
Face à des exigences croissantes en matière d’agilité, de scalabilité et d’efficacité, les architectures logicielles ont connu une évolution majeure, passant du monolithique aux microservices, puis au serverless. Mais que signifie réellement le terme « serverless » ? Cette approche permet-elle vraiment de se passer des serveurs, ou s’agit-il simplement d’une nouvelle manière de les gérer ? Dans cet article, nous explorerons l’architecture serverless, ses avantages, ses limites et son implémentation concrète sur AWS.

Imaginez que vous construisez une maison. Si vous ne commencez pas par une base solide et un plan bien conçu, votre maison risque de s’effondrer ou de nécessiter des rénovations coûteuses à l’avenir. Cet exemple reste significatif si on fait l’analogie avec la production logicielle : si vous ne choisissez pas judicieusement l’architecture logicielle de votre application, elle vous confrontera au cours du temps à des problèmes majeurs, tels que la dégradation de performance, les bogues persistants, les coûts de maintenance élevés et les défis d’évolutivité qu’il faut sans cesse relever pour survivre sur le marché concurrentiel. L’architecture d’un logiciel est donc la pierre angulaire sur laquelle repose sa stabilité, sa sécurité, sa flexibilité et sa capacité à évoluer avec le temps.
Sur la base de ce concept, les architectes logiciels essaient toujours d’adopter les bonnes pratiques au niveau des architectures logicielles, ce qui nous a permis de passer de l’architecture monolithique vers l’architecture microservices avant d’assister à l’apparition de l’architecture microservices sans serveur avec l’arrivée du cloud computing.
Vous souhaitez migrer votre infrastructure web ou vos applications dans le cloud ?
👉 Découvrez notre article « Migration vers le cloud : comment réussir sa transition ? »

