
Les nombres de Church
Dans l’article précédent, nous avons présenté les axiomes de Peano qui permettent de construire les nombres naturels. Désormais, « traduisons »-les en langage de λ-calcul. Pour rappel, nous partons d’une idée qu’un nombre naturel est soit zéro (qui, strictement dit, n’est pas un nombre naturel mais reste nécessaire pour compter), soit un nombre naturel plus un.
Définition.

Si on souhaite interpréter, on peut penser un nombre de Church comme une fonction de deux arguments dont le premier est une fonction et le deuxième représente une valeur initiale. Le nombre n applique la fonction n fois à la valeur initiale et retourne le résultat.
Ici, le résultat « d’application » d’un nombre de Church mathbf{bar{3}} à (+1) et 0 constitue sa « valeur numérique ». Par exemple : mathbf{bar{3}} ; (+1) ; 0 sim 3.
Remarque. On préfère utiliser le symbole d’équivalence sim au lieu du signe « égalité » pour souligner que l’on parle d’une interprétation qui ne fait pas partie du λ-calcul.
Successeur
Définissons un terme mathbf{succ} qui « calcule » le successeur d’un nombre de Church arbitraire. Combien d’arguments devraient avoir ce terme (par argument, on entend des variables liées par abstraction : une fois que le terme est appliqué à un autre terme, les variables liées du premier sont alors remplacées par le « contenu » du deuxième) ? Son premier argument doit être un nombre à augmenter. Mais un nombre en λ-calcul est aussi une fonction de deux arguments. Donc mathbf{succ} doit prendre trois arguments – un « nombre » n à augmenter, une fonction à appliquer n + 1 fois et sa valeur initiale z :
Exercice. Montrer que mathbf{succ} ; mathbf{overline{n}} = mathbf{overline{n+1}}.
Solution. Utilisons la définition de mathbf{succ} et appliquons la beta-réduction de lambda n :
Puis, par la définition de nème nombre de Church on a :
Remarquons que pour éviter l’ambiguïté, nous avons remplacé s et z par s' et z' dans la définition de mathbf{overline{n}} car ces variables sont liées par abstraction — alpha-équivalence nous autorise à le faire. Puis, si on applique la beta-réduction aux lambda s' et lambda z', on obtient :
Q.E.D.
Addition, multiplication et puissance
L’addition d’un nombre de Church à un autre ressemble à l’addition d’un qui est fait par le terme mathbf{succ}. La seule “petite” différence est qu’il faut appliquer « (+1) » m fois, si le deuxième argument est mème nombre de Church :
La multiplication de deux nombres mathbf{bar{n}} et mathbf{bar{m}} ressemble à l’addition. La seule différence est qu’au lieu d’ajouter m fois 1, il faut additionner m fois le premier nombre :
Exercice. Essayez de deviner que fait la fonction suivante :
Que s'est-il passé ? Nous avons proposé trois termes "magiques". Pour prouver qu'ils correspondent bien à la somme, produit et puissance, il faut prouver que pour tout nombre de Church [latex]mathbf{bar{n}}[/latex], [latex]mathbf{bar{n}}[/latex] :
- [latex]mathbf{plus ; bar{n} ; bar{m} = overline{n + m}}[/latex],
- [latex]mathbf{mult ; bar{n} ; bar{m} = overline{n cdot m}}[/latex],
- [latex]mathbf{power ; bar{n} ; bar{m} = overline{n^m}}[/latex],
où [latex]mathbf{overline{n + m}}[/latex], [latex]mathbf{overline{n cdot m}}[/latex] et [latex]mathbf{overline{n^m}}[/latex] sont les nombres de Church qui correspondent respectivement à la somme, produit et puissance de [latex]n[/latex] et [latex]m[/latex]. Nous avons déjà fait une preuve similaire pour le terme [latex]mathbf{succ}[/latex]. Au lieu de produire des longues chaînes de calculs formels, nous montrerons une méthode moins stricte mais plus simple pour illustrer ces résultats.
