrons comment les Streams nous permettent d’effectuer des traitements sur des collections d’une manière simple et performante.
Les Streams sont souvent utilisés avec les Lambda. Les « Lambda » feront l’objet d’un autre article, nous n’expliquerons ici que le minimum afin de voir le potentiel des Streams.
Qu’est-ce qu’un Stream ?
Avant tout, un Stream n’est pas une collection ou une structure de donnée de manière générale. C’est une séquence d’éléments sur laquelle on peut effectuer un groupe d’opérations de manière séquentielle ou parallèle.
D’ailleurs l’implémentation Java définit bien une interface spécifique :
public interface Stream<T>
Il existe deux types d’opérations sur les Streams :
- Les opérations intermédiaires : elles transforment un Stream en autre Stream
- Les opérations finales : elles produisent un résultat ou un « side-effect » (on verra plus bas)
Vous pouvez consulter la définition complète de l’interface dans sa documentation
Comment les utiliser ?
À la manière du SQL sur une table , les éléments d’un Stream vont passer à travers un pipeline de prédicats, de comparateurs, de fonctions…
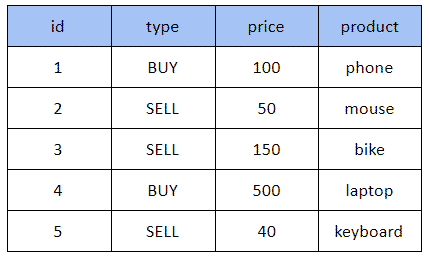
Prenons un exemple concret dans lequel nous allons manipuler des ordres d’achats et de ventes de produits. Un ordre sera soit d’achat ou de vente d’un produit quelconque (mobile, souris, vélo,…) avec un prix donné. Nous avons donc un objet Order qui définit quatre propriétés.
L’exercice consiste à récupérer dans la liste ci-dessous les produits vendus et les trier par prix croissant.
Orders
Implémentation de la classe Order
public class Order {
public enum OrderType {
BUY, SELL
};
int id;
OrderType type;
Double price;
String product;
public Order(int id, OrderType type, Double price, String product) {
this.id = id;
this.type = type;
this.price = price;
this.product = product;
}
public int getId() {
return id;
}
public OrderType getType() {
return type;
}
public Double getPrice() {
return price;
}
public String getProduct() {
return product;
}
}
Création de la liste dans notre main !
List<Order> orderList = new ArrayList<>();
orderList.add(new Order(1, OrderType.BUY, 100.0, "phone"));
orderList.add(new Order(2, OrderType.SELL, 50.0, "mouse"));
orderList.add(new Order(3, OrderType.SELL, 150.0, "bike"));
orderList.add(new Order(4, OrderType.BUY, 500.0, "laptop"));
orderList.add(new Order(5, OrderType.SELL, 40.0, "keyboard"));
List<Order> sellOrderList = new ArrayList<>();
for (Order order : orderList) {
if (order.getType() == Order.OrderType.SELL) {
sellOrderList.add(order);
}
}
Récupération de la liste triée sans l’utilisation des streams
Voici comment nous devons procéder pour récupérer la liste sans les streams :
Collections.sort(sellOrderList, (o1, o2) -> o1.getPrice().compareTo(o2.getPrice()));
List<String> products = new ArrayList<>();
for (Order o : sellOrderList) {
products.add(o.getProduct());
System.out.println(o.getProduct());
}
Récupération de la liste triée avec l’utilisation de Stream
Voyons maintenant la même récupération mais en utilisant les streams.