Comment se traduit alors cette évolution architecturale ? Qu’est ce qui nous pousse vraiment vers l’architecture serverless? Et est-elle véritablement sans serveur comme son nom l’indique ? Les réponses dans cet article.
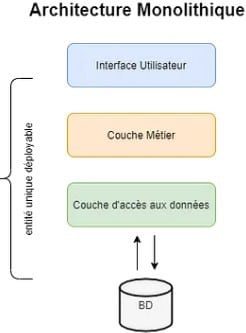
C’est quoi l’architecture monolithique ?
Les applications monolithes, dites aussi applications d’un seul bloc, sont simples à construire. Mais cette simplicité projette une complexité au fur et à mesure que l’application évolue en taille. Les mises à jour au sein de cette architecture sont si complexes qu’on a cherché d’autres architectures plus agiles et simples à maintenir telle que l’architecture microservices.
C’est quoi l’architecture microservices ?
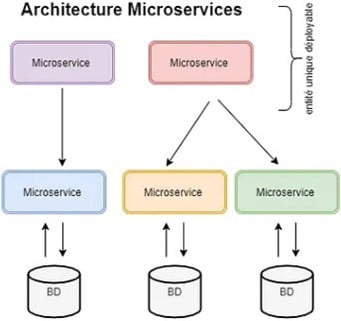
Contrairement aux applications monolithiques, les applications en microservices sont beaucoup plus souples et plus agiles. Une application en microservices est une application divisée en plusieurs petits services indépendants – chacun ayant sa propre fonction – communiquant entre eux via des API, ce qui permet une grande flexibilité et une facilité de maintenance.
Une application microservices est donc une application facile à maintenir, simple à déployer et tolérante aux pannes.
C’est quoi l’architecture serverless ?
Pour aller plus loin que l’architecture microservices, notamment avec l’arrivée du cloud computing et ses concepts d’agilité, une autre architecture a été fondée. Son objectif principal est de réduire le TTM (time to market) et de produire des applications dans un moindre temps. Le nom serverless n’indique pas vraiment qu’il n’y a pas de serveur mais plutôt la dispense de la gestion de l’infrastructure logicielle.
Autrement dit, cette architecture permet de créer, exécuter et déployer des applications sans tenir compte de l’infrastructure qui sera managée par l’un des fournisseurs de services cloud (Amazon, Microsoft, Google, etc.). Il incombe alors à ces fournisseurs de gérer, mettre à l’échelle et entretenir les serveurs de l’application.
Par conséquent, le serverless permet aux développeurs de se concentrer sur la création de code métier sans se soucier de la gestion des serveurs sous-jacents. Cette architecture offre une scalabilité automatique, une facturation granulaire basée sur la consommation réelle et une haute disponibilité. Elle offre également la possibilité de créer rapidement des prototypes et de déployer des applications avec une agilité exceptionnelle.
L’architecture serverless sur AWS
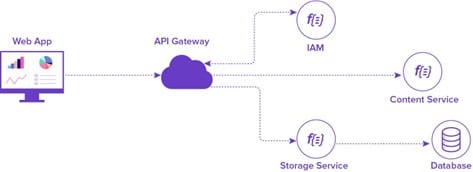
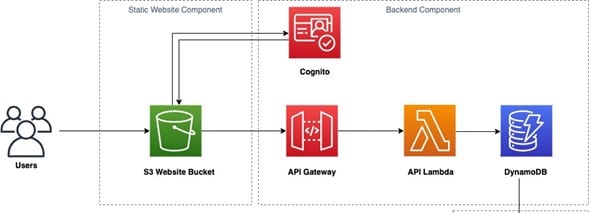
L’architecture serverless sur AWS, combinant AWS Lambda, Amazon API Gateway et Amazon DynamoDB, offre une approche évolutive et sans gestion pour le développement d’applications cloud.
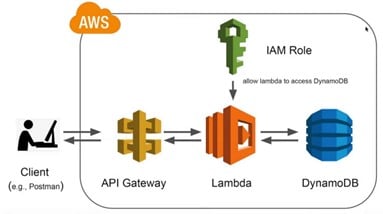
Dans cette architecture, Lambda représente le cœur de la logique métier, permettant d’exécuter du code sans serveur en réponse à des événements, telles que des requêtes HTTP via API Gateway.
API Gateway agit comme la porte d’entrée de l’application, permettant de définir des points de terminaison RESTful, d’authentifier les utilisateurs et de gérer les autorisations. Les demandes HTTP entrantes sont redirigées vers les fonctions Lambda appropriées, créant ainsi une interface facilement accessible pour les clients de l’application.
Et comme toute application doit interagir avec une base de données, AWS nous donne la possibilité d’enrichir notre modèle serverless avec une base de données sans serveur, elle aussi via le service DynamoDB. Ce service offre des bases de données NoSQL entièrement gérées par AWS et qui s’intègrent parfaitement avec cette architecture.
Vu qu’il est serverless, le service DynamoDB offre une évolutivité automatique, une disponibilité élevée et une latence faible pour stocker et interroger les données de l’application. Les fonctions Lambda peuvent ainsi accéder aux données stockées de manière efficace.
Vous souhaitez découvrir un autre service AWS pour L’ETL Serverless ?
👉 Découvrez notre article « AWS Glue : Introduction à l’ETL Serverless ».