Nous avons déjà vu que [latex]mathbf{bar{n}}[/latex], nème nombre de Church, est une fonction qui applique [latex]n[/latex] fois son premier argument à la deuxième. Calculons [latex]mathbf{plus ; bar{3} ; bar{2}}[/latex] dans ce contexte :
[latex]mathbf{plus ; bar{3} ; bar{2}} = lambda n. lambda m. lambda s. lambda z. ; n ; (m ; s ; z) ; mathbf{bar{3} ; bar{2}} = lambda s. lambda z.mathbf{bar{3}} ; s ; (mathbf{bar{2}} ; s ; z)[/latex]
Nous avons obtenu un terme qui ressemble à un nombre de Church par sa structure ([latex]s[/latex] et [latex]z[/latex] en abstraction). Pour voir qu'il est équivalent au [latex]mathbf{bar{5}}[/latex], il est suffisant de lui appliquer aux deux (+1) et 0, de même façon que nous avons fait dans la définition d'un nombre de Church.
[latex]mathbf{plus ; bar{3} ; bar{2}} ; (+1) ; 0 = lambda s. lambda z.mathbf{bar{3}} ; s ; (mathbf{bar{2}} ; s ; z) ; (+1) ; 0 = mathbf{bar{3}} ; (+1) ; (mathbf{bar{2}} ; (+1) ; 0)[/latex]
L'expression dans les parenthèses est équivalente à 2 car [latex]mathbf{bar{2}}[/latex] applique deux fois (+1) au 0. Analogiquement, [latex]mathbf{bar{3}} (+1) 2 sim 5[/latex].
Finalement, faisons le calcul similaire pour [latex]mathbf{mult ; bar{2} ; bar{3}}[/latex] :
[latex](mathbf{mult ; bar{2} ; bar{3}}) ; (+1) ; 0 = (lambda s. lambda z.mathbf{bar{2}} ; (mathbf{bar{3}} ; s) ; z) ; (+1) ; 0 = mathbf{bar{2}} ; (mathbf{bar{3}} ; (+1)) ; 0[/latex]
L'expression [latex](mathbf{bar{3}} ; (+1))[/latex] est intéressante car elle nous permet de discuter une application partielle -- une conception très importante dans la programmation fonctionnelle :
- [latex]mathbf{bar{3}}[/latex] est une fonction de deux arguments qui applique 3 fois son premier argument [latex]s[/latex] à son deuxième argument [latex]z[/latex].
- [latex](mathbf{bar{3}} ; (+1))[/latex] peut être considérée comme une fonction d'un argument [latex]z[/latex] qui applique 3 fois (+1) à [latex]z[/latex]. Évidemment c'est une fonction (+3).
En mettant tout ensemble, nous obtenons :
[latex](mathbf{mult ; bar{2} ; bar{3}}) ; (+1) ; 0 = mathbf{bar{2}} (+3) 0 sim (+3) ; ((+3) ; 0) sim 6.[/latex]
Le terme [latex]mathbf{power}[/latex] reste un exercice (n'oubliez pas que l'application est gauche-associative...) !
Paire
Les termes ci-dessous « implémentent » une structure de paire :

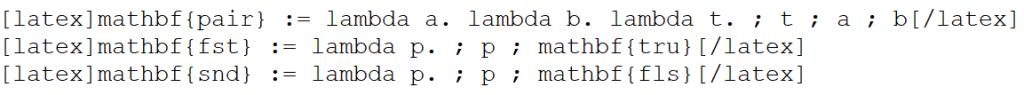
Soustraction
D’abord, rappelons qu’en lambda-calcul, il n’y a pas de nombre négatif. Donc « mathbf{bar{n}} - mathbf{bar{m}} » est défini si et seulement si n ge m. Si tel est le cas, alors il est tenant de faire de la même façon que l’addition — soustraire m de n est équivalent à soustraire m fois 1 de n :
Le vrai problème est une fonction mathbf{pred} — il est compliqué d’aller de reculer sur l’axe de nombres si l’ensemble des fonctions introduites ne permettent que d’avancer ! Comment alors calculer n-1 ? Il faut de nouveau partir de zéro, mais au lieu de faire n pas, il faut en faire n-1. Mais comment peut-on s’arrêter sur n-1 ? C’est là qu’une paire est nécessaire. En ayant une paire <i, j>, on va construire une paire <i+1, i>.
