
La volatilité est une mesure de la dispersion d’un prix qui se révèle très utile pour le pricing et l’évaluation du risque. Pour la calculer, il existe différents modèles : l’”historique”, simple mais sensible aux mouvements inhabituels, l”’implicite”, populaire, mais reposant sur des hypothèses discutables, et enfin le “SABR”, fiable mais coûteux et difficile à paramétrer. Petit tour d’horizon des avantages et des inconvénients des uns et des autres.
Avant d’entrer dans le vif du sujet, mettons nous d’accord. Vous trouverez diverses définitions de la volatilité. Voici la mienne : la volatilité est une mesure de la dispersion dans le temps du prix d’un actif. Le mot important ici est “dispersion” évidemment. En d’autres termes la volatilité est une mesure de la variation du prix d’un actif.
Son utilité est assez évidente dans l’évaluation de risques. En effet plus la volatilité d’un actif est importante, plus le prix de l’actif est susceptible de varier dans un laps de temps court. Mais attention cette variation peut être aussi bien à la hausse qu’à la baisse. Et donc plus la volatilité est forte, plus le risque de perte ou de gain est important. Les deux sont indissociables.
La volatilité est aussi très importante dans les activités de pricing. Là aussi, le lien est assez évident. Si vous avez à évaluer le prix d’un produit dérivé à terme (option, future, produit structuré…), le prix dépendra notamment d’une combinaison entre la durée de vie du produit et la volatilité de ses sous-jacents. Et donc, plus la volatilité est grande plus le prix du produit dérivé sera incertain.
La volatilité est usuellement notée σ dans la littérature financière. Cette notation, celle de l’écart type en mathématiques, n’est pas un hasard, comme nous allons le voir.
L’approche historique
Un moyen simple d’évaluer une variation par rapport à une référence en statistique est l’écart type. L’écart type étant l’écart moyen des données par rapport à la moyenne de ces données. En formule c’est donc :
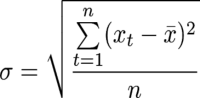
Où ![]() est la moyenne et
est la moyenne et ![]() les prix aux différents temps (jours par exemple). Dans la littérature financière vous verrez aussi que x est le rendement, voir le rendement logarithmique. Voici le prix de clôture du CAC 40 sur dix jours. Ici la volatilité journalière est de 36.248512.
les prix aux différents temps (jours par exemple). Dans la littérature financière vous verrez aussi que x est le rendement, voir le rendement logarithmique. Voici le prix de clôture du CAC 40 sur dix jours. Ici la volatilité journalière est de 36.248512. 

L’avantage de ce modèle c’est qu’il est basé sur des valeurs connues. Il est donc facile à calculer. En revanche, l’approche de la moyenne et de l’écart type reste limité, car il amalgame toutes les valeurs sans aucune distinction. Par exemple si une annonce provoque un pic du prix, cette valeur inhabituelle va fortement modifier la moyenne et l’écart type. En fait, le pic va se répartir sur l’ensemble des valeurs. Son apport sera d’autant plus sensible, à cause des carrés dans la formule.
En plus du problème de poids trop important accordé aux valeurs extrêmes, la méthode a pour but de calculer une volatilité future à partir de données du passé. Or les crises financières ont depuis longtemps prouvé que cela ne fonctionnait pas comme ça. Prédire l’avenir avec les valeurs du passé est régulièrement utilisé, car cela est simple. Mais cela reste limité. Dans l’idéal, il faudrait une approche prenant en compte le caractère pseudo-aléatoire des prix, à savoir une approche stochastique.
La volatilité implicite du modèle de Black-Scholes
Tout d’abord, il faut peut-être rappeler ce qu’est le modèle de Black-Scholes. C’est un modèle de dynamiques stochastiques qui relie le prix d’un actif au prix d’un dérivé vanille à terme. Par exemple une option européenne de call. L’actif étant appelé sous-jacent. Son succès est dû au fait que sa solution est une formule fermée. C’est-à-dire qu’elle ne nécessite pas d’itération pour être calculée, contrairement au modèle Cox Ross Rubinstein, par exemple. Le modèle Black-Scholes nécessite plusieurs paramètres pour calculer le prix du dérivé :
- La valeur du sous-jacent au moment du calcul.
- Le temps qu’il reste jusqu’à la maturité du dérivé.
- Le prix d’exercice de l’option à maturité (strike).
- Un taux d’intérêt dit sans risque.
- La volatilité du sous-jacent.