Créez votre première CRUD application sans serveur sur AWS
Dans ce tutoriel, nous allons utiliser le service IaC (Infrastructure as Code) CloudFormation d’AWS pour créer nos différentes ressources cloud nécessaires et construire une application simple. À cette foin, nous avons pris comme exemple une application de gestion d’une bibliothèque de livres.
L’architecture de cette application va être basée principalement sur les services DynamoDB, API Gateway et des fonctions Lambda écrites en Python.
Commençons par créer la table de notre base de données DynamoDB.
Ici, on a créé une table DynamoDB nommée « MyBookTable » avec une clé de partition « bookId » ainsi que deux autres attributs de type chaîne de caractère, représentant respectivement le titre et l’auteur du livre. La capacité provisionnée pour cette table est de 5 unités de lecture et d’écriture. Nous pouvons à tout moment personnaliser les propriétés de la table DynamoDB en fonction de nos besoins.
L’étape suivante consiste à créer un rôle IAM permettant aux fonctions Lambda d’interagir en lecture et en écriture avec la table de base de données.
Comme vous voyez, ce rôle nommé LambdaExecutionRole va permettre à notre fonction Lambda de lire, lister, mettre à jour et supprimer des éléments de la table déjà créée.
Il suffit de référencer ce rôle dans la configuration de notre fonction Lambda.
La fonction Lambda se base principalement sur le Handler qui est une méthode définissant le comportement de Lambda selon l’événement en entrée.
Dans notre cas, le comportement de Lambda diffère selon le type de requête http reçue (GET, PUT, POST, DELETE), et c’est le Handler qui fait la redirection de la requête vers la méthode adéquate.
Il reste à définir maintenant les fonctions get_book(), create_book(), update_book() et delete_book().
Le seul point d’entrée de notre application c’est l’API Gateway. C’est elle qui va appeler la fonction Lambda à la suite d’une requête de l’utilisateur.
Après avoir créé l’API, on doit y rattacher des ressources et des méthodes. Une ressource représente le path sur lequel une méthode (get, delete, post, update…) va interagir.
Dans notre cas, nous avons deux ressources à créer : /books et /books/{id}
Pour le path /books, on peut appliquer les méthodes GET et POST :
Pour le path /books/{id}, on peut appliquer les méthodes GET, PUT et DELETE :
L’accès de l’API Gateway à notre fonction Lambda doit être garanti via une ressource qui s’appelle Lambda Permission et dont la configuration est la suivante :
Nous avons terminé la configuration de notre stack CloudFormation. Désormais, il est possible de la déployer via la commande AWS CLI suivante :
Allons plus loin avec le serverless
Précédemment, nous avons créé la partie backend (API) d’une application CRUD. AWS offre de plus la possibilité d’intégrer d’autres services toujours en gardant la même architecture serverless.
Le frontend de l’application peut être hébergé sous forme de site web statique dans un bucket S3. À partir de cette partie front s’exécutent les appels API de notre Gateway.
On peut aussi sécuriser l’accès à notre application via le service Cognito, qui est un service d’authentification managé par AWS.
De cette manière, on obtient l’architecture suivante :
Vous souhaitez migrer dans la cloud mais vous ne savez pas comment vous y prendre ?
👉 Découvrez notre checklist pour réussir votre migration cloud en toute simplicité !

Conclusion
L’architecture serverless avec AWS Lambda a radicalement transformé la manière dont nous concevons et déployons des applications. Elle permet aux développeurs de se concentrer sur la logique métier plutôt que sur la gestion des serveurs, ce qui accélère le développement, réduit les coûts opérationnels et améliore la scalabilité. Les fonctions Lambda sont déclenchées en réponse à des événements, ce qui les rend idéales pour une variété de cas d’utilisation, des microservices aux applications web et mobiles.
Le serverless sur AWS ne se traduit pas uniquement à travers Lambda, mais ce fournisseur cloud nous donne la possibilité d’exécuter nos conteneurs docker en mode serverless. À vous de fournir l’image docker. Et à AWS de l’exécuter à travers le service ECS Fargate qui vous permet de gérer vos conteneurs sans vous soucier de l’infrastructure sous-jacente. À la clé : une flexibilité supplémentaire pour les applications qui nécessitent une plus grande personnalisation et un contrôle direct sur l’environnement d’exécution.
En conclusion, l’architecture serverless avec AWS Lambda est une approche puissante pour le développement d’applications modernes, offrant plus de simplicité, d’évolutivité et d’efficacité. Cependant, il est essentiel de choisir l’approche qui convient le mieux à vos besoins, que ce soit avec Lambda pour les charges de travail sans serveur ou AWS Fargate pour les conteneurs. Avec la gamme de services proposés par AWS, vous avez la flexibilité nécessaire pour créer des applications adaptées à vos besoins spécifiques.
Vous avez aimé cet article ?
Abonnez-vous à notre newsletter pour ne rien rater de l’actualité Tech et Finance.


Pas encore de commentaires