Donc, après n étapes en partant de <0, 0>, on aura <n, n-1>.
Cette formule vous semble complexe à comprendre ? Pas d’inquiétude, c’est normal ! La soustraction a été inventée par Kleene pendant l’extraction de sa dent de sagesse. Aujourd’hui, l’anesthésie n’est plus pareil…
Le λ-calcul est-il un langage de programmation ?
Comment peut-on montrer que les langages de programmation X et Y sont équivalents ? Il faut montrer deux propositions :
- Un programme quelconque écrit en X et qui peut être réécrit en Y
- Un programme quelconque écrit en Y et qui peut être réécrit en X
Hélas, prouver ces deux réductions entre le λ-calcul et la machine de Turing est assez technique et nécessite de rédiger quelques dizaines de pages. Donc nous nous limiterons à la démonstration de deux mécanismes : branchement et boucles.
Pour le branchement, nous avons montré ci-dessus que le terme mathbf{if} joue le rôle de même opérateur dans la programmation impérative. Ci-dessous, nous montrerons que la récursion est aussi possible en λ-calcul. Ce mécanisme va jouer le rôle des boucles qui n’existent pas dans ce système. De manière informelle, on comprend très bien que ces deux mécanismes suffisent pour écrire n’importe quel programme. De plus, la construction de récursion n’est pas quelque chose de simple.
Comme promis dans la première partie, nous montrons ci-dessous comment rédiger le programme qui calcule le factoriel de n en λ-calcul.
Calcul du factoriel : 1re approche
Listons d’abord les ingrédients dont nous aurons besoin pour calculer un factoriel :
- mathbf{1}, juste nombre 1 ;
- mathbf{mult} pour calculer un produit ;
- mathbf{pred} — rien à dire une fonction magique ;
- mathbf{isZero} — on a besoin de tester si l’argument est égal à mathbf{0} pour déterminer la terminaison de l’induction. Dans ce cas, mathbf{isZero} renvoie mathbf{tru}, sinon — mathbf{fls}. Nous ne prouvons pas son comportement, c’est un exercice assez simple si on connait le résultat :
Tous ces ingrédients permettent d’introduire un factoriel assez naturellement :
Rien de miraculeux ici : si x est égal à 0, on renvoie 1, sinon le produit de x et factoriel de x - 1. Si on remplace mathbf{fact} par sa définition, on obtient une série infinie de réductions. Houston, we have a problem…
Calcul “lazy”nt
Toutefois, vous estimez que pour calculer mathbf{fact ; bar{0}}, nous n’avons pas besoin de substitutions infinies car nous savons déjà que le troisième argument de mathbf{if} sera ignoré ? Vous avez raison ! Mais les règles du jeu ”Informatique théorique” imposent strictement d’utiliser des opérations bien précises : si on prétend que λ-calcul est un langage de programmation, alors on doit être capable de proposer un algorithme qui l’exécute et donc aucune ambiguïté ne peut être tolérée. Dans ce cas, on a « oublié » de fixer l’ordre de calcul. Considérons un terme mathbf{f} suivant :
Pour simplicité on peut le réécrire :
Ce terme-là contient 3 redexes (i.e., les paries d’expression à laquelle on peut appliquer la beta-réduction). Nous n’avons plusieurs choix de l’ordre des réductions :
- beta-réduction complète.
Le redex est choisi au hasard à chaque étape. Il est facile de voir que si l’expression initiale est finie, le résultat ne dépend pas de l’ordre de calcul (rappelons qu’il n’y a pas de notion d’état, donc aucun effet de bord n’est possible). Voici une des réductions possibles d’une expression ci-dessous :mathbf{f} = mathbf{id} ; (mathbf{id} ; (lambda z. ; underline{mathbf{id} ; z}))= ; mathbf{id} ; underline{(mathbf{id} ; (lambda z. ; z))}= ; underline{mathbf{id} ; (lambda z. ; z)}= ; lambda z. ; z - L’ordre normal.