Si le sous-jacent est coté sur le marché et l’option aussi, on connaît leurs prix. Donc en connaissant les autres paramètres du modèle, on peut en déduire la volatilité. Cette volatilité déduite est dite implicite. Implicite, car elle n’est pas mesurée avec des données historiques, mais déduite par le “calcul” inverse d’un modèle. J’ai mis le calcul entre guillemet, car si la solution du modèle de Black-Scholes permet de passer du prix d’un sous-jacent au prix de l’option par un simple calcul; pour trouver la volatilité en partant des deux prix, il faut résoudre une équation différentielle. Donc il faut employer des méthodes de calcul itératives. En langage profane, on prend le prix du sous-jacent, on prend une volatilité et on calcule le prix du dérivé. S’il correspond au prix cherché, c’est gagné. Sinon on essaye encore, jusqu’à trouver la bonne volatilité. Évidemment on n’essaye pas des valeurs de volatilité au hasard, c’est là où les méthodes de résolution d’équations différentielles interviennent. Ce qu’il faut retenir c’est que cela se fait de manière itérative et donc coûte plus cher en calcul qu’une formule fermée comme celle de la solution du modèle pour passer du prix du sous-jacent au prix de l’option.
Comme beaucoup de produits dérivés cotés sur les marchés sont pricé avec le modèle Black-Scholes, la volatilité implicite est souvent utilisée. En fait, la volatilité implicite, représente la volatilité du sous-jacent anticipée par le marché. Ce modèle a tout de même des limites. En effet, si le modèle de Black-Scholes prend en compte l’aspect stochastique du prix du sous-jacent, il suppose que la volatilité est constante par rapport aux autres paramètres du modèle. Si c’était vrai, on peut prendre deux dérivés identiques dont seuls les strikes et les prix sont différents, et en faisant le calcul de la volatilité implicite on devrait trouver le même résultat. Or on observe que c’est faux. Selon la classe d’actif du sous-jacent, si on trace dans un graphique la volatilité par rapport au strike on aura un graphique en forme de smile ou en skew :
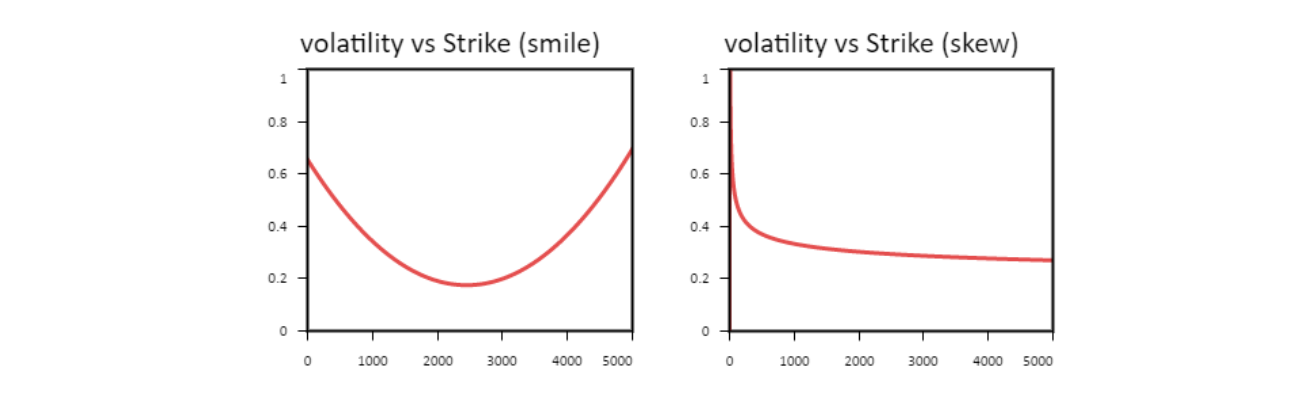
De la même façon le modèle suppose que la volatilité est aussi constante quelle que soit la maturité. On observe aussi que cette supposition est fausse. Les variations par rapport au strike combinées à celles en fonction de la maturité amènent à des graphiques en trois dimensions : volatilité, strike et maturité, où la volatilité n’est plus une courbe mais une surface. Souvent on appelle ces surfaces des nappes de volatilité. De ces nappes on peut interpoler le point qui correspond à la maturité et au strike de l’option, ce modèle s’appelle « modèle de volatilité locale ». Voici un graphique d’exemple d’une nappe de volatilité sur ALPHABET-A (Google) :
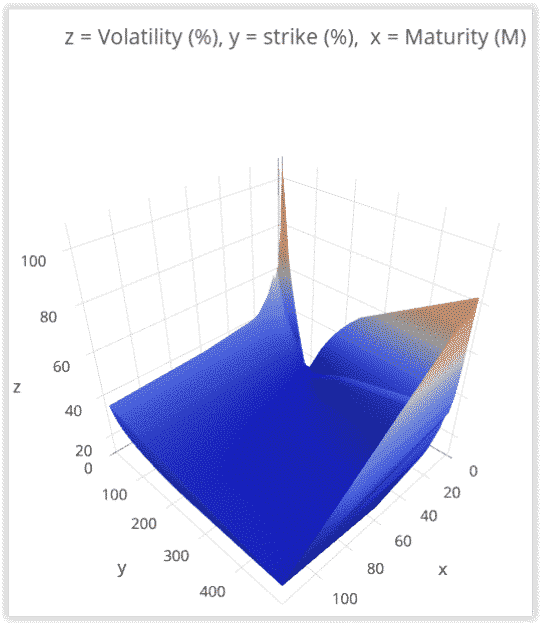
Une approche Stochastique : le modèle SABR
Le modèle SABR est un modèle stochastique de volatilité. Contrairement au modèle de Black-Scholes qui supposait des prix de sous-jacents stochastiques avec une volatilité constante, ce modèle suppose que les prix et la volatilité des sous-jacents suivent tous les deux une dynamique stochastique. Il prend donc en compte l’aspect aléatoire de la volatilité. C’est une chose importante, voir essentielle. En reprenant la définition de la volatilité, on parle de dispersion de prix. Or quiconque a déjà vue un graphique représentant le prix d’un actif, comprend rapidement son caractère aléatoire. Et logiquement si le prix a un caractère aléatoire, la volatilité aussi.