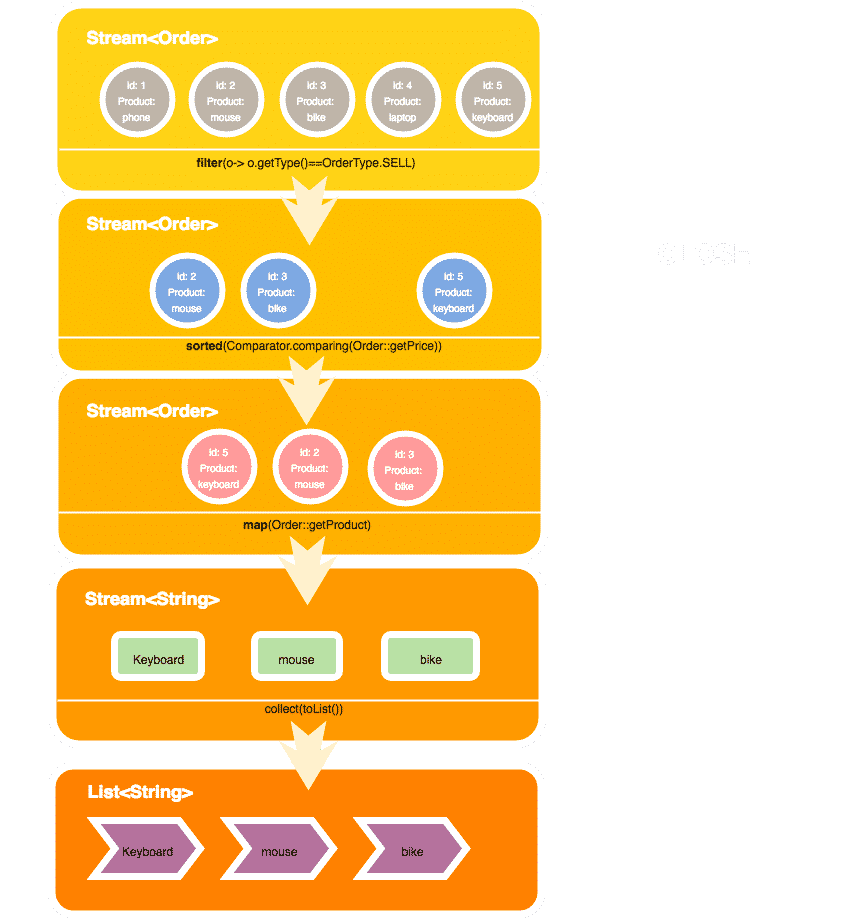
List<String> products2 = orderList.stream() .filter(o-> o.getType()==OrderType.SELL) .sorted(Comparator.comparing(Order::getPrice)) .map(Order::getProduct) .collect(toList());
Alors ?
Le code parle de lui-même, vous ne trouvez pas ? 🙂
- l’
ArrayListtemporaire disparaît - l’application d’opérations successives sur la liste est plus claire
- le code se réduit à une ligne
- on verra que le parallélisme se fait très facilement avec les Streams
Expliquons tout de même un peu ce code.
orderList.stream()renvoie un Stream d’objetsOrdersoit Streamfilter()permet de sélectionner dans le Stream tous les éléments respectant un prédicat, en retour on obtient toujours un Stream. C’est une fonction intermédiaire.
Notons l’utilisation de la lambda o-> o.getType()==OrderType.SELL. Appliquée à chaque élément du Stream, elle vérifiera le type de l’ordre. Ici par exemple nous souhaitons ne sélectionner que les ordres de vente.
On peut imaginer ici la définition d’une fonction anonyme: Order -> boolean. Elle prend un paramètre formel (ici o) et lui associe la valeur de retour de la comparaison o.getType()==OrderType.SELL soit un boolean.
.sorted()va trier les éléments du Stream en utilisant un comparator passé en argument, ici encore j’ai fait le choix d’utiliser une lambda:
(o1, o2) -> o1.getPrice().compareTo(o2.getPrice())
.map()est bien connue en programmation fonctionnelle (voir le dossier sur la programmation fonctionnelle pour un cours de rattrapage sur ce paradigme de développement), elle va appliquer une transformation à chaque élément, ici on va récupérer le produit sur lequel porte un ordre et ainsi récupérer en retour un Stream de produits, Stream.