À chaque étape on choisi un redex le plus gauche (c.-à.-d., le plus externe) :mathbf{f} = underline{mathbf{id} ; (mathbf{id} ; (lambda z. ; mathbf{id} ; z))}= ; underline{mathbf{id} ; (lambda z. ; mathbf{id} ; z)}= ; underline{lambda z. ; mathbf{id} ; z}= ; lambda z. ; z - L’appel par nom.
L’ordre de calcul est identique à l’ordre normal. En plus, on interdit les réductions à l’intérieur de l’abstraction. Dans cet exemple, on s’arrête sur l’avant-dernière étape :mathbf{f} = underline{mathbf{id} ; (mathbf{id} ; (lambda z. ; mathbf{id} ; z))}= ; underline{mathbf{id} ; (lambda z. ; mathbf{id} ; z)}= ; lambda z. ; mathbf{id} ; zUne version optimisée de cette stratégie est utilisée par Haskell par défaut. C’est le calcul « lazy ».
- L’appel par valeur.
On commence par un redex le plus à gauche (à l’extérieur) dans la partie droite duquel il y a une valeur — un terme clos qui ne peut plus être réduit :mathbf{f} = mathbf{id} ; underline{(mathbf{id} ; (lambda z. ; mathbf{id} ; z))}= ; underline{mathbf{id} (lambda z. ; mathbf{id} ; z)}= ; lambda z. ; mathbf{id} ; zCette stratégie est utilisée dans la plupart des langages de programmation : pour exécuter une fonction, on calcule d’abord tous ces arguments.
À noter : toutes les stratégies, excepté le calcul lazy, interdisent formellement la récursion. Le mécanisme de “lazyness” est réalisé exactement pour éviter les calculs non-nécessaires. En réalité, ce mécanisme est utilisé dans la plupart des langages, mais pas dans l’exécution de fonctions. Dans le code suivant : if a and b: ..., si a est déjà faux, il est probable que b ne sera jamais calculé, ce qui nous oblige à porter plus d’attention sur les effets de bord possibles.
Second approche : récursion et point fixe
Calcul « lazy » est une astuce puissante, mais notre objectif est de développer un langage le plus primitif possible, donc nous resterons sur beta-réduction complète comme l’ordre de calcul le moins contraignant. Considérons une fonction :
Cette fonction est très ressemblante à mathbf{fact}. La seule différence est que mathbf{fact'}, au lieu d’appliquer lui-même sur mathbf{pred} ; x, applique f qui est son paramètre. Donc, si on pose f := mathbf{fact}, notre fonction calcule le factoriel. Autrement dit, mathbf{fact'} ; mathbf{fact} = mathbf{fact}, c.-à-d., mathbf{fact} est un point fixe de mathbf{fact'}. Oups, il ne faut jamais utiliser un terme avant de le définir. On corrige vite.
Définition. Un point fixe de lambda-fonction mathbf{f} est une fonction mathbf{x} telle que
Imaginons, que nous avons une fonction mathbf{Y} magique qui, appliquée à un lambda-terme quelconque, renvoie son point fixe. Donc,
Il se trouve que telle fonction mathbf{Y} existe et elle n’est pas récursive. Donc nous avons une implémentation de mathbf{fact} qui n’est pas récursive et qui calcule le factoriel du x.
Combinateur de point fixe
La fonction magique mathbf{Y} dont nous avons parlé ci-dessus existe et s’appelle combinateur de point fixe. Ici, combinateur est un λ-terme sans type qui n’a pas des variables libres. En mathématique on formalise cette proposition de façon suivante :
Théorème. En λ-calcul (ainsi qu’en logique combinatoire), pour chaque terme mathbf{x} il existe au moins un terme mathbf{p} tel que mathbf{x} ; mathbf{p} = mathbf{p}. De plus, il existe un combinateur mathbf{Y} tel que
Preuve. Pour prouver ce théorème, construisons un combinateur :
Appliquons la réduction à l’expression soulignée :
On en déduit que mathbf{Y} ; f = f ; mathbf{Y} ; f. Donc mathbf{Y} ; f est un point fixe de f. Q.E.D.