L’acronyme SABR veut dire : Stochastique Alpha Beta Rho. Alpha, Beta, Rho étant les paramètres du modèle. Il a été mis au point par Patrick Hagan, Deep Kumar, Andrew Lesniewski, et Diana Woodward. Il se base sur le prix d’un Forward sur taux d’intérêt (dérivé vanille sans barrière, ni option). Le système d’équations différentielles stochastiques décrivant la dynamique du modèle est le suivant :
![]()
![]()
Avec Zt et Wt deux processus de Wiener (la partie aléatoire du modèle). Ces deux processus étant corrélés avec un coefficient ⍴. En formule :
![]()
Le modèle fonctionnant sous les conditions suivantes :
- 0 ≤ β ≤ 1
- ⍺ ≥ 0
- -1 < ⍴ < 1
Même en considérant qu’à t=0 on connait le couple F0 et 0 (condition initiale) ce système n’a pas de solution sous forme d’une formule fermée. Par contre, il a une solution asymptotique. En langage profane, une solution peut être calculée par itération, mais le calcul convergera rapidement. C’est certes plus coûteux que le calcul d’une formule simple, mais cela reste plus efficace que la résolution de beaucoup d’autres modèles n’ayant pas de solution asymptotique. C’est le premier avantage de ce modèle.
Son autre avantage est de prendre en compte la fameuse courbe en smile grâce au paramètre β. Sachant que les courbes en smile sont réellement observées, c’est la très grande force de ce modèle. Une autre chose à savoir sur ce modèle est que est appelé la volatilité lognormale de la volatilité, ou plus prosaïquement la “vol de vol”. Si α=0 alors le modèle SABR revient au modèle CEV, un autre modèle de volatilité stochastique.
Attention ce modèle, n’est pas non plus la panacée universelle. Il est difficile à paramétrer. α, β, ρ ne sont que trois, mais c’est déjà beaucoup, même si les domaines de valeurs de β et ρ sont limités. La calibration peut se faire soit avec des données historiques (ce qui nous ramène aux limites de la volatilité historique), soit en utilisant des paramètres de marchés en temps réel (ce qui nous ramène aux limites de la volatilité implicite). Autrement, il existe bien sûr d’autres modèles, notamment si vous vous intéressez à une classe d’asset en particulier. Par exemple sur les dérivés de taux, vous pouvez faire des recherches sur le modèles Ho-Lee ou Hull-White.


Vos commentaires
très interessant. bien dommage qu’il n y ai pas un bout de code pour illustrer tout ça.
Bien que développeur, l’ange de l’article se voulait fonctionnel. D’ailleurs la relecture a été faite par des personnes du métier pas des développeurs. De plus traduire des équation en code à assez peu d’intérêt en terme d’architecture et de connaissance du langage. Pour les modèles stochastique il y aurait peut-être eu un peu de Threading (Task) mais rien de transcendant.
Bonjour,
Je vous remercie pour votre article. Je trouve que vous Avez expliquer la problématique en peu de lignes. Je dis ça parcequ’en réalité il faudra un livre entier pour bien détailler le sujet.
Cdt,