Utilisation du parallélisme
La grande force des Streams est surement l’utilisation du parallélisme pour l’exécution des opérations.
Pour cela il suffit de récupérer un parallelStream au lieu d’un Stream. L’exemple ci-dessous devient simplement :
List products2 = orderList.parallelStream() .filter(o-> o.getType()==OrderType.SELL) .sorted(Comparator.comparing(Order::getPrice)) .map(Order::getProduct).collect(toList());
Les pièges à éviter
Attention toutefois à l’utilisation des parallelStream, il faut éviter certains pièges.
Tout d’abord l’exécution n’est pas déterministe au sens qu’aucune supposition ne doit être faite sur l’ordre de parcours du Stream.
Les parallelStream utilisent en interne le framework Fork/Join introduit en Java 1.7.
On remarque donc de suite que le ForkJoinPool.commonPool() (Thread pool commune à toute l’application) est utilisé par défaut. Attention car tous les coeurs sont donc utilisés ! Une application web pourrait donc rester “bloquée” faute de ressources disponibles pour traiter les requêtes.
L’article suivant donne plus de détails sur le sujet.
Une solution consiste alors à utiliser un custom Thread pool :
ForkJoinPool customThreadPool = new ForkJoinPool(4); long actualTotal = customThreadPool.submit( () -> aList.parallelStream().reduce(0L, Long::sum)).get();
Dans cet exemple, on appelle le constructeur en précisant le niveau de parallélisme. La valeur 4 est choisie ici de manière arbitraire. En pratique, elle dépend de l’environnement. Une bonne règle consiste à choisir cette valeur en fonction du nombre de core disponibles sur le CPU.
Les Side effects
Un Side effect est une action effectuée par une opération d’un Stream modifiant quelque chose d’externe. Par exemple, modifier une variable de l’application, envoyer un message JMS, envoyer un email, modifier l’interface graphique dans une application, etc.
Toutes les opérations ne sont pas autorisées à utiliser des side effects.
Par exemple :
ForEach(),ForEachOrdered()etpeek()renvoientvoidet sont donc destinées à produire un side effect.- Les opérations intermédiaires avec des paramètres comportementaux de type
map,filter, etc.. qui ne retournent pas de valeurvoidne devraient pas utiliser des side effects.
Il s’agit en tout cas de suivre les règles suivantes de la doc Java :
“Side-effects in behavioral parameters to stream operations are, in general, discouraged, as they can often lead to unwitting violations of the statelessness requirement, as well as other thread-safety hazards.”
“If the behavioral parameters do have side-effects, unless explicitly stated, there are no guarantees as to the visibility of those side-effects to other threads, nor are there any guarantees that different operations on the « same » element within the same stream pipeline are executed in the same thread”
Dans un parallelStream, les opérations peek() et forEach() ne respectent pas l’ordre et ne sont pas déterministes. On pourra utiliser les side effects si l’ordre n’est pas important. Le cas échéant, il faudra utiliser forEachOrdered().
Conclusion
L’API Stream est bien utile : elle permet de travailler de manière concise sur les collections avec une syntaxe de haut niveau (similaire aux requêtes d’un SGBD) et laisse le choix de la meilleure implémentation bas niveau à la charge de la librairie Stream. L’utilisation des Streams prend toute son ampleur dans l’utilisation du parallélisme car elle nous permet de nous abstraire des Thread executor et de la gestion des Fork/Join, évitant ainsi les difficultés de synchronisation. L’utilisation des Lambdas augmente d’autant plus la concision du code. Il faut tout de même suivre les bonnes pratiques concernant les side effects et les exceptions avec les Streams si on ne veut pas tomber dans certains pièges. Nous aborderons le sujet des exceptions dans un prochain article.



Pas encore de commentaires