Remarque. Cette formule-ci, a été introduite par Haskell Curry, mais il n’est pas unique. En réalité, il en existe un nombre infini. Par exemple, celui-ci a été proposé par Alan Turing :
Retour sur factoriel
Alors, nous prétendons qu’un terme suivant calcul le factoriel :
Cette « implémentation » n’est pas récursive. En revanche, le calcul devient très très le-e-e-ent : pour calculer 5 ! il faut faire 66066 beta-réductions – ne le faite surtout pas à la main !
Est-ce que vous êtes satisfaits par la preuve ? La réponse correcte est non ! Relisez-la encore une fois. Nous avons prouvé que mathbf{fact} est un point fixe de mathbf{fact'} et que mathbf{Y ; fact'} est un point fixe de mathbf{fact'}. Mais nous ne savons pas si mathbf{fact'} n’a qu’un seul point fixe. Donc cela n’implique pas que mathbf{fact = Y ; fact'}. Cependant il est vrai, mais la preuve formelle est plus compliquée : il s’agit d’appliquer l’expression ci-dessous sur un nombre de Church arbitraire mathbf{bar{n}} et de calculer correctement tous les lambdas cachés dans cette expression pour montrer que le résultat est égal à mathbf{overline{n!}} et il n’y a pas de récursion infinie. Une discussion plus profonde peut être trouvée dans les notes de cours de l’Université nationale australienne de Clem Baker-Finch.
Résumé
Cet article proposait une brève introduction au λ-calcul. À partir des primitifs que nous avons décrits, il est possible d’essayer de “programmer” un émulateur de machine de Turing. On peut alors constater que les constructions semblent longues et lourdes, mais, si on revient au début, la machine de Turing qui calcule un factoriel n’est pas plus simple.
Malheureusement, le système de λ-calcul sans type que l’on vient de construire subit des paradoxes comme un paradoxe de Kleene-Rosser (nous l’avons décrit dans l’introduction historique). Pour les corriger, Church a introduit le λ-calcul simplement typé qui est plus complexe que le système sur lequel nous avons travaillé, car, avec l’arrivée des types, les termes ne sont plus compatibles avec tout le monde. Pour consulter les bonnes sources, lisez les vrais livres de mathématiques ou les notes de cours correspondants — il me semble presque impossible d’adapter le contenu pour un article récréatif (même aussi long).
Pourquoi a-t-on besoin de savoir tout cela ? Plutôt pour « l’ouverture d’esprit ». Pour la même raison que l’on manipule la machine de Turing. Pour quelques heures de gymnastique du cerveau finalement. De plus, si vous parvenez à comprendre les manipulations d’arithmétique de Church, vous avez plus de facilité à comprendre les autres manipulations fonctionnelles et les principes de langage comme Haskell. Toutefois, les langages fonctionnels étant typés, je vous conseille vivement de jeter au moins un œil sur la théorie des types.
Finalement, on a pu constater que le λ-calcul est lent. C’est vrai. Mais les langages fonctionnels sont bien optimisés grâce au calcul « lazy » et au filtrage par motif, et ne sont donc pas plus lents que les langages impératifs (n’oubliez jamais que les véritables optimisations s’effectuent dans la couche intermédiaire incluse entre la chaise et l’écran…). Merci à l’ensemble des curieux dont l’intérêt est resté jusqu’au bout !
Références
- Henk Barendregt: The impact of the lambda calculus in logic and computer science. Bulletin of Symbolic Logic 3(2): 181-215 (1997)
- Henk Barendregt: Lambda Calculus. Its Syntaxin and Semantics. Studies in logic and the foundations of Mathematics, Rijksuniversiteit Utrecht, The Netherlands (1981)
- Felice Cardone, Hindley 1. Roger: History of Lambdacalculus and Combinatory Logic. (2006)
- Peter Selinger: Lecture Notes on the Lambda Calculus
- Clem Baker-Finch: Notes de cours de l’Université nationale australienne
- Notes de cours de l’université russe IFMO



Pas encore de commentaires